I work in VFX which is a little bit different from CAD but not too different at least for modeling. There I've found it very useful to revolve the application design for modeling around the command pattern. Of course you don't necessarily have to make some ICommand interface for that. You might just use std::function and lambdas, for example.
Eliminating/Reducing Central Dependencies to Single Object Instances
However, I do things a bit differently for application state in that I favor more of a "pull" paradigm instead of a "push" for the type of things you're doing (I'll try to explain this better below in terms of what I mean by "push/pull"*) so that instead of a boatload things in "the world" accessing these few central manager instances and telling them what to do, the few central managers sorta "access the world" (not directly) and figure out what to do.
- Apologies in advance. I am not a very technically precise person and English is also not my native language (from Japan). If you can bear through my poor attempts at describing things, I think there will be some useful information there to some people. At least it was useful to me in ways I had to learn the hard way.
What I propose will not only eradicate singletons, but it will eradicate fan-in towards central application object instances in general which can make things a whole lot easier to reason about, make thread-safe, unit test, etc. Even if you use dependency injection over singletons, such application-wide objects and shared state, heavily depended upon, can make a lot of things more difficult from reasoning about side effects to the thread safety of your codebase.
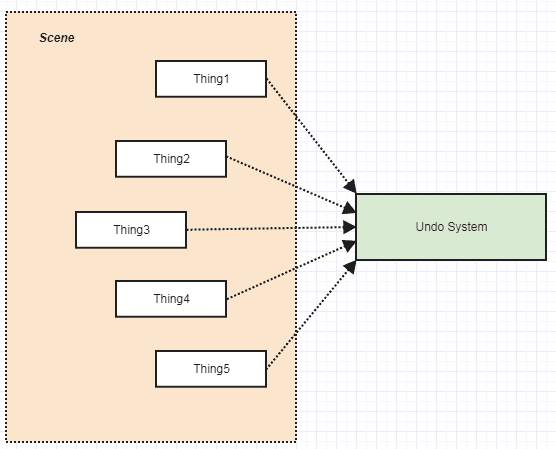
What I mean is that instead of, say, every single command writing to an undo manager which would require everything that can write undoable state to be coupled to this undo system, I invert the flow of communication away from the central object instance. Instead of this (fanning in towards single object instance):
![enter image description here]()
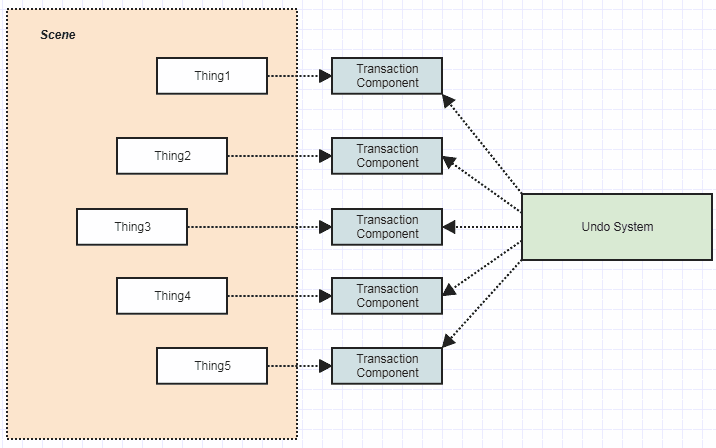
I suggest sorta flipping/inverting the communication (fan out from one central instance to many instances):
![enter image description here]()
And the undo system is no longer being told what to do anymore by everyone else. It figures out what to do by accessing the scene (specifically the transaction components). At the broad conceptual level I think of it in terms of "push/pull" (though I've been accused of being a bit confusing with this terminology, but I haven't come up with any better way to describe or think about it -- funnily it was a colleague who originally described this as "pulling" data as opposed to "pushing it" in response to my poor attempts at describing how a system worked to the team and his description was so intuitive to me that it has stuck with me ever since). In terms of dependencies between object instances (not object types) it's kind of replacing fan-in with fan-out.
Minimizing Knowledge
When you do that, you no longer have to have this manager kind of thing being centrally depended upon by so many things, and no longer have to include its header file all over the place.
