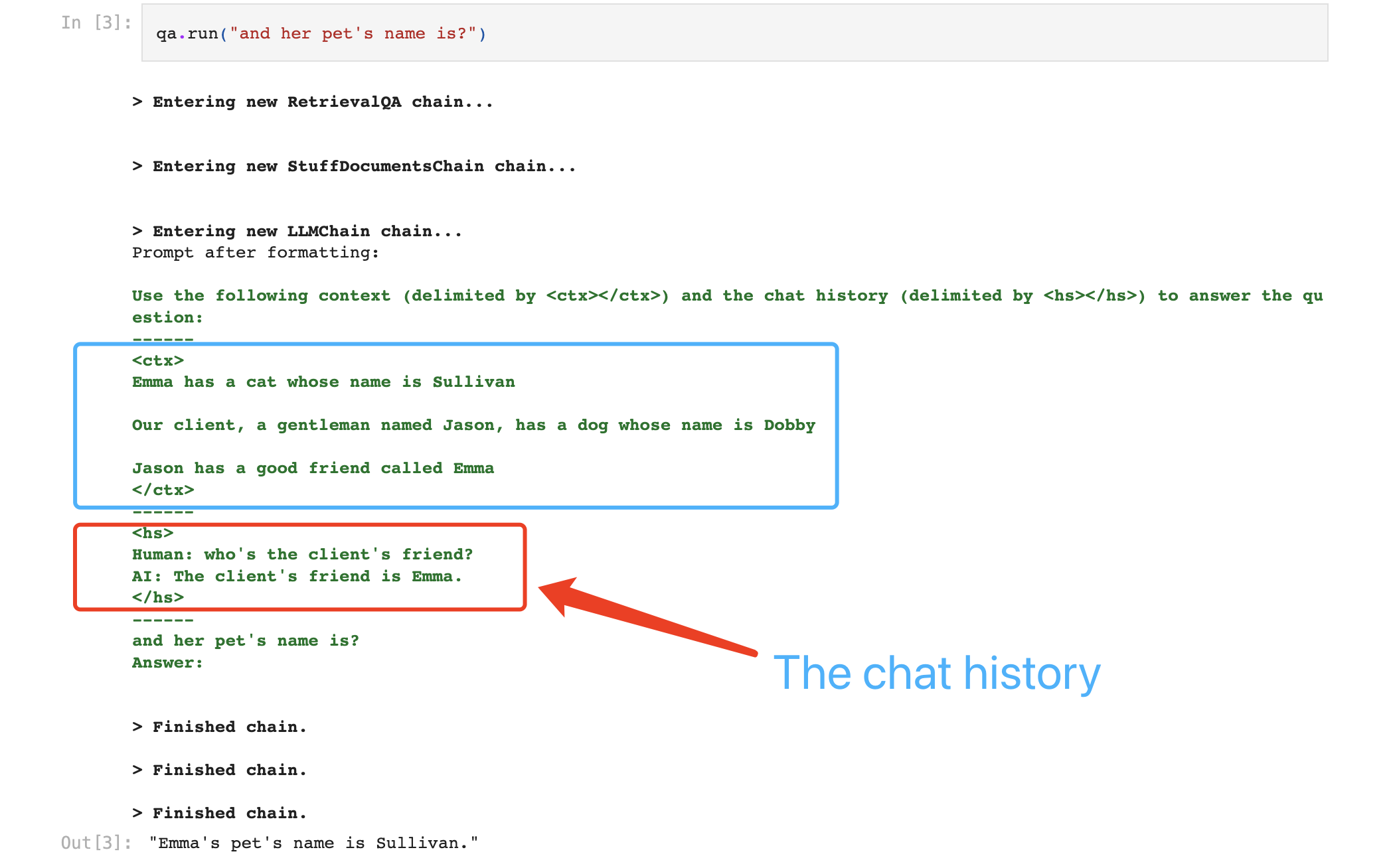
Here's a solution with ConversationalRetrievalChain, with memory and custom prompts, using the default 'stuff' chain type.
There are two prompts that can be customized here. First, the prompt that condenses conversation history plus current user input (condense_question_prompt), and second, the prompt that instructs the Chain on how to return a final response to the user (which happens in the combine_docs_chain).
from langchain import PromptTemplate
# note that the input variables ('question', etc) are defaults, and can be changed
condense_prompt = PromptTemplate.from_template(
('Do X with user input ({question}), and do Y with chat history ({chat_history}).')
)
combine_docs_custom_prompt = PromptTemplate.from_template(
('Write a haiku about a dolphin.\n\n'
'Completely ignore any context, such as {context}, or the question ({question}).')
)
Now we can initialize the ConversationalRetrievalChain with the custom prompts.
from langchain.llms import OpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
chain = ConversationalRetrievalChain.from_llm(
OpenAI(temperature=0),
vectorstore.as_retriever(), # see below for vectorstore definition
memory=memory,
condense_question_prompt=condense_prompt,
combine_docs_chain_kwargs=dict(prompt=combine_docs_custom_prompt)
)
Note that this calls _load_stuff_chain() under the hood, which allows for an optional prompt kwarg (that's what we can customize). This is used to set the LLMChain , which then goes to initialize the StuffDocumentsChain.
We can test the setup with a simple query to the vectorstore (see below for example vectorstore data) - you can see how the output is determined completely by the custom prompt:
chain("What color is mentioned in the document about cats?")['answer']
#'\n\nDolphin leaps in sea\nGraceful and playful in blue\nJoyful in the waves'
And memory is working correctly:
chain.memory
#ConversationBufferMemory(chat_memory=ChatMessageHistory(messages=[HumanMessage(content='What color is mentioned in the document about cats?', additional_kwargs={}), AIMessage(content='\n\nDolphin leaps in sea\nGraceful and playful in blue\nJoyful in the waves', additional_kwargs={})]), output_key=None, input_key=None, return_messages=True, human_prefix='Human', ai_prefix='AI', memory_key='chat_history')
Example vectorstore dataset with ephemeral ChromaDB instance:
from langchain.vectorstores import Chroma
from langchain.document_loaders import DataFrameLoader
from langchain.embeddings.openai import OpenAIEmbeddings
data = {
'index': ['001', '002', '003'],
'text': [
'title: cat friend\ni like cats and the color blue.',
'title: dog friend\ni like dogs and the smell of rain.',
'title: bird friend\ni like birds and the feel of sunshine.'
]
}
df = pd.DataFrame(data)
loader = DataFrameLoader(df, page_content_column="text")
docs = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(docs, embeddings)