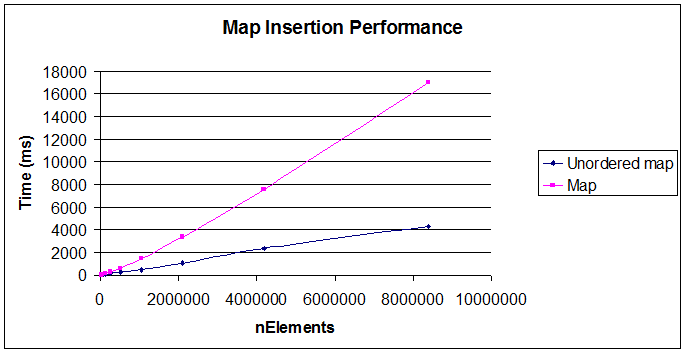
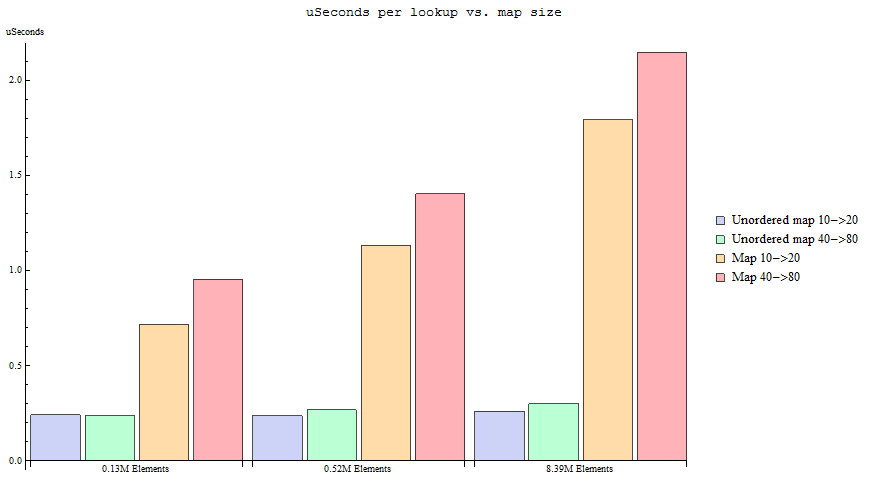
I think the question is partially answered, as no information was provided about the performance with "int" types as keys. I did my own analysis and I find out that std::map can outperform (in speed) std::unordered_map in many practical situations when using integers as keys.
Integer Test
The test scenario consisted in populating maps with sequential and random keys, and with strings values with lengths in the range [17:119] in multiples of 17. Tests where performed with elements count in the range [10:100000000] in powers of 10.
Labels:
Map64: std::map<uint64_t,std::string>
Map32: std::map<uint32_t,std::string>
uMap64: std::unordered_map<uint64_t,std::string>
uMap32: std::unordered_map<uint32_t,std::string>
