It does not make sense. Your compiler ought to be emitting these instructions implicitly for memcpy/memcmp/similar intrinsics, if it is able to emit SIMD at all.
You may need to explicitly instruct GCC to emit SSE opcodes with eg -msse -msse2; some GCCs do not enable them by default. Also, if you do not tell GCC to optimize (ie, -o2), it won't even try to emit fast code.
The use of SIMD opcodes for memory work like this can have a massive performance impact, because they also include cache prefetches and other DMA hints that are important for optimizing bus access. But that doesn't mean that you need to emit them manually; even though most compiler stink at emitting SIMD ops generally, every one I've used at least handles them for the basic CRT memory functions.
Basic math functions can also benefit a lot from setting the compiler to SSE mode. You can easily get an 8x speedup on basic sqrt() just by telling the compiler to use the SSE opcode instead of the terrible old x87 FPU.
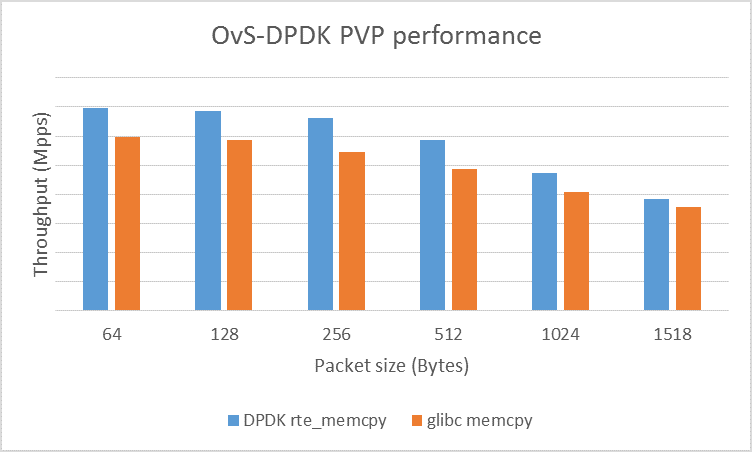
memcpyis actually the worst case for an SSE intrinsic, because SSE can't be used for the edge cases. Do those compilers emit SIMD code forstrlenandmemchr? – Huihuie