I'm extracting some table from PDF with the help of Tabulizer in R. Below is the code for one of the table
library(tabulizer)
location <- "http://napic.jpph.gov.my/portal/web/guest/main-page?
p_p_id=ViewPublishings_WAR_ViewPublishingsportlet&
p_p_lifecycle=2&
p_p_state=normal&
p_p_mode=view&
p_p_resource_id=fileDownload&
p_p_cacheability=cacheLevelPage&
p_p_col_id=column-2&
p_p_col_pos=1&
p_p_col_count=2&
_ViewPublishings_WAR_ViewPublishingsportlet_publishingId=433&
_ViewPublishings_WAR_ViewPublishingsportlet_action=renderReportPeriodScreen&
_ViewPublishings_WAR_ViewPublishingsportlet_language=&
_ViewPublishings_WAR_ViewPublishingsportlet_pageno=1&
publishingId=4537"
out <- extract_tables(location, page=3)
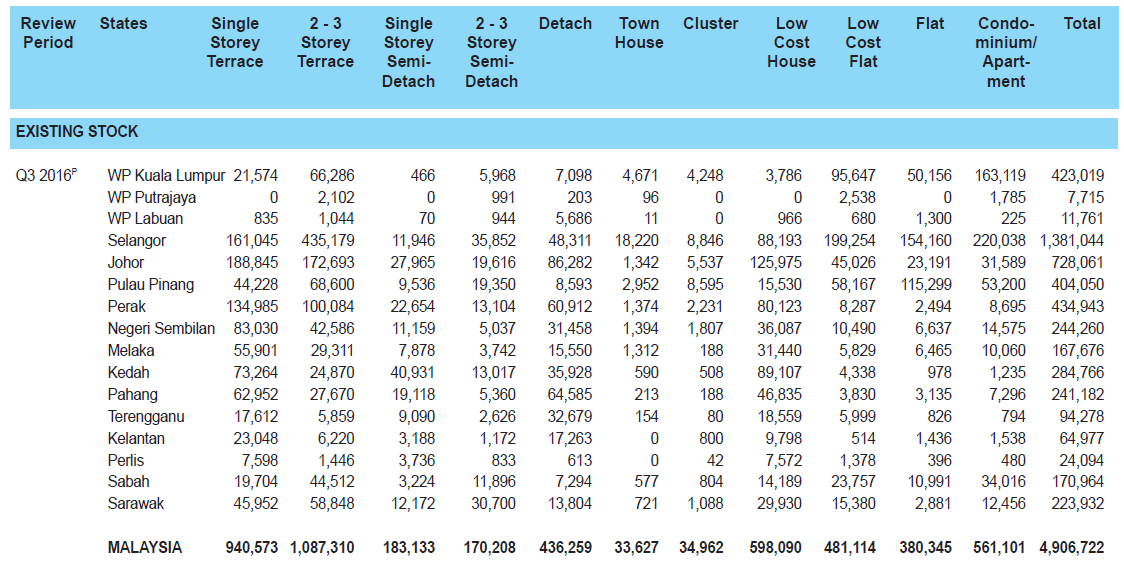
The output of the extracted table has a few quirks, for example it's split into 2 and some data are not properly delimited.
[[1]]
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
[1,] " Review " "States " "Single " "2 - 3 " "Single " "2 - 3 " "Detach " "Town " "Cluster " "Low " "Low " "Flat " "Condo- " "Total"
[2,] "Period " "" "Storey " "Storey " "Storey " "Storey " "" "House " "" "Cost " "Cost " "" "minium/" ""
[3,] "" "" "Terrace " "Terrace " "Semi- " "Semi- " "" "" "" "House " "Flat " "" "Apart-" ""
[4,] "" "" "" "" "Detach " "Detach " "" "" "" "" "" "" "ment" ""
[[2]]
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13]
[1,] "EXISTING STOCK " "" "" "" "" "" "" "" "" "" "" "" ""
[2,] "" "" "" "" "" "" "" "" "" "" "" "" ""
[3,] "Q3 2016P WP Kuala Lumpur 21,574 " "" "66,286 " "466 " "5,968 " "7,098 " "4,671 " "4,248 " "3,786 " "95,647 " "50,156 " "163,119 " "423,019"
[4,] "WP Putrajaya 0 " "" "2,102 " "0 " "991 " "203 " "96 " "0 " "0 " "2,538 " "0 " "1,785 " "7,715"
[5,] "WP Labuan 835 " "" "1,044 " "70 " "944 " "5,686 " "11 " "0 " "966 " "680 " "1,300 " "225 " "11,761"
The desired output I'm looking for should be close to the original table:
I'm stumped at the moment, appreciate if anyone can point me to the right direction. Thanks in advance.