This graph trains a simple signal identity encoder, and in fact shows that the weights are being evolved by the optimizer:
import tensorflow as tf
import numpy as np
initia = tf.random_normal_initializer(0, 1e-3)
DEPTH_1 = 16
OUT_DEPTH = 1
I = tf.placeholder(tf.float32, shape=[None,1], name='I') # input
W = tf.get_variable('W', shape=[1,DEPTH_1], initializer=initia, dtype=tf.float32, trainable=True) # weights
b = tf.get_variable('b', shape=[DEPTH_1], initializer=initia, dtype=tf.float32, trainable=True) # biases
O = tf.nn.relu(tf.matmul(I, W) + b, name='O') # activation / output
#W1 = tf.get_variable('W1', shape=[DEPTH_1,DEPTH_1], initializer=initia, dtype=tf.float32) # weights
#b1 = tf.get_variable('b1', shape=[DEPTH_1], initializer=initia, dtype=tf.float32) # biases
#O1 = tf.nn.relu(tf.matmul(O, W1) + b1, name='O1')
W2 = tf.get_variable('W2', shape=[DEPTH_1,OUT_DEPTH], initializer=initia, dtype=tf.float32) # weights
b2 = tf.get_variable('b2', shape=[OUT_DEPTH], initializer=initia, dtype=tf.float32) # biases
O2 = tf.matmul(O, W2) + b2
O2_0 = tf.gather_nd(O2, [[0,0]])
estimate0 = 2.0*O2_0
eval_inp = tf.gather_nd(I,[[0,0]])
k = 1e-5
L = 5.0
distance = tf.reduce_sum( tf.square( eval_inp - estimate0 ) )
opt = tf.train.GradientDescentOptimizer(1e-3)
grads_and_vars = opt.compute_gradients(distance, [W, b, #W1, b1,
W2, b2])
clipped_grads_and_vars = [(tf.clip_by_value(g, -4.5, 4.5), v) for g, v in grads_and_vars]
train_op = opt.apply_gradients(clipped_grads_and_vars)
saver = tf.train.Saver()
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
for i in range(10000):
print sess.run([train_op, I, W, distance], feed_dict={ I: 2.0*np.random.rand(1,1) - 1.0})
for i in range(10):
print sess.run([eval_inp, W, estimate0], feed_dict={ I: 2.0*np.random.rand(1,1) - 1.0})
However, when I uncomment the intermediate hidden layer and train the resulting network, I see that the weights are not evolving anymore:
import tensorflow as tf
import numpy as np
initia = tf.random_normal_initializer(0, 1e-3)
DEPTH_1 = 16
OUT_DEPTH = 1
I = tf.placeholder(tf.float32, shape=[None,1], name='I') # input
W = tf.get_variable('W', shape=[1,DEPTH_1], initializer=initia, dtype=tf.float32, trainable=True) # weights
b = tf.get_variable('b', shape=[DEPTH_1], initializer=initia, dtype=tf.float32, trainable=True) # biases
O = tf.nn.relu(tf.matmul(I, W) + b, name='O') # activation / output
W1 = tf.get_variable('W1', shape=[DEPTH_1,DEPTH_1], initializer=initia, dtype=tf.float32) # weights
b1 = tf.get_variable('b1', shape=[DEPTH_1], initializer=initia, dtype=tf.float32) # biases
O1 = tf.nn.relu(tf.matmul(O, W1) + b1, name='O1')
W2 = tf.get_variable('W2', shape=[DEPTH_1,OUT_DEPTH], initializer=initia, dtype=tf.float32) # weights
b2 = tf.get_variable('b2', shape=[OUT_DEPTH], initializer=initia, dtype=tf.float32) # biases
O2 = tf.matmul(O1, W2) + b2
O2_0 = tf.gather_nd(O2, [[0,0]])
estimate0 = 2.0*O2_0
eval_inp = tf.gather_nd(I,[[0,0]])
distance = tf.reduce_sum( tf.square( eval_inp - estimate0 ) )
opt = tf.train.GradientDescentOptimizer(1e-3)
grads_and_vars = opt.compute_gradients(distance, [W, b, W1, b1,
W2, b2])
clipped_grads_and_vars = [(tf.clip_by_value(g, -4.5, 4.5), v) for g, v in grads_and_vars]
train_op = opt.apply_gradients(clipped_grads_and_vars)
saver = tf.train.Saver()
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
for i in range(10000):
print sess.run([train_op, I, W, distance], feed_dict={ I: 2.0*np.random.rand(1,1) - 1.0})
for i in range(10):
print sess.run([eval_inp, W, estimate0], feed_dict={ I: 2.0*np.random.rand(1,1) - 1.0})
The evaluation of estimate0 converging quickly in some fixed value that becomes independient from the input signal. I have no idea why this is happening
Question:
Any idea what might be wrong with the second example?
