How do I check if PyTorch is using the GPU? The nvidia-smi command can detect GPU activity, but I want to check it directly from inside a Python script.
How do I check if PyTorch is using the GPU?
These functions should help:
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.cuda.device_count()
1
>>> torch.cuda.current_device()
0
>>> torch.cuda.device(0)
<torch.cuda.device at 0x7efce0b03be0>
>>> torch.cuda.get_device_name(0)
'GeForce GTX 950M'
This tells us:
- CUDA is available and can be used by one device.
Device 0refers to the GPUGeForce GTX 950M, and it is currently chosen by PyTorch.
I think this just shows that these devices are available on the machine but I'm not sure whether you can get how much memory is being used from each GPU or so.. –
Aeroscope
running
torch.cuda.current_device() was helpful for me. It showed that my gpu is unfortunately too old: "Found GPU0 GeForce GTX 760 which is of cuda capability 3.0. PyTorch no longer supports this GPU because it is too old." –
Volar torch.cuda.is_available() –
Conakry @Aeroscope Thanks for pointing this out. Is there a function call that gives us that information (how much memory is being used by each GPU) ? :) –
Deviationism
@frank Yep, simply this command:
$ watch -n 2 nvidia-smi does the job. For more details, please see my answer below. –
Aeroscope one liner:
print(f"running with device: {torch.cuda.get_device_name(torch.cuda.current_device())}") –
Balikpapan is there a way to get a list of all currently available gpus? something like
devices = torch.get_all_devices() # [0, 1, 2] or whatever their name is –
Hilar @CharlieParker, You'd want (assuming you've
import torch): devices = [d for d in range(torch.cuda.device_count())] And if you want the names: device_names = [torch.cuda.get_device_name(d) for d in devices] –
Askja How to check it for AMD GPU? I mean, there is ROCm for PyTorch –
Paramagnet
This was very useful for me.
torch.cuda.is_available() was unexpectedly returning False. Running nvidia-smi produced WARNING: infoROM is corrupted at gpu 0000:00:1E.0 on the last line of its output. It was caused by a hardware error that was "fixed" by starting and stopping the EC2 instance; rebooting had no impact. –
Darlington torch.cuda.is_available() is incorrect due to the error message mentioned by JohnnyFun. is_available can still return TRUE even if pytorch can't actually use the cuda. –
Lussi
@Volar Did you need to do any preprocessing to get that output when calling current_device() ? Mine just says "0". –
Lussi
@Volar I read that it's because it just outputs the index of the GPU. Do you know if the string you saw was an exception or a string? I don't know how to simulate this on my computer because my GPU isn't too old. –
Lussi
@Lussi -- you need to call
torch.cuda.get_device_name(index). –
Darned As it hasn't been proposed here, I'm adding a method using torch.device, as this is quite handy, also when initializing tensors on the correct device.
# setting device on GPU if available, else CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
print()
#Additional Info when using cuda
if device.type == 'cuda':
print(torch.cuda.get_device_name(0))
print('Memory Usage:')
print('Allocated:', round(torch.cuda.memory_allocated(0)/1024**3,1), 'GB')
print('Cached: ', round(torch.cuda.memory_reserved(0)/1024**3,1), 'GB')
Edit: torch.cuda.memory_cached has been renamed to torch.cuda.memory_reserved. So use memory_cached for older versions.
Output:
Using device: cuda
Tesla K80
Memory Usage:
Allocated: 0.3 GB
Cached: 0.6 GB
As mentioned above, using device it is possible to:
To move tensors to the respective
device:torch.rand(10).to(device)To create a tensor directly on the
device:torch.rand(10, device=device)
Which makes switching between CPU and GPU comfortable without changing the actual code.
Edit:
As there has been some questions and confusion about the cached and allocated memory I'm adding some additional information about it:
torch.cuda.max_memory_cached(device=None)
Returns the maximum GPU memory managed by the caching allocator in bytes for a given device.torch.cuda.memory_allocated(device=None)
Returns the current GPU memory usage by tensors in bytes for a given device.
You can either directly hand over a device as specified further above in the post or you can leave it None and it will use the current_device().