There is still a transaction component that everything undoable has to include the header file for, but it's much, much simpler than the full-blown undo system (it's actually just data), and it's not instantiated just once for the entire application (it gets instantiated locally for every single thing that needs to record undoable actions).
The allows "the world" to work with less knowledge. The world doesn't have to know about full-blown undo managers, and undo managers don't have to know about the entire world. Both now only have to know about these uber simple transaction components.
Undo Systems
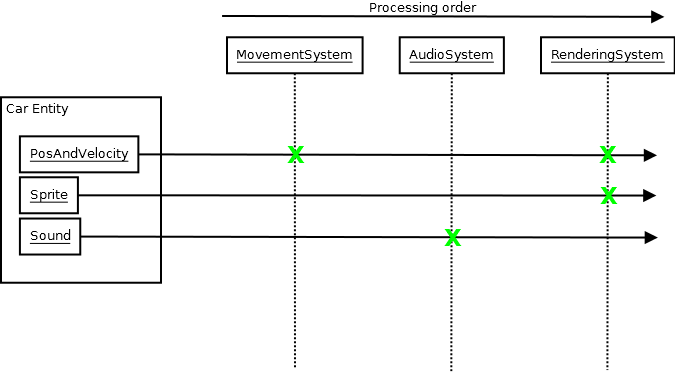
Specifically for undo systems, I achieve this kind of "inversion of communication" by having each scene object ("Thing" or "Entity") write to its own local transaction component. The undo system then, periodically (ex: after a command is executed) traverses the scene and gathers all the transaction components from each object in the scene and consolidates it as a single user-undoable entry, like so (pseudocode):
void UndoSystem::process(Scene& scene)
{
// Gather the transaction components in the scene
// to a single undo entry.
local undo_entry = {}
// Our central system loop. We loop through the scene
// and gather the information for the undo system to
// to work instead of having everything in the scene
// talk to the undo system. Most of the system can
// be completely oblivious that this undo system even
// exists.
for each transaction in scene.get<TransactionComponent>():
{
undo_entry.push_back(transaction);
// Clear the transaction component since we've recorded
// it to the undo entry so that entities can work with
// a fresh (empty) transaction.
transaction.clear();
}
// Record the undo entry to the undo system's history
// as a consolidated user-undoable action. I used 'this'
// just to emphasize the 'history' is a member of our
// undo system.
this->history.push_back(undo_entry);
}
This has the added bonus in that each entity in the scene can write to its own associated, local transaction component in its own separate thread without having to, say, deal with locks in critical execution paths trying to all write directly to a central undo system instance.
Also you can easily have more than one undo system instance using this approach. For example, it might be kind of confusing if a user is working in "Scene B" or "Project B" and hits undo only to undo a change in "Scene A/Project A" which they are not immediately working in. If they can't see what's happening, they might even inadvertently undo changes they wanted to keep. It'd be like me hitting undo in Visual Studio while working in Foo.cpp and accidentally undoing changes in Bar.cpp. As a result you often want more than one undo system/manager instance in software that allows multiple documents/projects/scenes. They should not necessarily be singletons let alone application-wide objects, and instead should often be document/project/scene-local objects. This approach will easily allow you to do that and also change your mind later, since it minimizes the amount of dependencies in the system to your undo manager (perhaps only a single command or two in your system needs to depend on it*).
- You can even decouple your undo/redo commands from the undo system by having them, say, push a
UserUndoEvent or UserRedoEvent to a central queue that both the command and undo systems can access. Again this makes them both dependent on these events and event queue, but the event type might be far simpler (it might just be an integer storing a value for a predefined named constant). It's the same kind of strategy applied even further.
Avoiding Fan-In to Central Object Instances
This is my preferred strategy whenever I find a case where you want many, many things to depend on one central object instance with major fan-in. And that can help all kinds of things from reducing build times, allowing changes to occur without rebuilding everything, more efficient multithreading, allowing design changes without having to rewrite a boatload of code, etc.
And that can likewise alleviate the temptation to use singletons. To me if dependency injection is a real PITA and there's a strong temptation to use singletons, I see that as a sign to consider a different approach to the design until you find one where dependency injection isn't a PITA anymore which is usually achieved through a lot of decoupling, specifically of a kind that avoids fan-in from a boatload of different places in code.
