I've encountered similar issues when working with 3d point clouds with models such as PointNet (CVPR'17). Therefore I've made a few more interpretations based on Yann Dubois's answers. We first define a few utility functions and then report our findings:
import torch, timeit, torch.nn as nn, matplotlib.pyplot as plt
def count_params(model):
"""Count the number of parameters in a module."""
return sum([p.numel() for p in model.parameters()])
def compare_params(linear, conv1d):
"""Compare whether two modules have identical parameters."""
return (linear.weight.detach().numpy() == conv1d.weight.detach().numpy().squeeze()).all() and \
(linear.bias.detach().numpy() == conv1d.bias.detach().numpy()).all()
def compare_tensors(out_linear, out_conv1d):
"""Compare whether two tensors are identical."""
return (out_linear.detach().numpy() == out_conv1d.permute(0, 2, 1).detach().numpy()).all()
- With the same input and parameters,
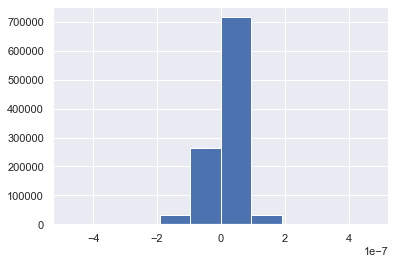
nn.Conv1d and nn.Linear are expected to produce same forward results arithmetically, but experiments show that there are different. We show this by plotting the histogram of the numerical differences. Note that this numerical difference will increase as the network goes deep.
conv1d, linear = nn.Conv1d(8, 32, 1), nn.Linear(8, 32)
# same input tensor
tensor = torch.randn(128, 256, 8)
permuted_tensor = tensor.permute(0, 2, 1).clone().contiguous()
# same weights and bias
linear.weight = nn.Parameter(conv1d.weight.squeeze(2))
linear.bias = nn.Parameter(conv1d.bias)
print(compare_params(linear, conv1d)) # True
# check on the forward tensor
out_linear = linear(tensor) # torch.Size([128, 256, 32])
out_conv1d = conv1d(permuted_tensor) # torch.Size([128, 32, 256])
print(compare_tensors(out_linear, out_conv1d)) # False
plt.hist((out_linear.detach().numpy() - out_conv1d.permute(0, 2, 1).detach().numpy()).ravel())
![Fig.1 Histogram of forward tensor between nn.Conv1d and nn.Linear]()
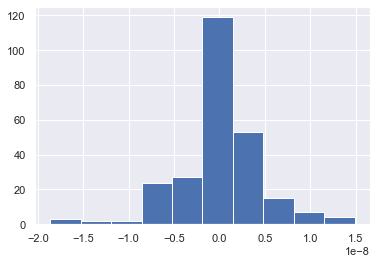
- Gradient updates in back propagation will also be numerically different.
target = torch.randn(out_linear.shape)
permuted_target = target.permute(0, 2, 1).clone().contiguous()
loss_linear = nn.MSELoss()(target, out_linear)
loss_linear.backward()
loss_conv1d = nn.MSELoss()(permuted_target, out_conv1d)
loss_conv1d.backward()
plt.hist((linear.weight.grad.detach().numpy() -
conv1d.weight.grad.permute(0, 2, 1).detach().numpy()).ravel())
![Fig.2 Histogram of backward tensor between nn.Conv1d and nn.Linear]()
- Computing Speed on GPU.
nn.Linear is a bit faster than nn.Conv1d
# test execution speed on CPUs
print(timeit.timeit("_ = linear(tensor)", number=10000, setup="from __main__ import tensor, linear"))
print(timeit.timeit("_ = conv1d(permuted_tensor)", number=10000, setup="from __main__ import conv1d, permuted_tensor"))
# change everything in *.cuda(), then test speed on GPUs
Conv1ddoes the same assuming the implementations are correct (eg to run the CNN along the right axis vs the Linear broadcasted layer you need to callinputs.transpose(1,2)), probably all comes down to theMaxPool1d– Brewing