Additional note: Old graphic cards with Cuda compute capability 3.0 or lower may be visible but cannot be used by Pytorch!
Thanks to hekimgil for pointing this out! - "Found GPU0 GeForce GT 750M which is of cuda capability 3.0. PyTorch no longer supports this GPU because it is too old. The minimum cuda capability that we support is 3.5."
I tried your code, it recognizes the graphics card but the allocated and cached are both 0GB. Is it normal or do I need to configure them? –
Recusant
@Recusant If you haven't done any computation before this is perfectly normal. It's also rather unlikely that you can detect the GPU model within PyTorch but not access it. Try doing some computations on GPU and you should see that the values change. –
Coyotillo
I create a .py script based on this tutorial - analyticsvidhya.com/blog/2018/02/pytorch-tutorial. Particularly copy/pasting the section starting with
## neural network in pytorch, then I add your code at the end. It still shows Using device: cuda; and 0Gb for Allocated and Cached. Also tried inserting it at the end of the for loop for i in range(epoch): after back-propagation, still all 0GB –
Recusant @Recusant Are you sure created all the tensor using
torch.rand(10).to(device) or torch.rand(10, device=device)? One note: the code above uses round, rounding to one digit after the comma. So small amounts may be just rounded to zero. You can change the rounding precision or just create larger tensors. If that does not solve your problem I suggest you create a new question where you can add the necessary detail of your exact setup and system. –
Coyotillo I added
device=device, and got this RuntimeError: Expected object of backend CPU but got backend CUDA for argument #2 'mat2' –
Recusant @Recusant You have to be consistent, you cannot perform operations across devices. Any operation like
my_tensor_on_gpu * my_tensor_on_cpu will fail. –
Coyotillo Your answer is great but for the first device assignment line, I would like to point out that just because there is a cuda device available, does not mean that we can use it. For example, I have this in my trusty old computer:
Found GPU0 GeForce GT 750M which is of cuda capability 3.0. PyTorch no longer supports this GPU because it is too old. The minimum cuda capability that we support is 3.5. –
Recalesce is there a way to get a list of all currently available gpus? something like
devices = torch.get_all_devices() # [0, 1, 2] or whatever their name is –
Hilar @CharlieParker I haven't tested this, but I believe you can use
torch.cuda.device_count() where list(range(torch.cuda.device_count())) should give you a list over all device indices. –
Coyotillo It can be the case that you get the error:
Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: CUDA error: no kernel image is available for execution on the device when executing torch.rand(10, device=device), so I don't think this answer is completely accurate answering the original post. Neither the accepted answer imho. Thanks –
Kobylak After you start running the training loop, if you want to manually watch it from the terminal whether your program is utilizing the GPU resources and to what extent, then you can simply use watch as in:
$ watch -n 2 nvidia-smi
This will continuously update the usage stats for every 2 seconds until you press ctrl+c
If you need more control on more GPU stats you might need, you can use more sophisticated version of nvidia-smi with --query-gpu=.... Below is a simple illustration of this:
$ watch -n 3 nvidia-smi --query-gpu=index,gpu_name,memory.total,memory.used,memory.free,temperature.gpu,pstate,utilization.gpu,utilization.memory --format=csv
which would output the stats something like:
Every 3.0s: nvidia-smi --query-gpu=index,gpu_name,memory.total,memory.used,memory.free,temperature.gpu,pstate,utilization.gpu,utilization.memory --format=csv Sat Apr 11 12:25:09 2020
index, name, memory.total [MiB], memory.used [MiB], memory.free [MiB], temperature.gpu, pstate, utilization.gpu [%], utilization.memory [%]
0, GeForce GTX TITAN X, 12212 MiB, 10593 MiB, 1619 MiB, 86, P2, 100 %, 55 %
1, GeForce GTX TITAN X, 12212 MiB, 11479 MiB, 733 MiB, 84, P2, 93 %, 100 %
2, GeForce GTX TITAN X, 12212 MiB, 446 MiB, 11766 MiB, 36, P8, 0 %, 0 %
3, GeForce GTX TITAN X, 12212 MiB, 11 MiB, 12201 MiB, 38, P8, 0 %, 0 %
Note: There should not be any space between the comma separated query names in --query-gpu=.... Else those values will be ignored and no stats are returned.