Seeking that is not the result of zealously trying to avoid singletons, but even pragmatically, the types of designs that tempt us to use singletons are often difficult to scale without their complexity becoming overwhelming at some point, since it implies a boatload of dependencies to central objects (and their states) all over the place, and those dependencies and interactions become really difficult to reason about in terms of what is actually going on after your codebase reaches a large enough scale. Dependency injection alone doesn't solve that issue necessarily, since we can still end up with a boatload of dependencies to application-wide objects injected all over the place. Instead what I've found to significantly mitigate this issue is to seek out designs that specifically make dependency injection no longer painful to do which means eliminating the bulk of those dependencies to application-wide instances of objects outright.
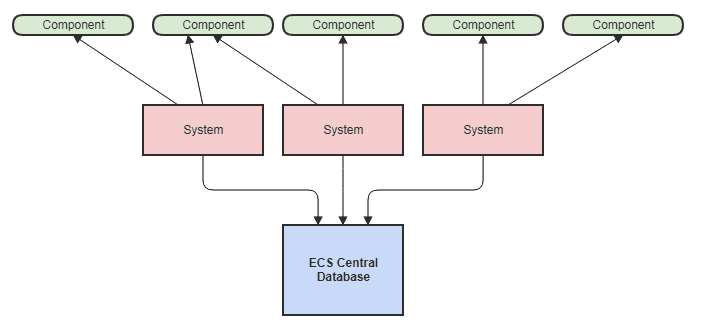
I do still have one central, very generalized, simple thing that many things depend on in my case, and what I propose will need at least one generalized data structure that's rather centralized. I use an entity-component system like this:
![enter image description here]()
... or this:
![enter image description here]()
So every single system in my case is dependent on the central ECS "database" instance and there I haven't been able to avoid fan-in. However, that's easy enough to inject since there are only a few dozen hefty systems that need dependency injection like a modeling system, physics system, rendering system, GUI system. Commands are also executed with the ECS "database" uniformly passed to them by parameter so that they can access whatever is needed in the scene without accessing a singleton.
Large-Scale Designs
Above all other things, when exploring various design methodologies, patterns, and SE metrics, I've found that the most effective way to allow systems to scale in complexity is to isolate hefty sections into "their own world", relying on the minimum amount of information to work. "Complete decoupling" of a kind that minimizes not only concrete information required for something to work, but also minimizes the abstract information as well, is, above all other things, the most effective way I've found to allow systems to scale without overwhelming the developers maintaining them. For me it's a huge warning sign when you have, say, a developer who knows NURBs surfaces inside out and can whip up impressive demos related to them, but is tripping over bugs in your system in his loft implementation not because his NURBs implementation is incorrect, but because he's dealing with central application-wide states incorrectly.
"Complete decoupling" breaks each hefty section of the codebase, like a rendering system, into its own isolated world. It barely needs information from the outside world to work. As a result the rendering developer can do his thing without knowing much about what's going on elsewhere. The alternative when you don't have these kinds of "isolated worlds" is a system whose centralized complexity spills into every single corner of the software, and the result is this "organic whole" which is very difficult to reason about and kind of requires every developer to know something about just about everything.
The somewhat (possibly) unusual thought I have is that abstractions are often considered the key way to decouple systems and objects, but an abstraction only reduces the amount of concrete information required for something to work. We may still find a system turning into this "organic whole" by having a boatload of abstract information that everything needs to work, and that can sometimes be just as difficult to reason about as the concrete alternative, even if it leaves more breathing room for changes. To really allow a system to scale without overwhelming our brains, the ultimate way I've found beneficial is to not make systems depend on a lot of abstract information, but to make them depend on as little information as possible of any form outright from the outside world.
