When should you use generator expressions and when should you use list comprehensions in Python?
# Generator expression
(x*2 for x in range(256))
# List comprehension
[x*2 for x in range(256)]
When should you use generator expressions and when should you use list comprehensions in Python?
# Generator expression
(x*2 for x in range(256))
# List comprehension
[x*2 for x in range(256)]
John's answer is good (that list comprehensions are better when you want to iterate over something multiple times). However, it's also worth noting that you should use a list if you want to use any of the list methods. For example, the following code won't work:
def gen():
return (something for something in get_some_stuff())
print gen()[:2] # generators don't support indexing or slicing
print [5,6] + gen() # generators can't be added to lists
Basically, use a generator expression if all you're doing is iterating once. If you want to store and use the generated results, then you're probably better off with a list comprehension.
Since performance is the most common reason to choose one over the other, my advice is to not worry about it and just pick one; if you find that your program is running too slowly, then and only then should you go back and worry about tuning your code.
a = [1, 2, 3] b = [4, 5, 6] a.extend(b) -- a will now be [1, 2, 3, 4, 5, 6]. (Can you add newlines in comments??) –
Karoline a = (x for x in range(0,10)), b = [1,2,3] for instance. a.extend(b) throws an exception. b.extend(a) will evaluate all of a, in which case there's no point in making it a generator in the first place. –
Hagar itertools.chain(range(10), [4, 5, 6]) –
Stevenson next(x for x in some_list if x.foo == "bar") since it's neater than the comprehension equivalent [x for x in some_list if x.foo == "bar"][0] because it's easier to supply a default for no match like: next((for x in some_list if x.foo == "bar"), None). For a working example try print(next((x for x in range(10) if x == 11), 100)) and see how it defaults to 100 since 11 is not in the list. –
Pelham Iterating over the generator expression or the list comprehension will do the same thing. However, the list comprehension will create the entire list in memory first while the generator expression will create the items on the fly, so you are able to use it for very large (and also infinite!) sequences.
itertools.count(n) is an infinite sequence of integers, starting from n, so (2 ** item for item in itertools.count(n)) would be an infinite sequence of the powers of 2 starting at 2 ** n. –
Ephebe Use list comprehensions when the result needs to be iterated over multiple times, or where speed is paramount. Use generator expressions where the range is large or infinite.
See Generator expressions and list comprehensions for more info.
lists are speedier than generator expressions? From reading dF's answer, it came across that it was the other way around. –
Goodoh %timeit benchmarks) what this implies - that list comprehension is slightly faster than a generator (as @HassanBaig said, this is not what I expected). But list comprehension memory consumption (with %memit) is much higher than a generator. –
Luminescent The important point is that the list comprehension creates a new list. The generator creates a an iterable object that will "filter" the source material on-the-fly as you consume the bits.
Imagine you have a 2TB log file called "hugefile.txt", and you want the content and length for all the lines that start with the word "ENTRY".
So you try starting out by writing a list comprehension:
logfile = open("hugefile.txt","r")
entry_lines = [(line,len(line)) for line in logfile if line.startswith("ENTRY")]
This slurps up the whole file, processes each line, and stores the matching lines in your array. This array could therefore contain up to 2TB of content. That's a lot of RAM, and probably not practical for your purposes.
So instead we can use a generator to apply a "filter" to our content. No data is actually read until we start iterating over the result.
logfile = open("hugefile.txt","r")
entry_lines = ((line,len(line)) for line in logfile if line.startswith("ENTRY"))
Not even a single line has been read from our file yet. In fact, say we want to filter our result even further:
long_entries = ((line,length) for (line,length) in entry_lines if length > 80)
Still nothing has been read, but we've specified now two generators that will act on our data as we wish.
Lets write out our filtered lines to another file:
outfile = open("filtered.txt","a")
for entry,length in long_entries:
outfile.write(entry)
Now we read the input file. As our for loop continues to request additional lines, the long_entries generator demands lines from the entry_lines generator, returning only those whose length is greater than 80 characters. And in turn, the entry_lines generator requests lines (filtered as indicated) from the logfile iterator, which in turn reads the file.
So instead of "pushing" data to your output function in the form of a fully-populated list, you're giving the output function a way to "pull" data only when its needed. This is in our case much more efficient, but not quite as flexible. Generators are one way, one pass; the data from the log file we've read gets immediately discarded, so we can't go back to a previous line. On the other hand, we don't have to worry about keeping data around once we're done with it.