Also, you can check whether your installation of PyTorch detects your CUDA installation correctly by doing:
In [13]: import torch
In [14]: torch.cuda.is_available()
Out[14]: True
True status means that PyTorch is configured correctly and is using the GPU although you have to move/place the tensors with necessary statements in your code.
If you want to do this inside Python code, then look into this module:
https://github.com/jonsafari/nvidia-ml-py or in pypi here: https://pypi.python.org/pypi/nvidia-ml-py/
Just remember that PyTorch uses a cached GPU memory allocator. You might see low GPU-Utill for nividia-smi even if it's fully used. –
Rogerson
@JakubBielan thanks! could you please provide a reference for more reading on this? –
Aeroscope
That
watch is useful –
Allargando Is this only for linux? –
Balikpapan
nvidia-smi has a flag -l for loop seconds, so you don't have to use
watch: nvidia-smi -l 2 Or in milliseconds: nvidia-smi -lms 2000 –
Sicyon From practical standpoint just one minor digression:
import torch
dev = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
This dev now knows if cuda or cpu.
And there is a difference in how you deal with models and with tensors when moving to cuda. It is a bit strange at first.
import torch
import torch.nn as nn
dev = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
t1 = torch.randn(1,2)
t2 = torch.randn(1,2).to(dev)
print(t1) # tensor([[-0.2678, 1.9252]])
print(t2) # tensor([[ 0.5117, -3.6247]], device='cuda:0')
t1.to(dev)
print(t1) # tensor([[-0.2678, 1.9252]])
print(t1.is_cuda) # False
t1 = t1.to(dev)
print(t1) # tensor([[-0.2678, 1.9252]], device='cuda:0')
print(t1.is_cuda) # True
class M(nn.Module):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(1,2)
def forward(self, x):
x = self.l1(x)
return x
model = M() # not on cuda
model.to(dev) # is on cuda (all parameters)
print(next(model.parameters()).is_cuda) # True
This all is tricky and understanding it once, helps you to deal fast with less debugging.
also you need at the begning
import torch.nn as nn –
Betroth | Query | Command |
|---|---|
| Does PyTorch see any GPUs? | torch.cuda.is_available() |
| Are tensors stored on GPU by default? | torch.rand(10).device |
| Set default tensor type to CUDA: | torch.set_default_tensor_type(torch.cuda.FloatTensor) |
| Is this tensor a GPU tensor? | my_tensor.is_cuda |
| Is this model stored on the GPU? | all(p.is_cuda for p in my_model.parameters()) |
I didn't know you could set tensors to be on GPU by default. Cool! –
Weeny
What if there are multiple gpus. Can I pick which one tensors are created on? –
Weeny
Set default tensor type to CUDA is deprecated and torch.set_default_device('cuda') is used. nowadays –
Socle
From the official site's get started page, you can check if the GPU is available for PyTorch like so:
import torch
torch.cuda.is_available()
Reference: PyTorch | Get Started
this is the most helpful (concise) answer –
Nidus
To check if there is a GPU available:
torch.cuda.is_available()
If the above function returns False,
- you either have no GPU,
- or the Nvidia drivers have not been installed so the OS does not see the GPU,
- or the GPU is being hidden by the environmental variable
CUDA_VISIBLE_DEVICES. When the value ofCUDA_VISIBLE_DEVICESis -1, then all your devices are being hidden. You can check that value in code with this line:os.environ['CUDA_VISIBLE_DEVICES']
If the above function returns True that does not necessarily mean that you are using the GPU. In Pytorch you can allocate tensors to devices when you create them. By default, tensors get allocated to the cpu. To check where your tensor is allocated do:
# assuming that 'a' is a tensor created somewhere else
a.device # returns the device where the tensor is allocated
Note that you cannot operate on tensors allocated in different devices. To see how to allocate a tensor to the GPU, see here: https://pytorch.org/docs/stable/notes/cuda.html
Simply from command prompt or Linux environment run the following command.
