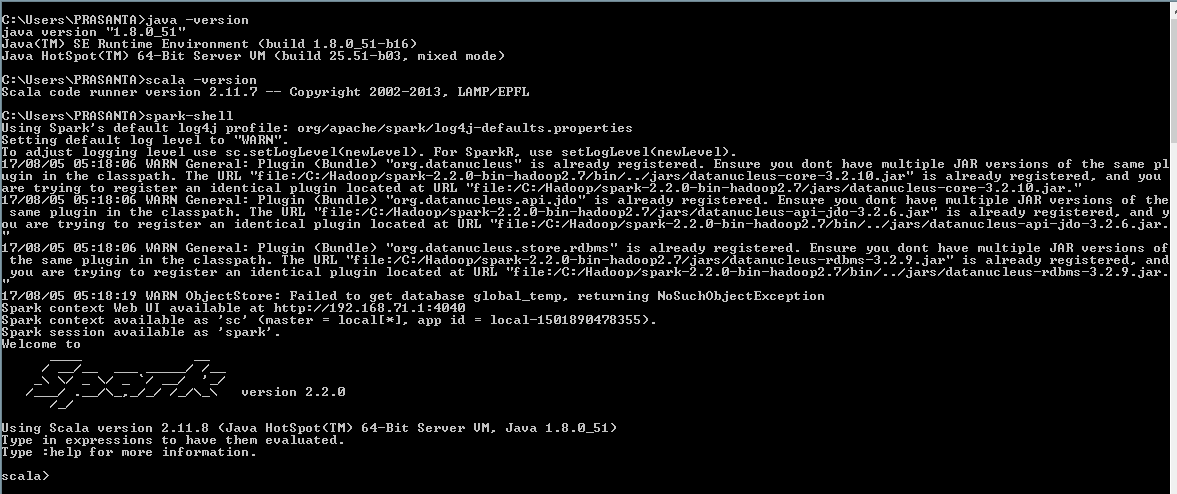
I install spark on windows, but it failed to run showing the error below:
<console>:16: error: not found: value sqlContext
import sqlContext.implicits._
^
<console>:16: error: not found: value sqlContext
import sqlContext.sql
^
I tried the links below but any one of them resolves the issue: How to start Spark applications on Windows (aka Why Spark fails with NullPointerException)?
Apache Spark error while start
error when starting the spark shell
error: not found: value sqlContext
The complete log of spark execution is below:
D:\Spark\spark-1.6.1-bin-hadoop2.6\bin>spark-shell
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.1
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) Client VM, Java 1.8.0_77)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
16/04/19 16:28:10 WARN General: Plugin (Bundle) "org.datanucleus.api.jdo" is already registered. Ensure you dont have mul
tiple JAR versions of the same plugin in the classpath. The URL "file:/D:/Spark/spark-1.6.1-bin-hadoop2.6/lib/datanucleus
-api-jdo-3.2.6.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/D:/Sp
ark/spark-1.6.1-bin-hadoop2.6/bin/../lib/datanucleus-api-jdo-3.2.6.jar."
16/04/19 16:28:10 WARN General: Plugin (Bundle) "org.datanucleus" is already registered. Ensure you dont have multiple JA
R versions of the same plugin in the classpath. The URL "file:/D:/Spark/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-core-3.
2.10.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/D:/Spark/spark-
1.6.1-bin-hadoop2.6/bin/../lib/datanucleus-core-3.2.10.jar."
16/04/19 16:28:10 WARN General: Plugin (Bundle) "org.datanucleus.store.rdbms" is already registered. Ensure you dont have
multiple JAR versions of the same plugin in the classpath. The URL "file:/D:/Spark/spark-1.6.1-bin-hadoop2.6/bin/../lib/
datanucleus-rdbms-3.2.9.jar" is already registered, and you are trying to register an identical plugin located at URL "fi
le:/D:/Spark/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar."
