I am learning the Transformer. Here is the pytorch document for MultiheadAttention. In their implementation, I saw there is a constraint:
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
Why require the constraint: embed_dim must be divisible by num_heads? If we go back to the equation
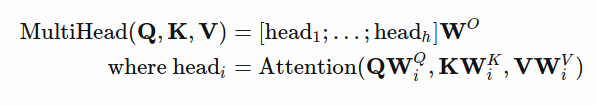
Assume:
Q, K,V are n x emded_dim matrices; all the weight matrices W is emded_dim x head_dim,
Then, the concat [head_i, ..., head_h] will be a n x (num_heads*head_dim) matrix;
W^O with size (num_heads*head_dim) x embed_dim
[head_i, ..., head_h] * W^O will become a n x embed_dim output
I don't know why we require embed_dim must be divisible by num_heads.
Let say we have num_heads=10000, the resuts are the same, since the matrix-matrix product will absort this information.

seq_len x emb_dimis20 x 9, andnum_heads=2, let choosehead_dim=77, then we can get thehead_iis a20 x 144matrix. as such[head_1, head_2]is20 x 288, We can still choseW^Ois288 x 9. we can still get the final20 x 9. My point is that we can also mapemb_diminto any lenght, and useW^Oto project it back toemb_dim. Why need to diveemb_diminto even length? Thanks. – Yardage