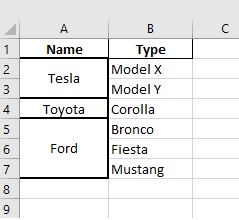
I'm trying to output a Pandas dataframe into an excel file using xlsxwriter. However I'm trying to apply some rule-based formatting; specifically trying to merge cells that have the same value, but having trouble coming up with how to write the loop. (New to Python here!)
See below for output vs output expected:

(As you can see based off the image above I'm trying to merge cells under the Name column when they have the same values).
Here is what I have thus far:
#This is the logic you use to merge cells in xlsxwriter (just an example)
worksheet.merge_range('A3:A4','value you want in merged cells', merge_format)
#Merge Car type Loop thought process...
#1.Loop through data frame where row n Name = row n -1 Name
#2.Get the length of the rows that have the same Name
#3.Based off the length run the merge_range function from xlsxwriter, worksheet.merge_range('range_found_from_loop','Name', merge_format)
for row_index in range(1,len(car_report)):
if car_report.loc[row_index, 'Name'] == car_report.loc[row_index-1, 'Name']
#find starting point based off index, then get range by adding number of rows to starting point. for example lets say rows 0-2 are similar I would get 'A0:A2' which I can then put in the code below
#from there apply worksheet.merge_range('A0:A2','[input value]', merge_format)
Any help is greatly appreciated!
Thank you!