python -c 'import torch; print(torch.cuda.is_available())'
The above should print True
python -c 'import torch; print(torch.rand(2,3).cuda())'
This one should print the following:
tensor([[0.7997, 0.6170, 0.7042], [0.4174, 0.1494, 0.0516]], device='cuda:0')
Almost all answers here reference torch.cuda.is_available(). However, that's only one part of the coin. It tells you whether the GPU (actually CUDA) is available, not whether it's actually being used. In a typical setup, you would set your device with something like this:
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
but in larger environments (e.g. research) it is also common to give the user more options, so based on input they can disable CUDA, specify CUDA IDs, and so on. In such case, whether or not the GPU is used is not only based on whether it is available or not. After the device has been set to a torch device, you can get its type property to verify whether it's CUDA or not.
if device.type == 'cuda':
# do something
For a MacBook M1 system:
import torch
print(torch.backends.mps.is_available(), torch.backends.mps.is_built())
And both should be True.
Note that this also works for at least some older Intel Macbooks. This works on my 2019 Intel macbook with a Radeon Pro 560X 4gb GPU. –
Sourdough
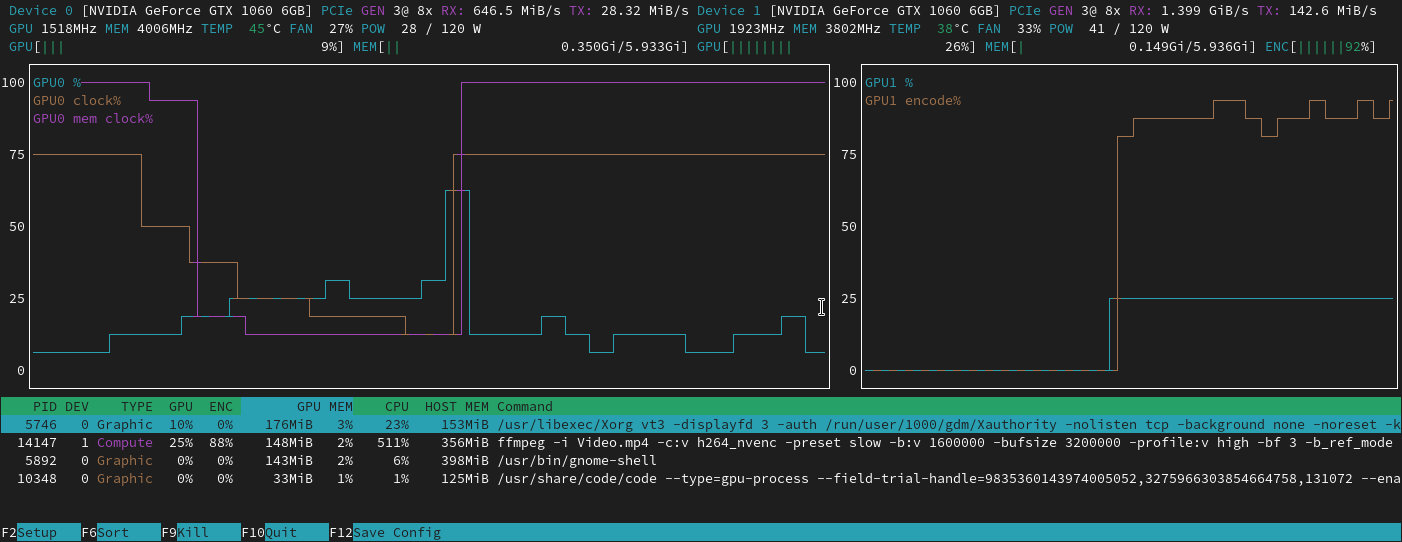
If you are using Linux I suggest to install nvtop https://github.com/Syllo/nvtop
You will get something like this:
If you are here because your pytorch always gives False for torch.cuda.is_available() that's probably because you installed your pytorch version without GPU support. (Eg: you coded up in laptop then testing on server).
The solution is to uninstall and install pytorch again with the right command from pytorch downloads page. Also refer this pytorch issue.