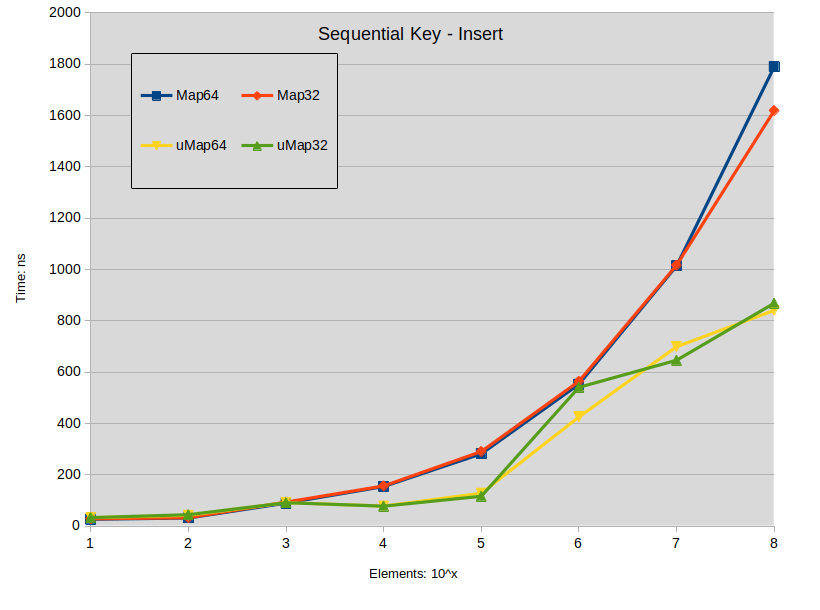
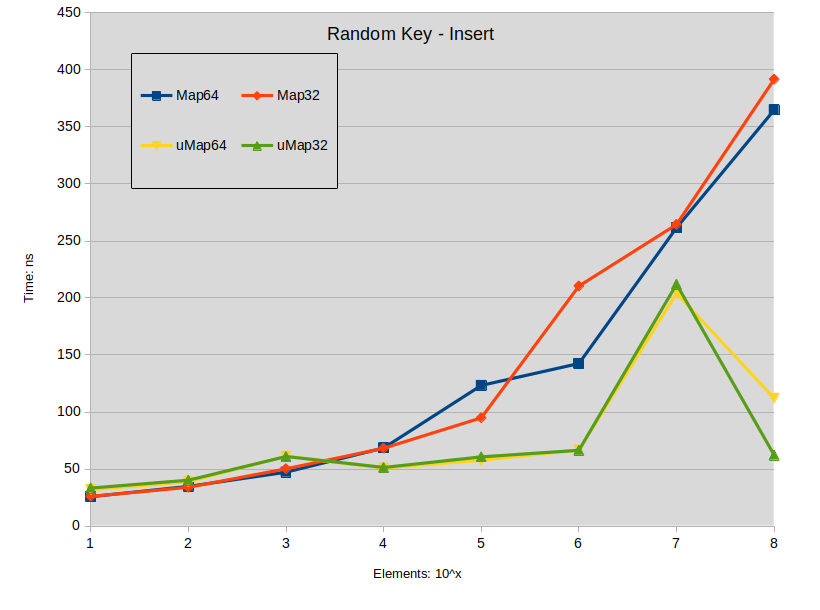
Insertion
Labels:
Sequencial Key Insert: maps were constructed with keys in the range [0-ElementCount]
Random Key Insert: maps were constructed with random keys in the full range of the type
![sequencial-key-insert]()
![random-key-insert]()
Conclusion on insertion:
- Insertion of spread keys in std::map tends to outperform std::unordered_map when map size is under 10000 elements.
- Insertion of dense keys in std::map doesn't present performance difference with std::unordered_map under 1000 elements.
- In all other situations std::unordered_map tends to perform faster.
Look up
Labels:
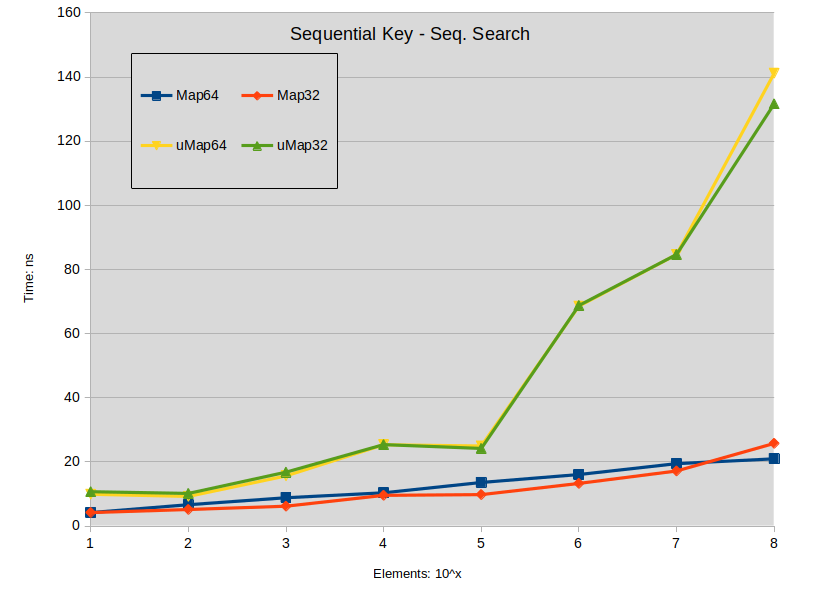
Sequential Key - Seq. Search: Search is performed in the dense map (keys are sequential). All searched keys exists in the map.
