I am using YOLOv3 to detect cars in videos. I downloaded three files used in my code coco.names, yolov3.cfg and yolov3.weights which are trained for 80 different classes of objects to be detected. The code worked but very slowly, it takes more than 5 seconds for each frame. I believe that if I reduced the number of classes, it would run much faster. I can delete the unnecessary classes from coco.names, but unfortunately, I don't understand all the contents from yolov3.cfg, and I can't even read yolov3.weights.
I was thinking about training my own model, but I faced a lot of problems, so I gave up the idea.
Can anyone help me in modifying these files?
How to reduce number of classes in YOLOv3 files?
Asked Answered
the number of classes does not have much impact on the processing time of yolo. In theory, with less classes you would not need so big feature maps, but you would have to train your own network. Reducing weights of a given network is called pruning, but has some limitations. –
Croom
I would like to try, but I don't want to reinvent the wheel. –
Saragossa
just remove the links between each last yolo layer and the output layer for all the class IDs you don't want to keep. –
Croom
For easy and simple way using COCO dataset, follow these steps :
- Modify (or copy for backup) the
coco.namesfile indarknet\data\coco.names - Delete all other classes except car
- Modify your cfg file (e.g.
yolov3.cfg), change the 3 classes on line 610, 696, 783 from 80 to 1 - Change the 3 filters in cfg file on line 603, 689, 776 from 255 to 18 (derived from
(classes+5)x3) - Run the detector
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/your_image.jpg
For more advance way using COCO dataset you can use this repo to create yolo datasets based on voc, coco or open images. https://github.com/holger-prause/yolo_utils .
Also refer to this : How can I download a specific part of Coco Dataset?
Would be great if you can train YOLO model using your own dataset. There are so many tutorial on the internet of how to build your own dataset. Like this, this, this or this.
Note : reducing number of classes won't make your inference speed faster. By reducing classes, you will detect less object and somehow will probably make your program run faster if you do post-processing for each detection.
Thank you very much. This helped me a lot. I also used this github.com/AlexeyAB/darknet in building my database. It was easier than others. I recommend you to add it to the solution. –
Saragossa
...!? Modifying the .names file and then altering the filters so Darknet doesn't complain when it loads doesn't change the neural network! The 80 MSCOCO classes are still there, you're simply not allowing Darknet to display the names! Same way that removing 2 tires from your car doesn't turn it into a motorcycle. –
Preachment
@Stéphane yes you are right, but this is a shortcut that he needs. He asked to modify the files without training his own model. If you want the neural network works as you said, then he needs to train his own model –
Maggs
@gameon67 but 1) it doesn't work, and 2) it can cause Darknet to segfault. Doesn't matter if he needs a shortcut, this isn't a valid way to do it. –
Preachment
@gameon67, What strategy would you take to specialize a Yolo model on a single class of the COCO. For instance, just
person. I want to do transfer learning yet on the other side the head should support only a single class. –
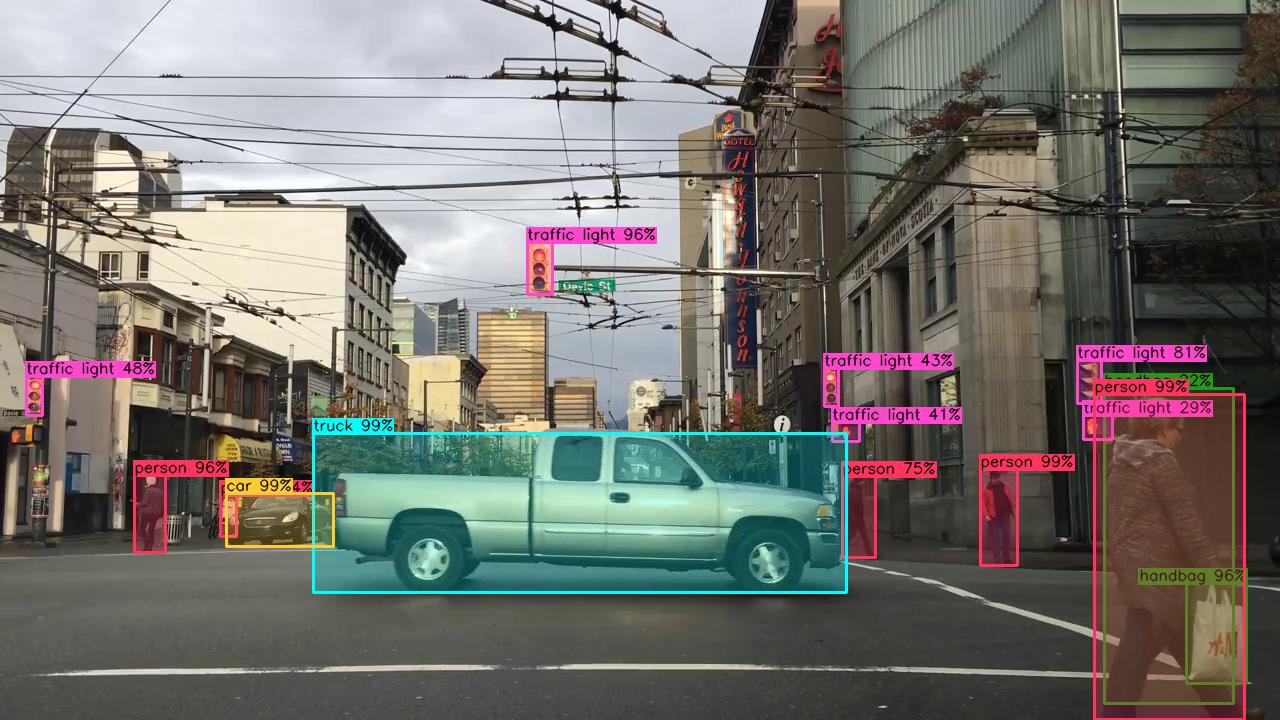
Fencing I had to come back here to better explain why I left the comment I did on the other answer. Just so people can visually see exactly why that solution doesn't work.
