I am trying implement hierarchical clustering in R : hclust() ; this requires a distance matrix created by dist() but my dataset has around a million rows, and even EC2 instances run out of RAM. Is there a workaround?
hclust() in R on large datasets
One possible solution for this is to sample your data, cluster the smaller sample, then treat the clustered sample as training data for k Nearest Neighbors and "classify" the rest of the data. Here is a quick example with 1.1M rows. I use a sample of 5000 points. The original data is not well-separated, but with only 1/220 of the data, the sample is separated. Since your question referred to hclust, I used that. But you could use other clustering algorithms like dbscan or mean shift.
## Generate data
set.seed(2017)
x = c(rnorm(250000, 0,0.9), rnorm(350000, 4,1), rnorm(500000, -5,1.1))
y = c(rnorm(250000, 0,0.9), rnorm(350000, 5.5,1), rnorm(500000, 5,1.1))
XY = data.frame(x,y)
Sample5K = sample(length(x), 5000) ## Downsample
## Cluster the sample
DM5K = dist(XY[Sample5K,])
HC5K = hclust(DM5K, method="single")
Groups = cutree(HC5K, 8)
Groups[Groups>4] = 4
plot(XY[Sample5K,], pch=20, col=rainbow(4, alpha=c(0.2,0.2,0.2,1))[Groups])
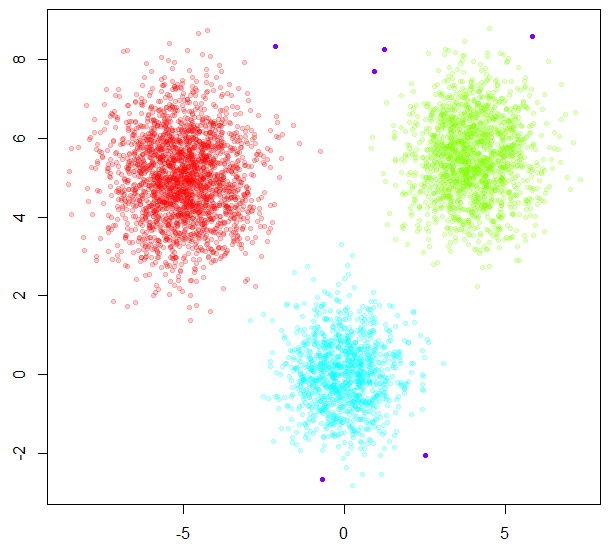
Now just assign all other points to the nearest cluster.
Core = which(Groups<4)
library(class)
knnClust = knn(XY[Sample5K[Core], ], XY, Groups[Core])
plot(XY, pch=20, col=rainbow(3, alpha=0.1)[knnClust])
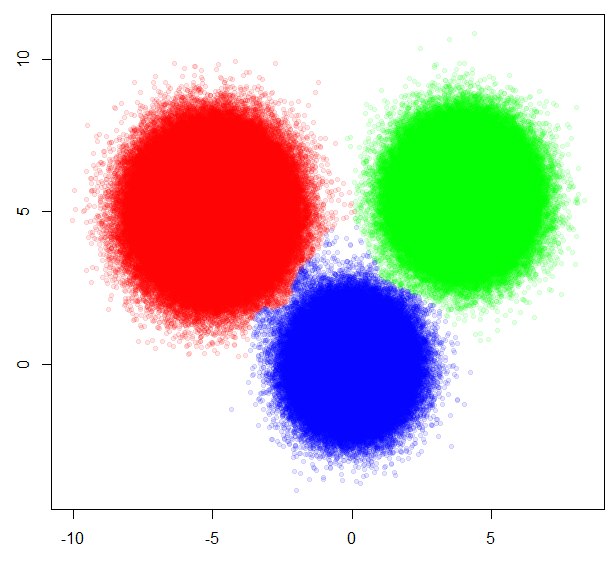
A few quick notes.
- Because I created the data, I knew to choose three clusters. With a real problem, you would have to do the work of figuring out an appropriate number of clusters.
- Sampling 1/220 could completely miss any small clusters. In the small sample, they would just look like noise.
This clusters the data, it doesn't do hierarchical clustering. Normal clustering just divides things into a set number of groups, hierarchical clustering makes a "family tree" for all the data, assigning each individual data point a specific place in the tree. –
Aftermath
@Aftermath - yes. I agree. It is not hierarchical clustering on the full data. –
Navvy
The end results isn't hierarchical clustering at all (or at best it is a hierarchy of 3), you threw out all of the relationships between the groups when you cut the tree and just used the top 3 clusters for your classifier. You could get a sort of semi hierarchy if you kept all of you 5000 groups from
hclust and assigned the rest of the data to each of the 5000 branches. You could then make a real hierarchy (though with some potential errors) if you then ran hclust on each of the groups and then hooked them back up into the tree. –
Aftermath © 2022 - 2024 — McMap. All rights reserved.
Rclusterpppackage for a hierarchical clustering algorythm that is more efficient. – Aftermath