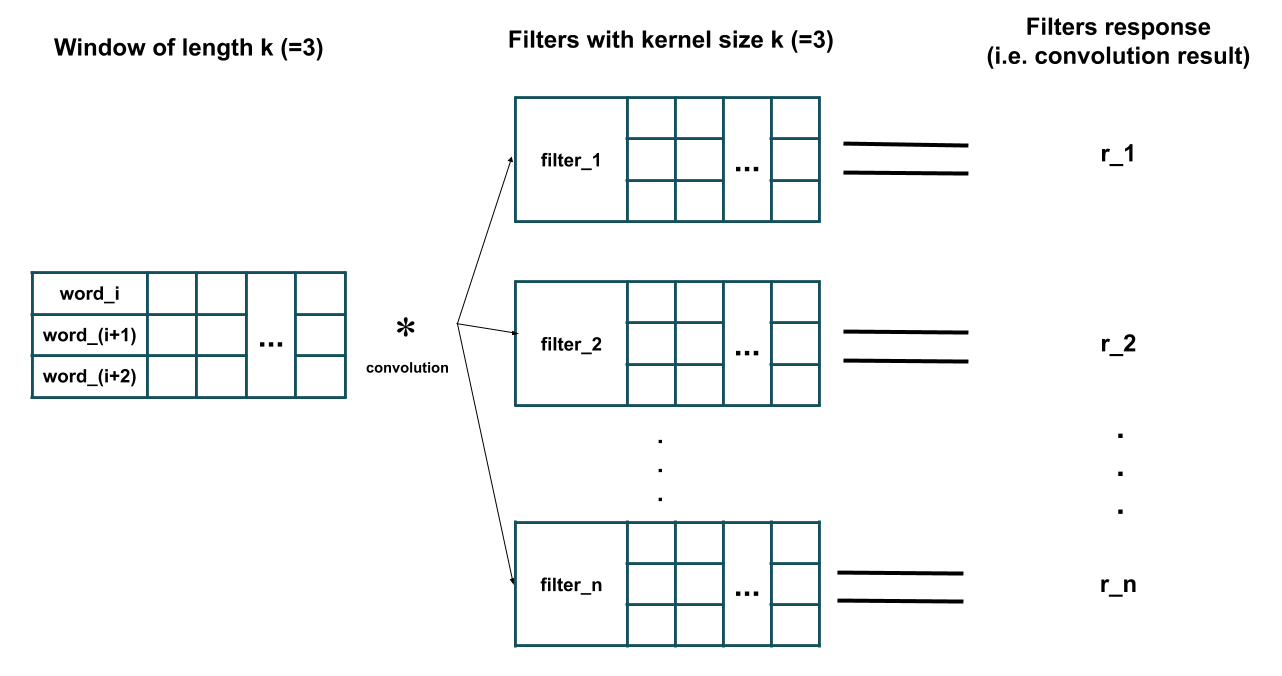
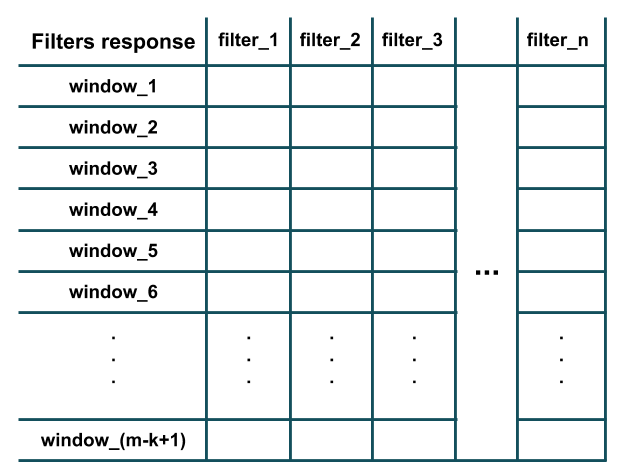
I am currently developing a text classification tool using Keras. It works (it works fine and I got up to 98.7 validation accuracy) but I can't wrap my head around about how exactly 1D-convolution layer works with text data.
What hyper-parameters should I use?
I have the following sentences (input data):
- Maximum words in the sentence: 951 (if it's less - the paddings are added)
- Vocabulary size: ~32000
- Amount of sentences (for training): 9800
- embedding_vecor_length: 32 (how many relations each word has in word embeddings)
- batch_size: 37 (it doesn't matter for this question)
- Number of labels (classes): 4
It's a very simple model (I have made more complicated structures but, strangely it works better - even without using LSTM):
model = Sequential()
model.add(Embedding(top_words, embedding_vecor_length, input_length=max_review_length))
model.add(Conv1D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(labels_count, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
My main question is: What hyper-parameters should I use for Conv1D layer?
model.add(Conv1D(filters=32, kernel_size=2, padding='same', activation='relu'))
If I have following input data:
- Max word count: 951
- Word-embeddings dimension: 32
Does it mean that filters=32 will only scan first 32 words completely discarding the rest (with kernel_size=2)? And I should set filters to 951 (max amount of words in the sentence)?
Examples on images:
So for instance this is an input data: http://joxi.ru/krDGDBBiEByPJA
It's the first step of a convoulution layer (stride 2): http://joxi.ru/Y2LB099C9dWkOr
It's the second step (stride 2): http://joxi.ru/brRG699iJ3Ra1m
And if filters = 32, layer repeats it 32 times? Am I correct?
So I won't get to say 156-th word in the sentence, and thus this information will be lost?