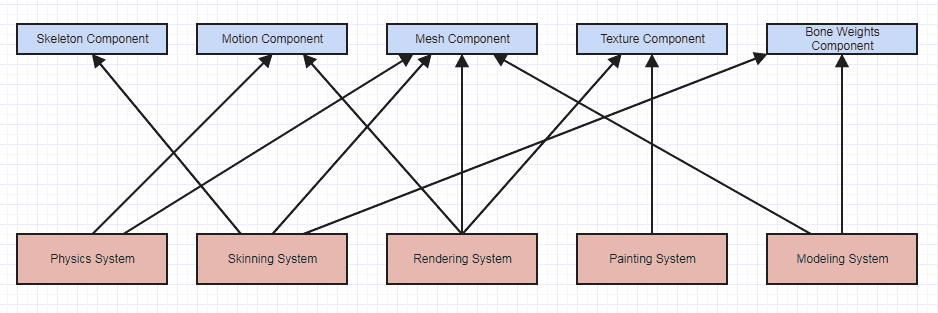
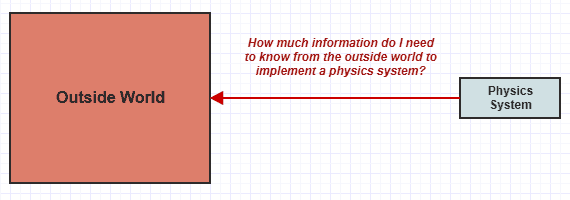
It can be a useful exercise to just sit down with a part of a system and ask, "How much information from the outside world do I need to comprehend to implement/change this thing?"
![enter image description here]()
In a former codebase I worked in (not of my design), the physics system above had to know about scene hierarchies, the property system, abstract transformer interfaces, transformation stacks, keyframes, envelopes, undo systems, nodal graph evaluation, selections, selection modes, system-wide properties (configs, i.e.), different types of geometry abstractions, particle emitters, etc. etc., and just to get started applying gravity to something in the scene. These were all abstract dependencies but perhaps to over 50 different non-trivial abstract interfaces in the system to comprehend from the outside world before we can even begin comprehending what the physics system is doing.
And naturally a physics system has a conceptual dependency to some of these concepts, but not all, and the ones that are there shouldn't need to expose too much information in order for a physics system to do its thing. That system was very difficult to maintain and often required a developer to spend a couple of years in training and study before he could even start contributing anything really substantial while even the seasoned veterans were having a difficult time figuring out what was going on because the amount of central information being accessed and modified required them to be on top of what the physics system was doing to some degree even if they were working on things completely unrelated.
So I think it's worth stepping back and thinking about these things in just a very human, "How much do I need to know to implement/change this thing vs. how much should I be required to know?" kind of way and seek to minimize the information if it far exceeds the second thought, and one of the ways to do that is using this proposed strategy to avoid fanning in on central application object instances. I'm generally obsessed with the human aspects but have never been so good at the technical aspects. Perhaps I should have gone into psychology, though it doesn't help that I'm insane. :-D
"Managers" vs. "Systems"
Now I'm a terrible person when it comes to proper technical terminology (somehow in spite of having designed a number of architectures, I'm still awful at communicating things in a technically precise way). But I have noticed a tendency towards "managers" often being used with a "push" mindset almost unanimously by developers who create anything they refer to as such. We request/push changes to be done centrally by telling these "managers" what to do.
Instead I have found it useful to favor what I want to call "systems", just having picked that up from architectures popular in game development. Systems "pull" as I want to call it. Nobody tells them specifically what to do. They instead figure it out on their own by accessing the world, pulling data from it to figure out what to do and do it. The world doesn't access them. They loop through things and do something. You can potentially apply this strategy to many of your "managers" so that the entire world isn't trying to talk to them.
This kind of "system" mindset (apologies if my terminology is so poor and my distinctions so arbitrary) was so useful to me to break free from a lot of "managers". I now only have one such central "manager" which is that ECS database, but it's just a data structure for storage. Systems just use them to retrieve components and entities to process in their loops.
![enter image description here]()
Destruction Order
Another thing this type of strategy tackles is destruction order which can get quite hairy for complex systems. Even when you have one central "application object" storing all these managers and thereby controlling their initialization and destruction order, it can sometimes be easy, especially in a plugin architecture, to find some obscure case where, say, a plugin registered something to the system which, upon shutdown, wants to access something central after it has already been destroyed. This tends to happen easily if you have layers upon layers of abstractions and events going on during shutdown.