Even though what you have written is related to the question. The question is: "How to check if pytorch is using the GPU?" and not "What can I do if PyTorch doesn't detect my GPU?" So I would say that this answer does not really belong to this question. But you may find another question about this specific issue where you can share your knowledge. If not you could even write a question and answer it yourself to help others with the same issue! –
Coyotillo
import torch
torch.cuda.is_available()
works fine. If you want to monitor the activity during the usage of torch, you can use this Python script (Windows only - but can be adjusted easily):
import io
import shutil
import subprocess
from time import sleep, strftime
import pandas as pd
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
startupinfo.wShowWindow = subprocess.SW_HIDE
creationflags = subprocess.CREATE_NO_WINDOW
invisibledict = {
"startupinfo": startupinfo,
"creationflags": creationflags,
"start_new_session": True,
}
path = shutil.which("nvidia-smi.exe")
def nvidia_log(savepath=None, sleeptime=1):
"""
Monitor NVIDIA GPU information and log the data into a pandas DataFrame.
Parameters:
savepath (str, optional): The file path to save the log data as a CSV file.
If provided, the data will be saved upon KeyboardInterrupt.
sleeptime (int, optional): The time interval (in seconds) between each data logging.
Returns:
pandas.DataFrame: A DataFrame containing the logged NVIDIA GPU information with the following columns:
- index: GPU index.
- name: GPU name.
- memory.total [MiB]: Total GPU memory in MiB (Mebibytes).
- memory.used [MiB]: Used GPU memory in MiB (Mebibytes).
- memory.free [MiB]: Free GPU memory in MiB (Mebibytes).
- temperature.gpu: GPU temperature in Celsius.
- pstate: GPU performance state.
- utilization.gpu [%]: GPU utilization percentage.
- utilization.memory [%]: Memory utilization percentage.
- timestamp: Timestamp in the format "YYYY_MM_DD_HH_MM_SS".
Description:
This function uses the NVIDIA System Management Interface (nvidia-smi) to query GPU information,
including memory usage, temperature, performance state, and utilization. The data is collected
in real-time and logged into a pandas DataFrame. The logging continues indefinitely until a
KeyboardInterrupt (usually triggered by pressing Ctrl + C).
If the 'savepath' parameter is provided, the collected GPU information will be saved to a CSV
file when the monitoring is interrupted by the user (KeyboardInterrupt).
Note: This function is intended for systems with NVIDIA GPUs on Windows and requires the nvidia-smi.exe
executable to be available in the system path.
Example:
# Start monitoring NVIDIA GPU and display the real-time log
nvidia_log()
# Start monitoring NVIDIA GPU and save the log data to a CSV file
nvidia_log(savepath="gpu_log.csv")
# Start monitoring NVIDIA GPU with a custom time interval between logs (e.g., 2 seconds)
nvidia_log(sleeptime=2)
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
0 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1321 MiB 6697 MiB 45 P8 16 % 5 % 2023_07_18_11_52_55
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
1 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1321 MiB 6697 MiB 44 P8 17 % 6 % 2023_07_18_11_52_56
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
2 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1321 MiB 6697 MiB 44 P8 2 % 4 % 2023_07_18_11_52_57
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
3 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1321 MiB 6697 MiB 44 P8 4 % 5 % 2023_07_18_11_52_58
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
4 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1321 MiB 6697 MiB 46 P2 22 % 1 % 2023_07_18_11_52_59
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
5 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1320 MiB 6698 MiB 45 P8 0 % 0 % 2023_07_18_11_53_00
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
6 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1320 MiB 6698 MiB 45 P8 2 % 4 % 2023_07_18_11_53_01
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
7 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1320 MiB 6698 MiB 44 P8 12 % 5 % 2023_07_18_11_53_02
index name memory.total [MiB] memory.used [MiB] memory.free [MiB] temperature.gpu pstate utilization.gpu [%] utilization.memory [%] timestamp
8 0 NVIDIA GeForce RTX 2060 SUPER 8192 MiB 1320 MiB 6698 MiB 44 P8 3 % 4 % 2023_07_18_11_53_03
"""
df = pd.DataFrame(
columns=[
"index",
" name",
" memory.total [MiB]",
" memory.used [MiB]",
" memory.free [MiB]",
" temperature.gpu",
" pstate",
" utilization.gpu [%]",
" utilization.memory [%]",
"timestamp",
]
)
try:
while True:
p = subprocess.run(
[
path,
"--query-gpu=index,gpu_name,memory.total,memory.used,memory.free,temperature.gpu,pstate,"
"utilization.gpu,utilization.memory",
"--format=csv",
],
capture_output=True,
**invisibledict
)
out = p.stdout.decode("utf-8", "ignore")
tstamp = strftime("%Y_%m_%d_%H_%M_%S")
df = pd.concat(
[df, pd.read_csv(io.StringIO(out)).assign(timestamp=tstamp)],
ignore_index=True,
)
print(df[len(df) - 1 :].to_string())
sleep(sleeptime)
except KeyboardInterrupt:
if savepath:
df.to_csv(savepath)
return df
It is possible for
torch.cuda.is_available()
to return True but to get the following error when running
>>> torch.rand(10).to(device)
as suggested by MBT:
RuntimeError: CUDA error: no kernel image is available for execution on the device
This link explains that
... torch.cuda.is_available only checks whether your driver is compatible with the version of cuda we used in the binary. So it means that CUDA 10.1 is compatible with your driver. But when you do computation with CUDA, it couldn't find the code for your arch.