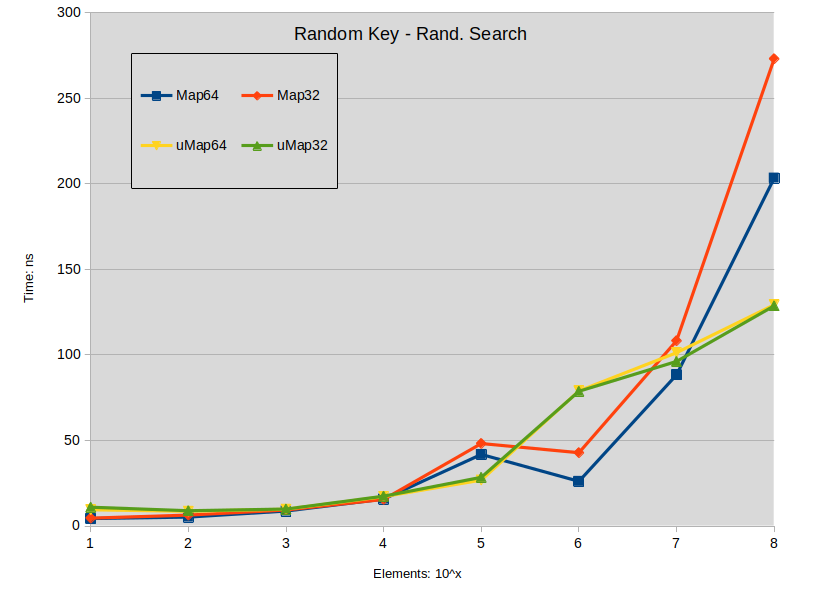
Random Key - Rand. Search: Search is performed in the sparse map (keys are random). All searched keys exists in the map.
(label names can be miss leading, sorry about that)
![sequential_key]()
![random_key]()
Conclusion on look up:
- Search on spread std::map tends to slightly outperform std::unordered_map when map size is under 1000000 elements.
- Search on dense std::map outperforms std::unordered_map
Failed Look up
Labels:
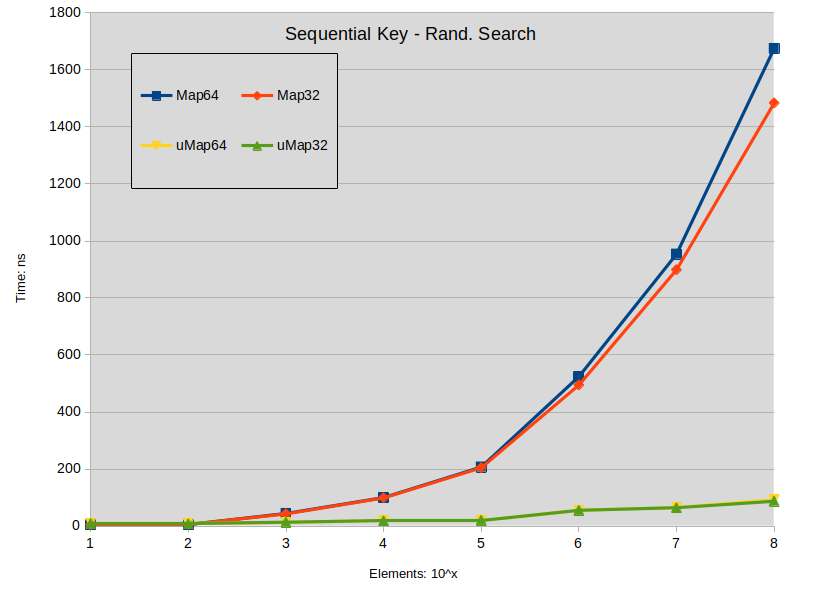
Sequential Key - Rand. Search: Search is performed in the dense map. Most keys do not exists in the map.