While the actual examples I've seen are much more subtle and varied than this, a very basic example I just made up so that we can keep the example revolving around undo systems is like an object in the scene wanting to write an undo event when it is destroyed so that it can be "restored" by the user on undo. Meanwhile that object type is registered through a plugin. When that plugin is unloaded, all instances that are still remaining of the object then get destroyed. We might then run into that hairy destruction order issue if the plugin manager unloads plugins after the undo system has already been destroyed.
It might be a non-issue for some people but my team used to struggle with this a lot in a former codebase with obscure shutdown crashes (and the reasons were often far more complex than the simple example above), and this makes it a non-issue because, for example, nothing is going to try to do anything with the undo system on shutdown, since nothing talks to the undo system.
Entity-Component Systems
What I've shown in some diagrams are entity-component systems (the undo system code also implies one) and that could be absolute overkill in your case. In my case I'm dealing with a software that is quite huge with a plugin architecture, embedded scripting, visual programming for things like particle systems and shaders, etc.
However, this general strategy of "inversion" to avoid depending on central object instances can be applied without going towards a full-blown entity component system. It's a very generalized strategy you can apply in many different ways.
As a very simple example, you might just create one central abstraction for scene objects like ISceneObject (or even an ABC) with a virtual transaction method. Then your undo system can loop through the polymorphic base pointers to ISceneObject* in your scene and call that virtual transaction method to retrieve a transaction object if one is available.
And of course you can apply this far beyond undo systems. You can apply this to your config manager and so forth, though you might need to keep something like a project manager if that's your "scene". Basically you need one central thing to access all the "scene" or "project" objects of interest in your software to apply this strategy.
With Singletons
I don't use singletons at all these days (came across designs where it's no longer even tempting to use them) but if you really feel the need, then I tended to find it helpful in past codebases to at least hide the gory details of accessing them and minimize unnecessary compile-time dependencies.
For example, instead of accessing the undo manager through CADApplication, you might do:
// In header:
// Returns the undo manager:
UndoManager& undoManager();
// Inside source file:
#include "CADApplication.h"
UndoManager& undoManager()
{
return *CADApplication::instance()->undoManager();
}
This might seem like a superfluous difference but it can at least slightly reduce the amount of compile-time dependencies you have since a part of your codebase might need access to your undo manager but not the full-blown application object, e.g. It's easier to start off depending on too little information and expand if needed than to start off depending on too much information and reduce in hindsight.
If you change your mind later on and want to move away from singletons and inject the proper things with access to the undo manager, e.g., then the header inclusions also tend to make it easier to figure out what needs what instead of everything including CADApplication.h and accessing whatever it needs from that.
Unit Testing
From your experience, which of these approaches should I stick to in
order to pursue good architecture and to make application error prone
and simplify unit testing?
For unit testing in general widely-depended upon object instances of a non-trivial kind (singletons or not) can be rather difficult to deal with since it's hard to reason about their states and whether you've thoroughly exhausted the edge cases for a particular interface you're testing (since the behavior of an object might vary if the central objects it depends on change in state).
If you call a function and pass it a wide range of parameters and it gives the correct output, it's hard to be sure that it will still do that if your singletons change in state. Specifically the problem is that if we have a function like this:
func(a, b)
Then this might be easy to test thoroughly because we can reason about what combos of a and b lead to different cases for func to handle. If it becomes a method, then that introduces one invisible (self/this) parameter:
// * denotes invisible parameter
method(*self, a, b)
... but that can still be quite easy to reason about if our object doesn't contain too much state that could impact method (however, even an object which depends on no others might be difficult to test if it has, say 25 eclectic member variables). And it's an invisible parameter but not exactly hidden. It becomes blatantly obvious when you call foo.method(...) that foo is an input to the function. But if we start injecting a lot of complex objects or if globals/singletons are depended upon, then we might have all sorts of genuinely hidden parameters that we might not even know are there unless we trace through the implementation of the function/method:
method(*self, a, b, *c, *d, *e, *f, *g, *h, *i, *j)
... and that can be really hard to test and reason about to see if we've even thoroughly exhausted all possible input/state combinations that lead to unique cases to handle. It's another reason I'd recommend this approach of turning your "managers" into "systems" and avoiding fanning in towards single object instances if your application reaches a sufficiently large scale.