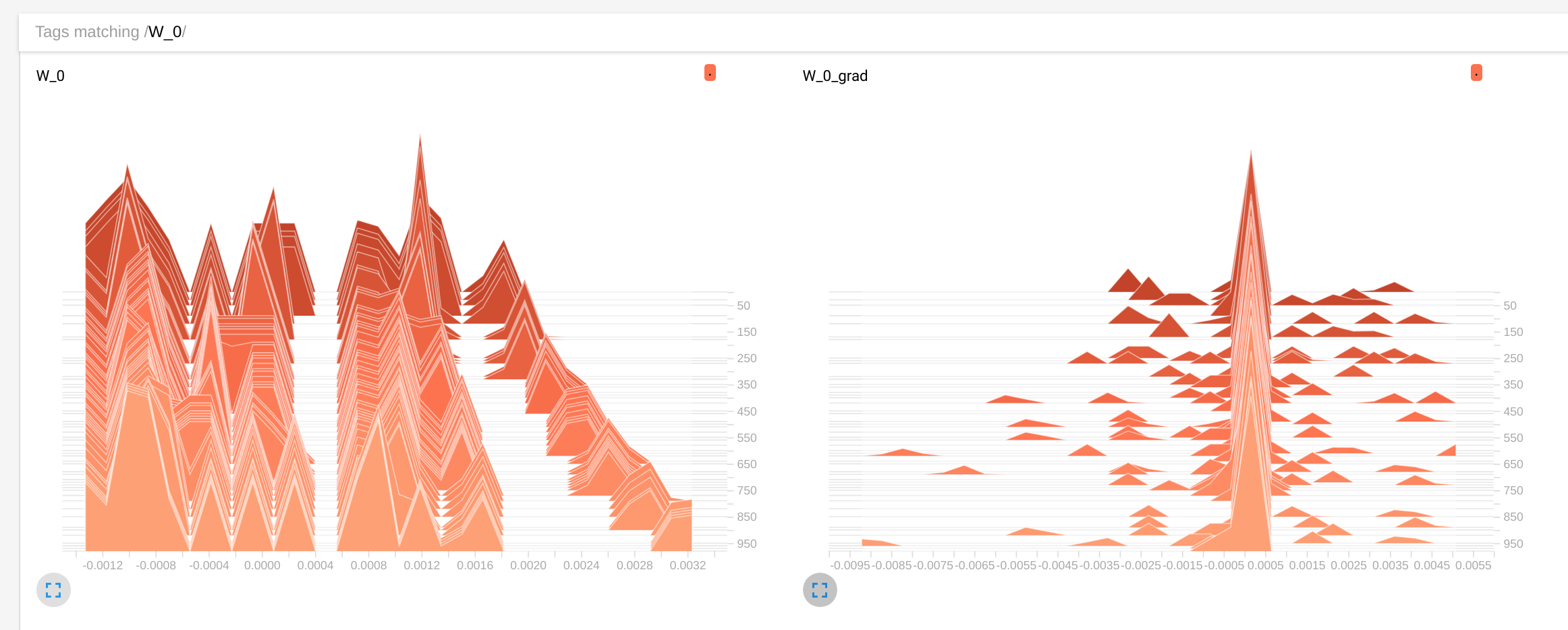
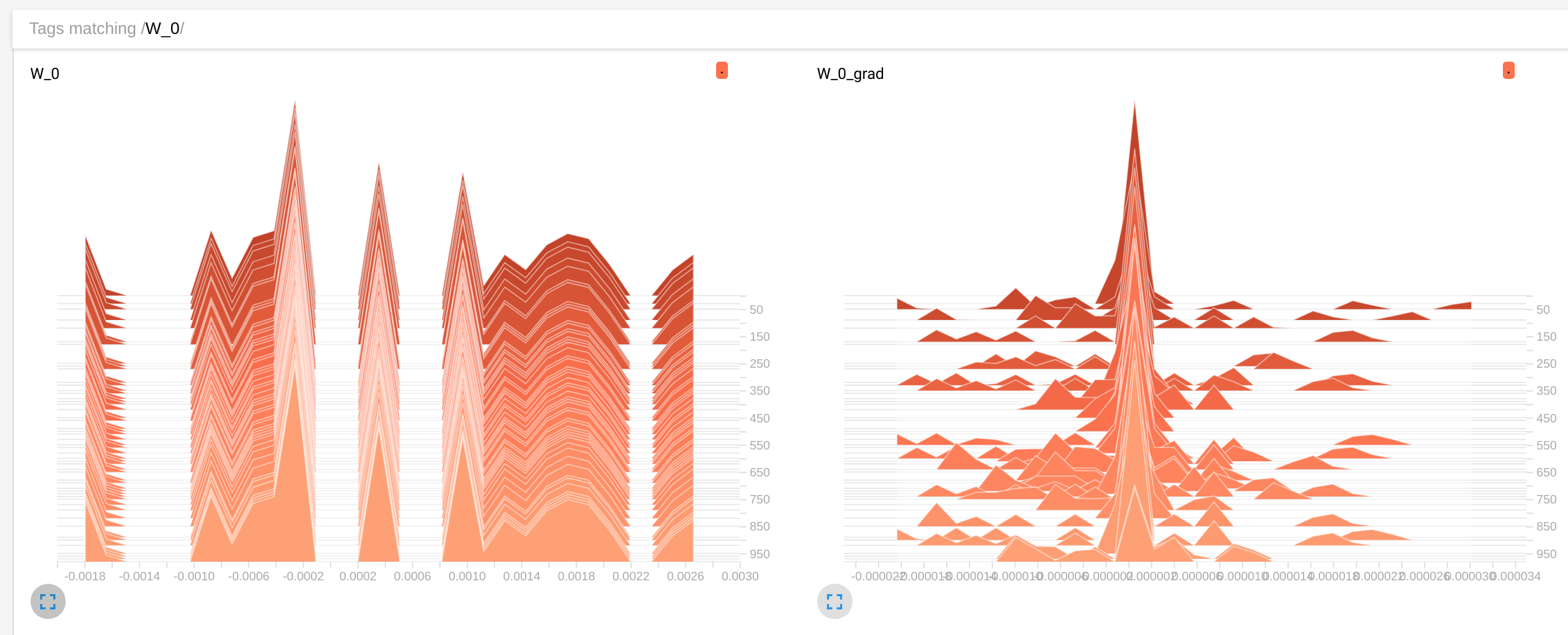
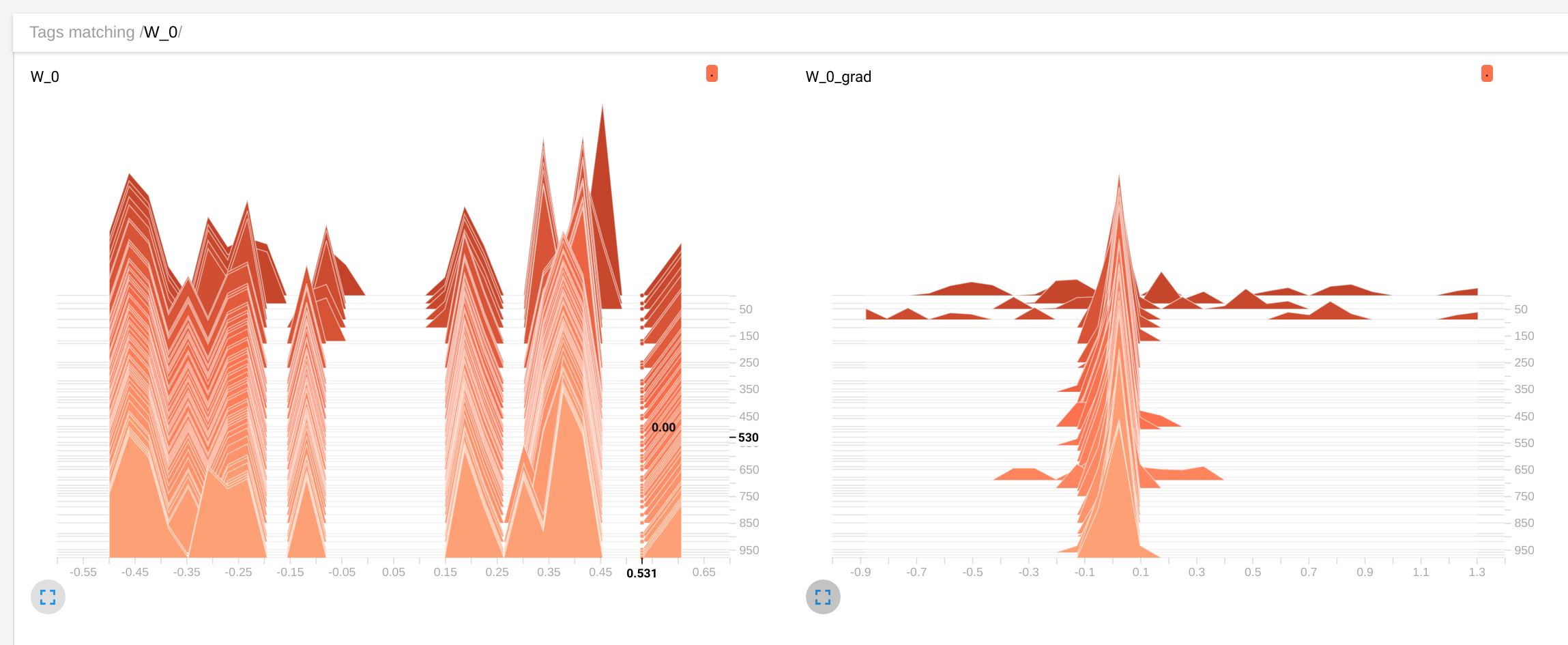
Wvalues barely change,distancedoes not get smaller and in the inference loopestimate0barely changes value with different inputs. In first exampleWchange,distancebecome of the order of 1e-5 in a hundred steps andestimate0closely tracks the input value – Disputant