Here's an example to clarify what I mean:
First session.run():
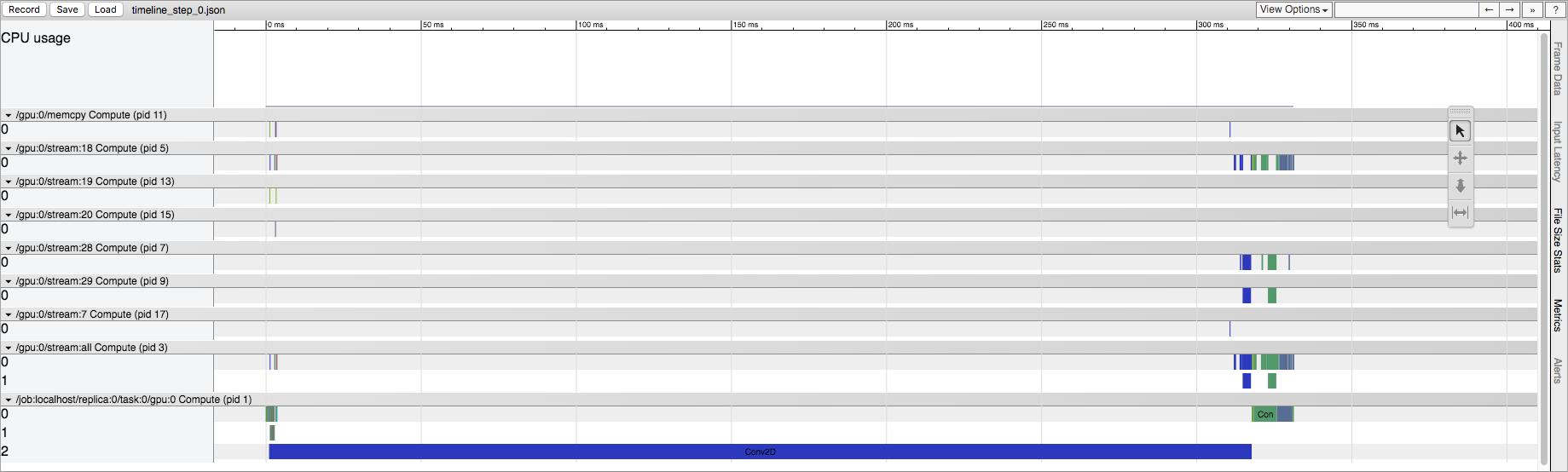
First run of a TensorFlow session
{kind=link}
Later session.run():
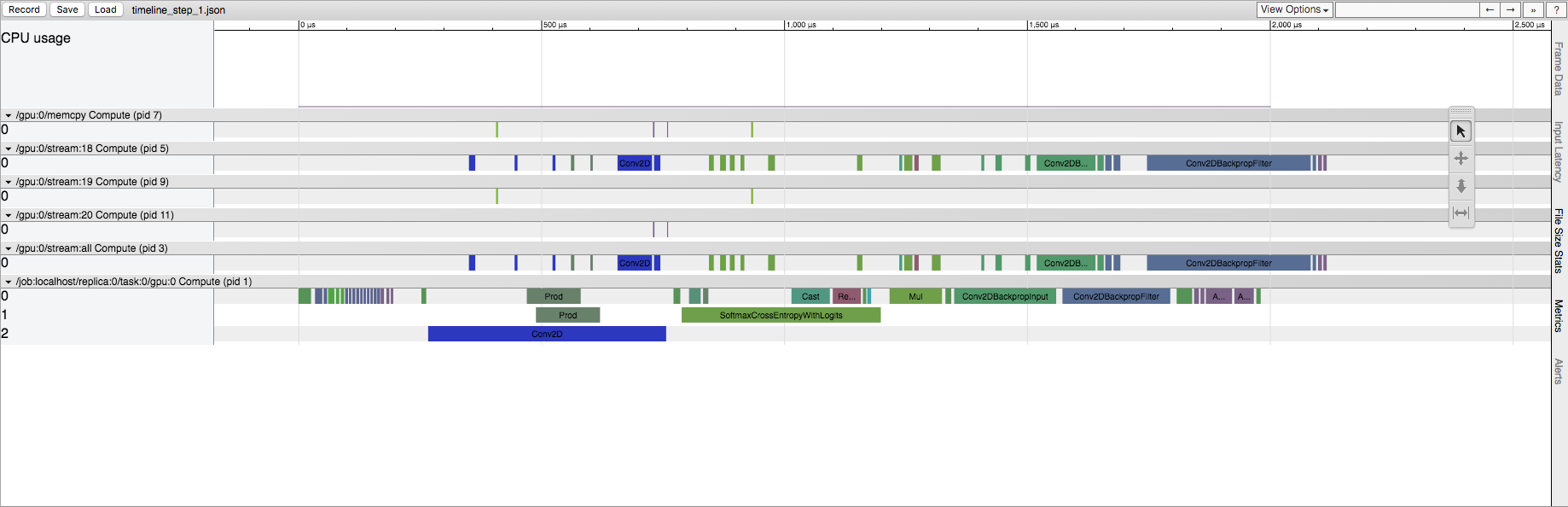
Later runs of a TensorFlow session
{kind=link}
I understand TensorFlow is doing some initialization here, but I'd like to know where in the source this manifests. This occurs on CPU as well as GPU, but the effect is more prominent on GPU. For example, in the case of a explicit Conv2D operation, the first run has a much larger quantity of Conv2D operations in the GPU stream. In fact, if I change the input size of the Conv2D, it can go from tens to hundreds of stream Conv2D operations. In later runs, however, there are always only five Conv2D operations in the GPU stream (regardless of input size). When running on CPU, we retain the same operation list in the first run compared to later runs, but we do see the same time discrepancy.
What portion of TensorFlow source is responsible for this behavior? Where are GPU operations "split?"
Thanks for the help!