I have a project that make use of Google Vision API DOCUMENT_TEXT_DETECTION in order to extract text from document images.
Often the API has troubles in recognizing single digits, as you can see in this image:
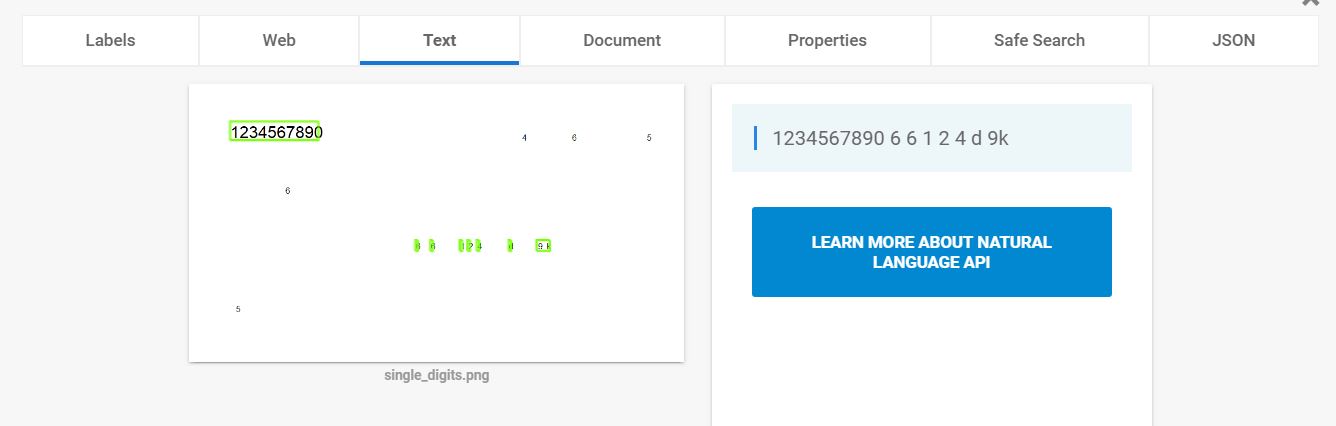
I suppose that the problem could be related to some algorithm of noise removal, that recognizes isolated single digits as noise. Is there a way to improve Vision response in these situations? (for example managing noise threshold or others parameters)
At other times Vision confuses digits with letters:
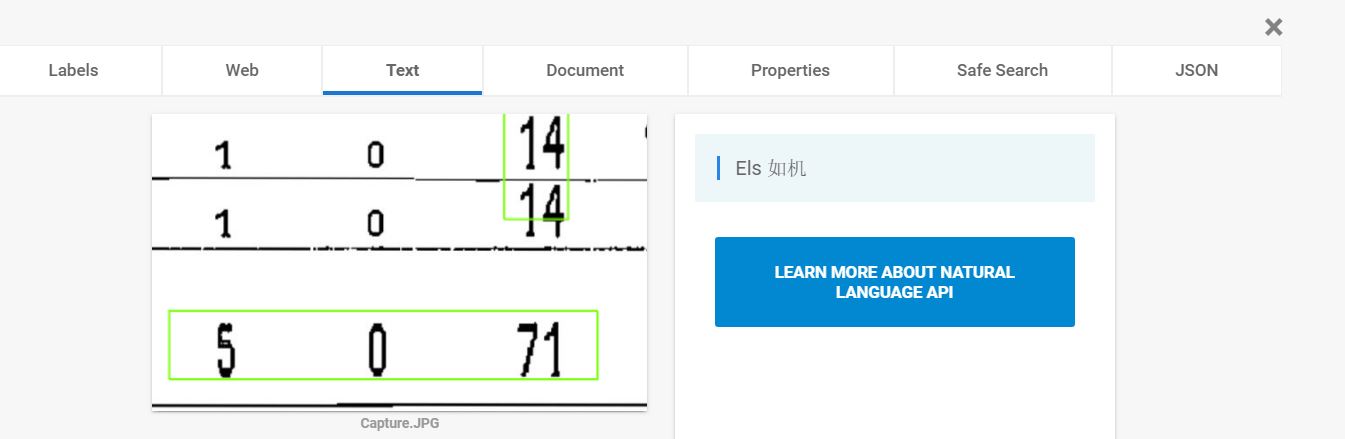
But if I specify as parameter languageHints = 'en' or 'mt' these digits are ignored by the ocr. Is there a way to force the recognition of digits or latin characters?
TEXT_DETECTION. As explained in the documentation,DOCUMENT_TEXT_DETECTIONis optimized for dense text. The images that you used seem not be the case. – Brister