I am beginner to Spark and I am running my application to read 14KB data from text filed, do some transformations and actions(collect, collectAsMap) and save data to Database
I am running it locally in my macbook with 16G memory, with 8 logical cores.
Java Max heap is set at 12G.
Here is the command I use to run the application.
bin/spark-submit --class com.myapp.application --master local[*] --executor-memory 2G --driver-memory 4G /jars/application.jar
I am getting the following warning
2017-01-13 16:57:31.579 [Executor task launch worker-8hread] WARN org.apache.spark.storage.MemoryStore - Not enough space to cache rdd_57_0 in memory! (computed 26.4 MB so far)
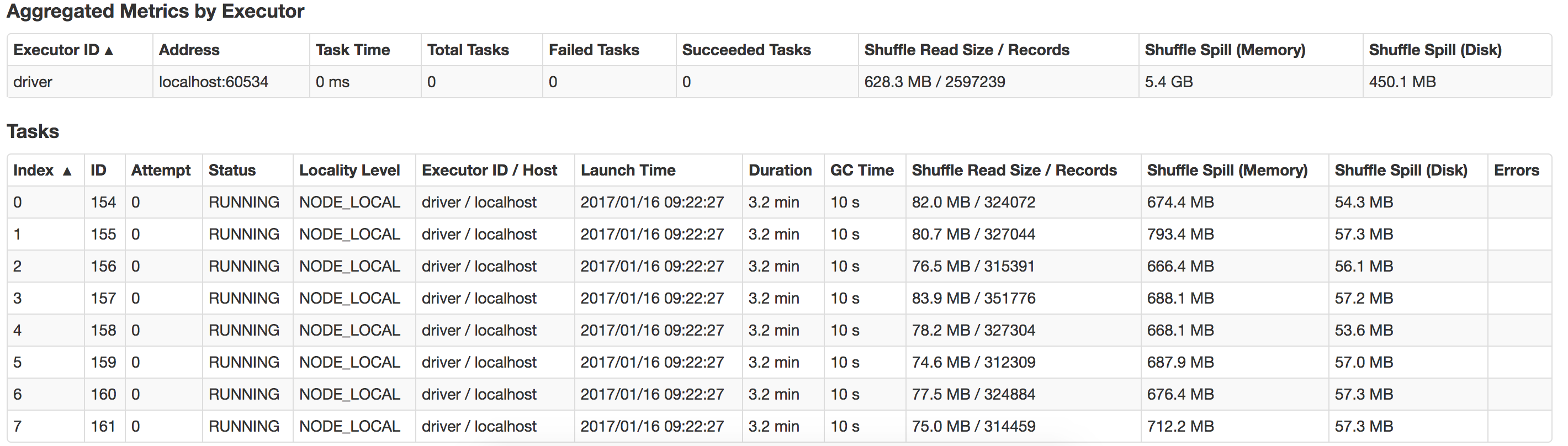
Can anyone guide me on what is going wrong here and how can I improve performance? Also how to optimize on suffle-spill ? Here is a view of the spill that happens in my local system
spark.executor.memoryhas no effect . so just try byspark.driver.memoryto more than 6g since you have 16g ram. – Halvah