I had a similar problem and want to provide an example with sample records.
WITH CTE AS (
SELECT Id, Name, Price FROM Duplicates
)
SELECT CTE.Id, CTE.Name, CTE.Price FROM CTE
INNER JOIN (SELECT Id, Name
FROM Duplicates
Group BY Id, Name
HAVING Count(*)>1
) as sq
ON CTE.Id = sq.Id
AND CTE.Name = sq.Name
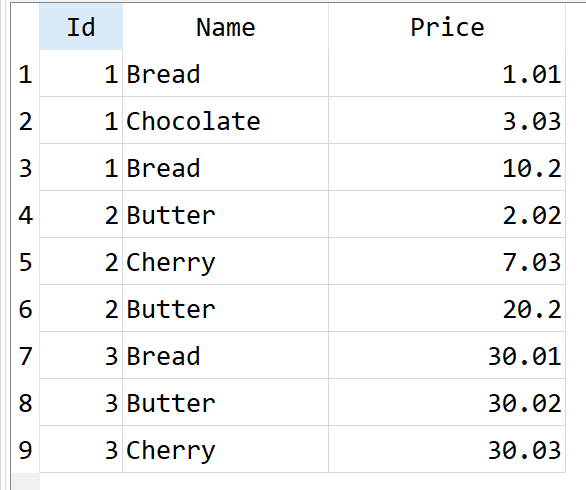
In the table Duplicates are multiple rows with Bread and Butter within the same Id
![Table Duplicate with repeated Name values for given id]()
only chocolate and cherry are unique for a given Id.
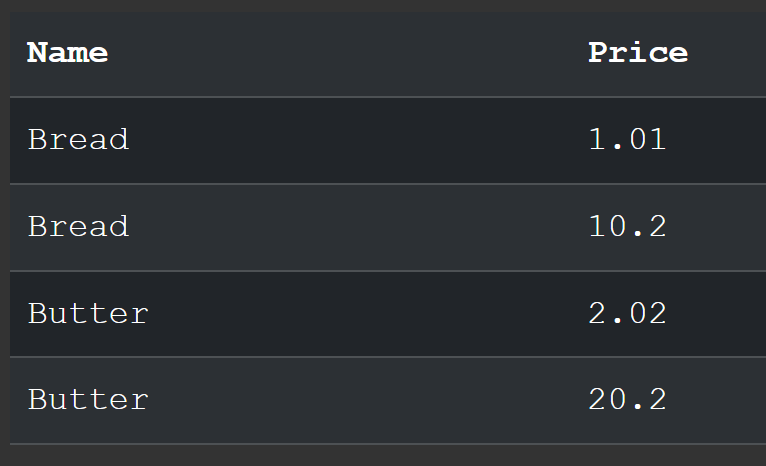
Take a look at the demo which should looks like this
![result of query]()
SQL statements to recreate the sample
Create the table
CREATE TABLE Duplicates
(
Id INTEGER,
Name TEXT,
Price REAL
);
Insert some records
INSERT INTO Duplicates (Id, Name, Price) VALUES (1, 'Bread', '1.01');
INSERT INTO Duplicates (Id, Name, Price) VALUES (1, 'Chocolate', '3.03');
INSERT INTO Duplicates (Id, Name, Price) VALUES (1, 'Bread', '10.20');
INSERT INTO Duplicates (Id, Name, Price) VALUES (2, 'Butter', '2.02');
INSERT INTO Duplicates (Id, Name, Price) VALUES (2, 'Cherry', '7.03');
INSERT INTO Duplicates (Id, Name, Price) VALUES (2, 'Butter', '20.20');
INSERT INTO Duplicates (Id, Name, Price) VALUES (3, 'Bread', '30.01');
INSERT INTO Duplicates (Id, Name, Price) VALUES (3, 'Butter', '30.02');
INSERT INTO Duplicates (Id, Name, Price) VALUES (3, 'Cherry', '30.03');