The benefit of a generator expression is that it uses less memory since it doesn't build the whole list at once. Generator expressions are best used when the list is an intermediary, such as summing the results, or creating a dict out of the results.
For example:
sum(x*2 for x in xrange(256))
dict( (k, some_func(k)) for k in some_list_of_keys )
The advantage there is that the list isn't completely generated, and thus little memory is used (and should also be faster)
You should, though, use list comprehensions when the desired final product is a list. You are not going to save any memeory using generator expressions, since you want the generated list. You also get the benefit of being able to use any of the list functions like sorted or reversed.
For example:
reversed( [x*2 for x in xrange(256)] )
sum(x*2 for x in xrange(256)) –
Katonah sorted and reversed work fine on any iterable, generator expressions included. –
Excited When creating a generator from a mutable object (like a list) be aware that the generator will get evaluated on the state of the list at time of using the generator, not at time of the creation of the generator:
>>> mylist = ["a", "b", "c"]
>>> gen = (elem + "1" for elem in mylist)
>>> mylist.clear()
>>> for x in gen: print (x)
# nothing
If there is any chance of your list getting modified (or a mutable object inside that list) but you need the state at creation of the generator you need to use a list comprehension instead.
gen will cause unpredictable results, just like iterating over the list directly. –
Tmesis Python 3.7:
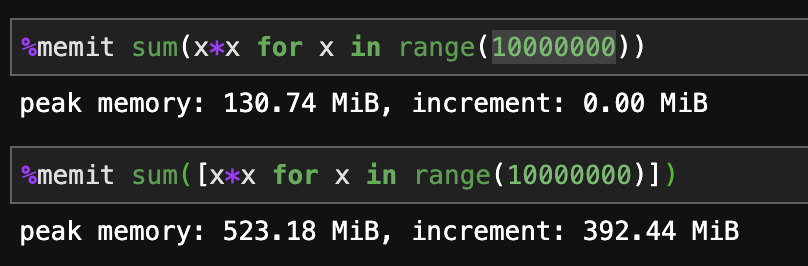
List comprehensions are faster.
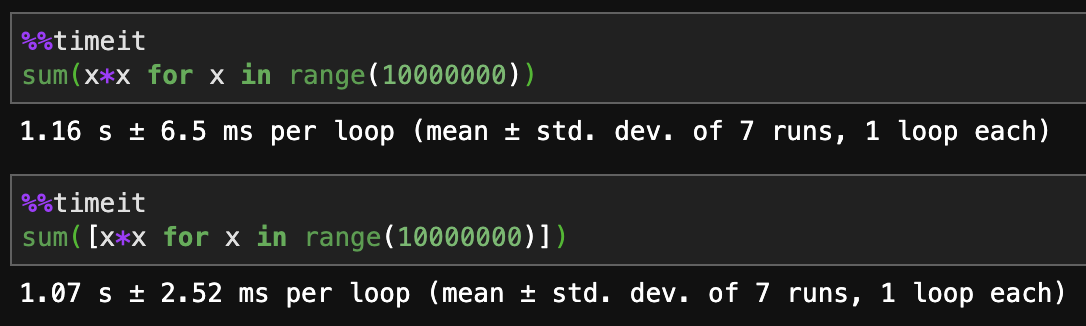
Generators are more memory efficient.
As all others have said, if you're looking to scale infinite data, you'll need a generator eventually. For relatively static small and medium-sized jobs where speed is necessary, a list comprehension is best.
any and you anticipate an early False element, the generator can give a substantial improvement over a list comprehension. But if both will be exhausted, then list comps are generally faster. You really need to profile the application and see. –
Debarath Sometimes you can get away with the tee function from itertools, it returns multiple iterators for the same generator that can be used independently.
I'm using the Hadoop Mincemeat module. I think this is a great example to take a note of:
import mincemeat
def mapfn(k,v):
for w in v:
yield 'sum',w
#yield 'count',1
def reducefn(k,v):
r1=sum(v)
r2=len(v)
print r2
m=r1/r2
std=0
for i in range(r2):
std+=pow(abs(v[i]-m),2)
res=pow((std/r2),0.5)
return r1,r2,res
Here the generator gets numbers out of a text file (as big as 15GB) and applies simple math on those numbers using Hadoop's map-reduce. If I had not used the yield function, but instead a list comprehension, it would have taken a much longer time calculating the sums and average (not to mention the space complexity).
Hadoop is a great example for using all the advantages of Generators.
