I am running k-means clustering on a dataset with around 1 million items and around 100 attributes. I applied clustering for various k, and I want to evaluate the different groupings with the silhouette score from sklearn library. Running it with no sampling seems unfeasible and takes a prohibitively long time. So, I assume I need to use sampling, i.e.:
metrics.silhouette_score(feature_matrix, cluster_labels, metric='euclidean',sample_size=???)
I don't have a good sense of what an appropriate sampling approach is. Is there a rule of thumb for ideal sample size to use given the size of my matrix? And is it better to take the largest sample size that my analysis machine can handle? Or should I take the average of smaller samples?
My preliminary test with sample_size=10000 has produced some unintuitive results.
I am open for alternative and more scalable evaluation metrics.
Editing to visualize the issue:
The plot shows the silhouette score against the number of clusters. 
In my opinion, increasing sample size is reducing the noise is a normal behavior. But given that I have 1 million, a heterogenous vector, 2 or 3 clusters is the "best" number of clusters seems unintuitive. In other words, I would expect to find a monotonic decreases in silhouette score as I increase the number of clusters.
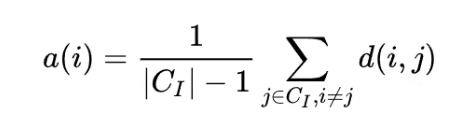
sklearn.metrics.silhouette_scoredecreased monotonically, and I don't figure out why this happened – Shontashoosilhouette scorewithSDbw, which was demonstrated to be the most robust index in this paper – Shontashoo