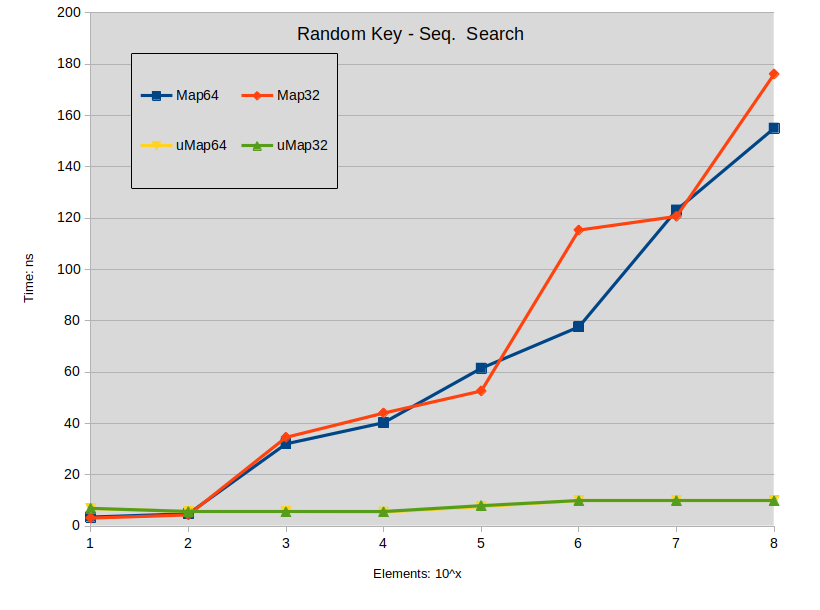
Random Key - Seq. Search: Search is performed in the sparse map. Most keys do not exists in the map.
(label names can be miss leading, sorry about that)
![sequential_key_rs]()
![random_key_ss]()
Conclusion on failed look up:
- Search miss is a big impact in std::map.
General conclusion
Even when speed is needed std::map for integer keys can still be a better option in many situations. As a practical example, I have a dictionary
where look-ups never fail and although the keys have a sparse distribution it will be perform at worse at the same speed as std::unordered_map, as my element count is under 1K. And the memory footprint is significantly lower.
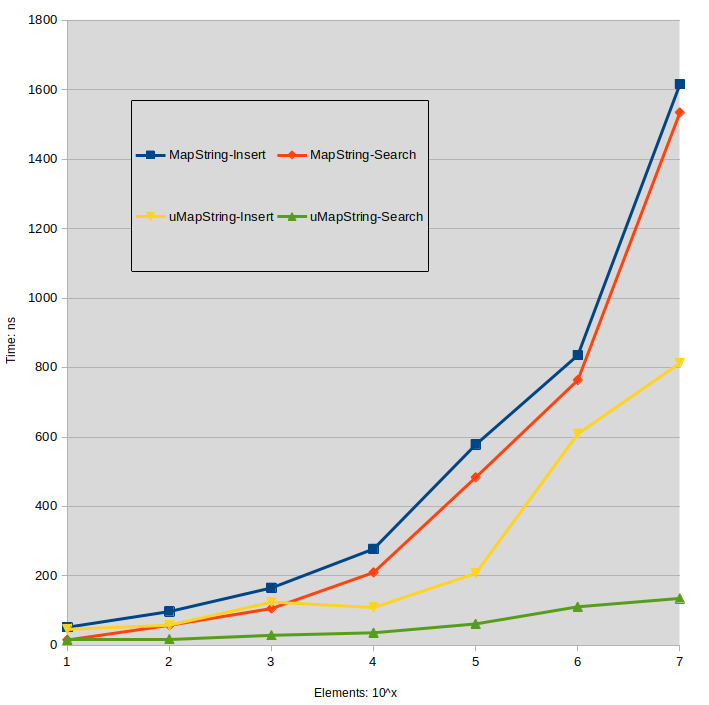
String Test
For reference I present here the timings for string[string] maps. Key strings are formed from a random uint64_t value, Value strings are the same used in the other tests.
Labels:
MapString: std::map<std::string,std::string>
uMapString: std::unordered_map<std::string,std::string>
![string_string_maps]()
Evaluation Platform
OS: Linux - OpenSuse Tumbleweed
Compiler: g++ (SUSE Linux) 11.2.1 20210816
CPU: Intel(R) Core(TM) i9-9900 CPU @ 3.10GHz
RAM: 64Gb