Some notes for built-in Python functions:
Use a generator expression if you need to exploit the short-circuiting behaviour of any or all. These functions are designed to stop iterating when the answer is known, but a list comprehension must evaluate every element before the function can be called.
For example, if we have
from time import sleep
def long_calculation(value):
sleep(1) # for simulation purposes
return value == 1
then any([long_calculation(x) for x in range(10)]) takes about ten seconds, as long_calculation will be called for every x. any(long_calculation(x) for x in range(10)) takes only about two seconds, since long_calculation will only be called with 0 and 1 inputs.
When any and all iterate over the list comprehension, they will still stop checking elements for truthiness once an answer is known (as soon as any finds a true result, or all finds a false one); however, this is usually trivial compared to the actual work done by the comprehension.
Generator expressions are of course more memory efficient, when it's possible to use them. List comprehensions will be slightly faster with the non-short-circuiting min, max and sum (timings for max shown here):
$ python -m timeit "max(_ for _ in range(1))"
500000 loops, best of 5: 476 nsec per loop
$ python -m timeit "max([_ for _ in range(1)])"
500000 loops, best of 5: 425 nsec per loop
$ python -m timeit "max(_ for _ in range(100))"
50000 loops, best of 5: 4.42 usec per loop
$ python -m timeit "max([_ for _ in range(100)])"
100000 loops, best of 5: 3.79 usec per loop
$ python -m timeit "max(_ for _ in range(10000))"
500 loops, best of 5: 468 usec per loop
$ python -m timeit "max([_ for _ in range(10000)])"
500 loops, best of 5: 442 usec per loop
List comprehensions are eager but generators are lazy.
In list comprehensions all objects are created right away, it takes longer to create and return the list. In generator expressions, object creation is delayed until request by next(). Upon next() generator object is created and returned immediately.
Iteration is faster in list comprehensions because objects are already created.
If you iterate all the elements in list comprehension and generator expression, time performance is about the same. Even though generator expression return generator object right away, it does not create all the elements. Everytime you iterate over a new element, it will create and return it.
But if you do not iterate through all the elements generator are more efficient. Let's say you need to create a list comprehensions that contains millions of items but you are using only 10 of them. You still have to create millions of items. You are just wasting time for making millions of calculations to create millions of items to use only 10. Or if you are making millions of api requests but end up using only 10 of them. Since generator expressions are lazy, it does not make all the calculations or api calls unless it is requested. In this case using generator expressions will be more efficient.
In list comprehensions entire collection is loaded to the memory. But generator expressions, once it returns a value to you upon your next() call, it is done with it and it does not need to store it in the memory any more. Only a single item is loaded to the memory. If you are iterating over a huge file in disk, if file is too big you might get memory issue. In this case using generator expression is more efficient.
There is something that I think most of the answers have missed. List comprehension basically creates a list and adds it to the stack. In cases where the list object is extremely large, your script process would be killed. A generator would be more preferred in this case as its values are not stored in memory but rather stored as a stateful function. Also speed of creation; list comprehension are slower than generator comprehension
In short; use list comprehension when the size of the obj is not excessively large else use generator comprehension
For functional programming, we want to use as little indexing as possible. For this reason, If we want to continue using the elements after we take the first slice of elements, islice() is a better choice since the iterator state is saved.
from itertools import islice
def slice_and_continue(sequence):
ret = []
seq_i = iter(sequence) #create an iterator from the list
seq_slice = islice(seq_i,3) #take first 3 elements and print
for x in seq_slice: print(x),
for x in seq_i: print(x**2), #square the rest of the numbers
slice_and_continue([1,2,3,4,5])
output: 1 2 3 16 25
© 2022 - 2025 — McMap. All rights reserved.
[exp for x in iter]just be sugar forlist((exp for x in iter))? or is there an execution difference ? – ArgoX = [x**2 for x in range(5)]; print xwithY = list(y**2 for y in range(5)); print y, the second will give an error. In Python3, a list comprehension is indeed the syntactic sugar for a generator expression fed tolist()as you expected, so the loop variable will no longer leak out. – Vandenlist(exp for x in iter)? I'm guessing, it's alternative syntax forlist((exp for x in iter))? It's somewhat confusing though, as brackets are part of the syntax for generator expressions, as well as the usual function application syntax. – Barbetlist), the call parentheses can serve double duty as the genexpr parentheses (specifically, the genexpr requires parentheses on either side, and no comma on either side inside the parens). They don't own their parentheses, they just need them to exist. So both options are legal and identical, the former being more idiomatic. – Vivien