16/04/19 16:28:11 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/04/19 16:28:11 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/04/19 16:28:24 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not
enabled so recording the schema version 1.2.0
16/04/19 16:28:24 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
java.lang.RuntimeException: java.lang.NullPointerException
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)
at org.apache.spark.sql.hive.client.ClientWrapper.<init>(ClientWrapper.scala:204)
at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:238)
at org.apache.spark.sql.hive.HiveContext.executionHive$lzycompute(HiveContext.scala:218)
at org.apache.spark.sql.hive.HiveContext.executionHive(HiveContext.scala:208)
at org.apache.spark.sql.hive.HiveContext.functionRegistry$lzycompute(HiveContext.scala:462)
at org.apache.spark.sql.hive.HiveContext.functionRegistry(HiveContext.scala:461)
at org.apache.spark.sql.UDFRegistration.<init>(UDFRegistration.scala:40)
at org.apache.spark.sql.SQLContext.<init>(SQLContext.scala:330)
at org.apache.spark.sql.hive.HiveContext.<init>(HiveContext.scala:90)
at org.apache.spark.sql.hive.HiveContext.<init>(HiveContext.scala:101)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Unknown Source)
at org.apache.spark.repl.SparkILoop.createSQLContext(SparkILoop.scala:1028)
at $iwC$$iwC.<init>(<console>:15)
at $iwC.<init>(<console>:24)
at <init>(<console>:26)
at .<init>(<console>:30)
at .<clinit>(<console>)
at .<init>(<console>:7)
at .<clinit>(<console>)
at $print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:1065)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:1346)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$1(SparkIMain.scala:840)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:871)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:819)
at org.apache.spark.repl.SparkILoop.reallyInterpret$1(SparkILoop.scala:857)
at org.apache.spark.repl.SparkILoop.interpretStartingWith(SparkILoop.scala:902)
at org.apache.spark.repl.SparkILoop.command(SparkILoop.scala:814)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$1.apply(SparkILoopInit.scala:132)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$1.apply(SparkILoopInit.scala:124)
at org.apache.spark.repl.SparkIMain.beQuietDuring(SparkIMain.scala:324)
at org.apache.spark.repl.SparkILoopInit$class.initializeSpark(SparkILoopInit.scala:124)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:64)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$1$$anonfun$apply$mcZ$sp$5.
apply$mcV$sp(SparkILoop.scala:974)
at org.apache.spark.repl.SparkILoopInit$class.runThunks(SparkILoopInit.scala:159)
at org.apache.spark.repl.SparkILoop.runThunks(SparkILoop.scala:64)
at org.apache.spark.repl.SparkILoopInit$class.postInitialization(SparkILoopInit.scala:108)
at org.apache.spark.repl.SparkILoop.postInitialization(SparkILoop.scala:64)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$1.apply$mcZ$sp(SparkILoop.
scala:991)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$1.apply(SparkILoop.scala:9
45)
at org.apache.spark.repl.SparkILoop$$anonfun$org$apache$spark$repl$SparkILoop$$process$1.apply(SparkILoop.scala:9
45)
at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:135)
at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$$process(SparkILoop.scala:945)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:1059)
at org.apache.spark.repl.Main$.main(Main.scala:31)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.NullPointerException
at java.lang.ProcessBuilder.start(Unknown Source)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:808)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:791)
at org.apache.hadoop.fs.FileUtil.execCommand(FileUtil.java:1097)
at org.apache.hadoop.fs.RawLocalFileSystem$DeprecatedRawLocalFileStatus.loadPermissionInfo(RawLocalFileSystem.jav
a:582)
at org.apache.hadoop.fs.RawLocalFileSystem$DeprecatedRawLocalFileStatus.getPermission(RawLocalFileSystem.java:557
)
at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(SessionState.java:599)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:554)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:508)
... 62 more
<console>:16: error: not found: value sqlContext
import sqlContext.implicits._
^
<console>:16: error: not found: value sqlContext
import sqlContext.sql
^
scala>
{kind=link}