Here is an example of the default MSCOCO weights on an image taken of a downtown city streetcorner. There is a total of 15 objects found by the full YOLOv4 neural network within this image, one of which is incorrect (handbag 22%), the rest of which are pretty good predictions:
-> prediction results: 15
-> 1/15: "handbag 22%" #26 prob=0.218514 x=1104 y=388 w=130 h=316 tile=0 entries=1
-> 2/15: "person 24%" #0 prob=0.241557 x=220 y=495 w=17 h=42 tile=0 entries=1
-> 3/15: "traffic light 29%" #9 prob=0.287092 x=1083 y=415 w=30 h=25 tile=0 entries=1
-> 4/15: "traffic light 41%" #9 prob=0.411164 x=832 y=422 w=28 h=20 tile=0 entries=1
-> 5/15: "traffic light 43%" #9 prob=0.428222 x=824 y=368 w=15 h=39 tile=0 entries=1
-> 6/15: "traffic light 48%" #9 prob=0.476035 x=26 y=376 w=17 h=40 tile=0 entries=1
-> 7/15: "person 75%" #0 prob=0.754457 x=842 y=476 w=34 h=82 tile=0 entries=1
-> 8/15: "traffic light 81%" #9 prob=0.80667 x=1077 y=360 w=25 h=44 tile=0 entries=1
-> 9/15: "handbag 96%" #26 prob=0.9597 x=1186 y=583 w=61 h=101 tile=0 entries=1
-> 10/15: "person 96%" #0 prob=0.963756 x=134 y=475 w=32 h=78 tile=0 entries=1
-> 11/15: "traffic light 96%" #9 prob=0.964594 x=527 y=242 w=26 h=53 tile=0 entries=1
-> 12/15: "truck 99%" #7 prob=0.988193 x=313 y=433 w=534 h=160 tile=0 entries=1
-> 13/15: "car 99%" #2 prob=0.989198 x=226 y=493 w=108 h=54 tile=0 entries=1
-> 14/15: "person 99%" #0 prob=0.990569 x=1094 y=394 w=151 h=326 tile=0 entries=1
-> 15/15: "person 99%" #0 prob=0.993613 x=980 y=469 w=38 h=97 tile=0 entries=1
Let's pretend we only want car (index #3) and truck (index #8). So now my .names file looks like this:
car
truck
All other 78 names were deleted. Note at this point, you're assuming that Darknet (or YOLO?) has a magical way to map the two new classes at index #0 and index #1 to their original position at index #3 and #8. But let's gloss over that problem for the moment as if there was a way for that to work.
I fix up my .cfg file to indicate I now have only 2 classes instead of 80, and I modify the filters before [yolo] from 255 to 21.
Now when I run detection against the same image, I get nothing:
-> prediction results: 0

The fact that it runs at all is pure luck! The internals of the weights no longer matches the configuration. That configuration determines how the weights are interpreted, and you've modified one without altering the other. Truth be told, I'm actually surprised that it does not segfault as I suspect that this causes Darknet to run into some "undefined behaviour" territory.
To go back to the original question, note that the number of classes increases the length of time it takes to train the neural network, but does not impact the length of time it takes to apply that neural network.
Instead, if you're looking for performance, see the Darknet/YOLO FAQ. Specifically, this FAQ entry: https://www.ccoderun.ca/programming/darknet_faq/#fps
In case the URL changes or goes away, let me post the relevant portion here:
How can I increase my FPS? This depends on several things:
- Probably the biggest impact on FPS is the configuration you use. See What configuration file should I use? at the top of this FAQ.
- The network dimensions. The larger the dimensions, the slower it will be. See Does the network have to be perfectly square? at the top of this FAQ.
- Whether your video frames or images need to be resized due to the network dimensions you are using. Resizing video frames is very expensive.
- The hardware you use. Don't attempt to use the CPU. Get a GPU that has CUDA support.
- Whether you are using Darknet+CUDA, or OpenCV DNN+CUDA.
- Prefer the C or C++ API over using Python. ("Statistically, C++ is 400 times faster than Python [...]")
The only real way to reduce the number of classes would be to train it that way. So you either train your own neural network, or you download the MSCOCO dataset, modify the .names file, edit all of the annotations to remove the classes you want, renumber all of the classes so they are sequential and start at index zero, and retrain the entire network.
Disclaimer: I'm the author of DarkHelp, DarkMark, and the Darknet/YOLO FAQ.
© 2022 - 2025 — McMap. All rights reserved.