You can just use the following code:
import torch
torch.cuda.is_available()
if it returns True, it means the GPU is working, while False means that it does not.
hello, how to typing the words with background?@vvvv –
Stable
Obtain environment information using PyTorch via Terminal command
python -m torch.utils.collect_env
And if you can have True value for "Is CUDA available" in comand result like below, then your PyTorch is using GPU.
Is CUDA available: True
Most answers above shows how you can check the cuda availability which is important. But my understanding what you need is to see if you actually leverage the GPU. I suggest to check the which device contains the tensors you are processing. mytensor.get_device() https://pytorch.org/docs/stable/generated/torch.Tensor.get_device.html
Create a tensor on the GPU as follows:
$ python
>>> import torch
>>> print(torch.rand(3,3).cuda())
Do not quit, open another terminal and check if the python process is using the GPU using:
$ nvidia-smi
I specifically asked for a solution that does not involve
nvidia-smi from the command line –
Orbital Well, technically you can always parse the output any command-line tools, including
nvidia-smi. –
Scleroma Using the code below
import torch
torch.cuda.is_available()
will only display whether the GPU is present and detected by pytorch or not.
But in the "task manager-> performance" the GPU utilization will be very few percent.
Which means you are actually running using CPU.
To solve the above issue check and change:
- Graphics setting --> Turn on Hardware accelerated GPU settings, restart.
- Open NVIDIA control panel --> Desktop --> Display GPU in the notification area [Note: If you have newly installed windows then you also have to agree the terms and conditions in NVIDIA control panel]
This should work!
The task manager is a very bad way of determining GPU usage actually, see here: #69792348 –
Kenton
step 1: import torch library
import torch
#step 2: create tensor
tensor = torch.tensor([5, 6])
#step 3: find the device type
#output 1: in the below, the output we can get the size(tensor.shape), dimension(tensor.ndim), #and device on which the tensor is processed
tensor, tensor.device, tensor.ndim, tensor.shape
(tensor([5, 6]), device(type='cpu'), 1, torch.Size([2]))
#or
#output 2: in the below, the output we can get the only device type
tensor.device
device(type='cpu')
#As my system using cpu processor "11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz 2.42 GHz"
#find, if the tensor processed GPU?
print(tensor, torch.cuda.is_available()
# the output will be
tensor([5, 6]) False
#above output is false, hence it is not on gpu
#happy coding :)
torch.cuda.is_available() can still be true and tensor.device set to cpu. –
Henequen © 2022 - 2024 — McMap. All rights reserved.
devices = torch.get_all_devices() # [0, 1, 2] or whatever their name is– Hilar[torch.cuda.device(i) for i in range(torch.cuda.device_count())]– Orbitallist(range(torch.cuda.device_count())). Thanks though! – Hilarimport torch):devices = [d for d in range(torch.cuda.device_count())]And if you want the names:device_names = [torch.cuda.get_device_name(d) for d in devices]You may, like me, like to map these as dict for cross machine management:device_to_name = dict( device_names, devices )– Askja