Now the ECS I showed above which does have one uber central and generalized "ECS Manager" (albeit injected, not a singleton) might seem like it'd be no different, but the difference is that the ECS has no complex behavior of its own. It's rather trivial at least in the sense of not having any obscure edge cases. It's a generalized "database". It stores data in the form of components which systems read as input and use to output something.
Systems just use it to retrieve certain types of components and entities that contain them. As a result there generally aren't obscure edge cases to deal with, so often you can test everything by just generating the data for components a system needs to process (ex: transaction components if you're testing your undo system) to see if it works correctly. Surprisingly I've found the ECS to be easier to test over a former codebase (I originally had misgivings about attempting to use ECS in a visual FX domain which, as far as I know among all the big competitors, was never attempted before). The former codebase did use a few singletons but mostly still used DI for everything else. Yet the ECS was still easier to test since the only thing you need to do to test a system's correctness is create some component data of the type it's interested in as input (ex: audio components for an audio system) and make sure it provides the correct output after processing them.
The system-style organization of an ECS and the way they access components through the database make it explicitly clear and blatantly obvious what type of component types they process, so it's pretty easy to get thorough coverage without tripping on some obscure edge case. The key part is that it's blatantly obvious in spite of the dependencies to this central database. It's when it isn't so obvious that it becomes a tripping point.
Pros and Cons
Now as to whether my suggestions are suitable for your case, I can't say. This approach I'm suggesting definitely involves a little more work upfront, but can really pay off after reaching a certain scale. But it might be an alternative strategy to consider if you want to decouple these managers from the entire world as you walk that tightrope balancing act of designing an architecture. I have found it helped tremendously for the type of codebase and domain I work in. I'll attempt some pros and cons though I think even pros and cons are never divorced entirely from subjectivity, but I'll try to be as objective as I can:
Pros:
- Reduces coupling and minimizes information everything has to have about everything else.
- Makes large-scale systems easier to reason about. For example, it becomes really easy to reason about when/where central application undos are recorded when that occurs in one central place in an undo "system" reading from transaction components in the scene instead of having hundreds of places in the codebase trying to tell the undo "manager" what to record. Changes to application state become easier to understand and side effects become much more centralized. To me a litmus test for the ability for us to comprehend a large-scale codebase is not only comprehending what overall side effects need to occur, but when and where they occur. The "what' part can be a lot easier to comprehend than "when" and "where", and being confused about "when" and "where" is often a recipe for unwanted side effects when developers try to make changes. This proposal makes the "when/where" a lot more obvious even if the "what" is still the same.
- Often makes it easier to achieve thread-safety without sacrificing thread-efficiency.
- Makes working in a team easier with less toe-stepping due to the decoupling.
- Avoids those issues with dependency order for initialization and destruction.
- Simplifies unit testing by avoiding a lot of dependencies to a central object's state which could lead to obscure edge cases that can be overlooked in testing.
- Gives you more breathing room to make design changes without cascading breakages. For example, imagine how painful it would be to change your undo manager into one stored locally per project if you accumulated a codebase with a million lines of code depending on that one central one provided through the singleton.
Cons:
- Definitely takes some more work upfront. It's an "investment" mentality to reduce future maintenance costs, but the exchange will be higher costs upfront (though not that much higher if you ask me).
- Might be completely overkill for small applications. I would not bother with this for something really small. For applications of sufficiently small scale, I actually think there's a pragmatic argument to be made in favor of singletons and even plain old global variables sometimes since those teeny applications often benefit from creating their own global "environment", like being able to draw to the screen from anywhere or play audio from anywhere for a teeny video game that just uses one "screen" (window) just as we can output to the console from anywhere. It just tends to become problematic as you start moving towards medium and large-scale applications which want to stick around for a while and go through many upgrades, since they might want to replace the audio or rendering capabilities, they might become so large that it's difficult to tell where the bug resides if you see weird drawing artifacts, etc.
CADApplication.hin .cpp files, I think. And, by the way, subclassingQApplicationand re-using it is a sort of singleton too, but implemented differently. – Floorman