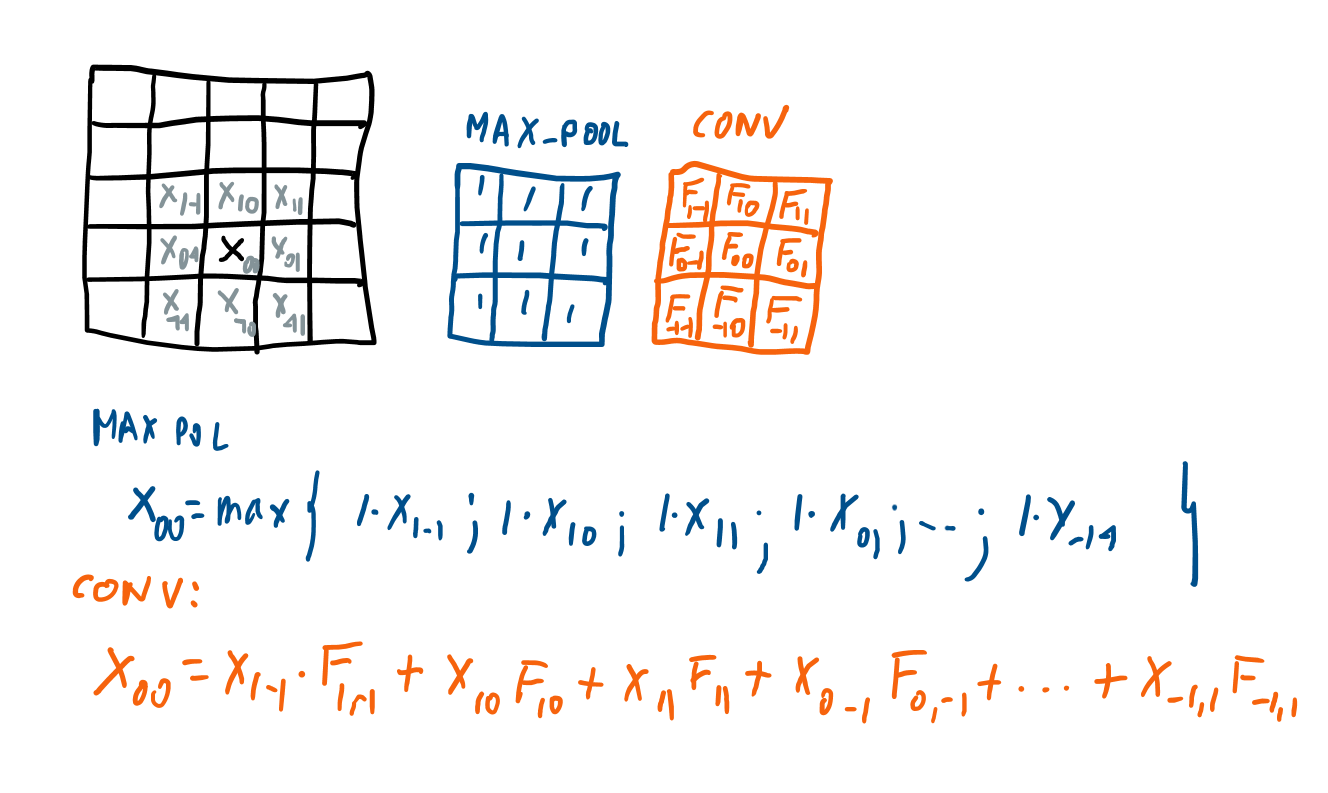The difference can be summarized in (1) how do you compute them and (2) what is used for.
- How do you compute them:
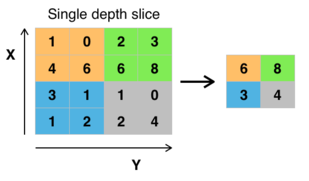
Take for example an input data that is a matrix (5x5) -think about an image of 5 by 5 pixels-. The pooling layer and the convolution layer are operations that are applied to each of the input "pixels". Let's take a pixel in the center of the image (to avoid to discuss what happens with the corners, will elaborate later) and define a "kernel" for both the pooling layer and the convolution layer of (3x3).
Pooling layer: you super-impose the pooling kernel on the input pixel (in the figure you put the center of the blue matrix on top of the black X_00, and take the maximum.
Convolutional layer: you super-impose the convolutional kernel on the input pixel (in the figure you put the center of the orange matrix on top of the black X_00) and then perform the element wise multiplication and then summation as indicated in the figure.
The convolution coefficients, F_.., where are they taken from ? they are learnt when training the network. For the maxpooling, you do not have to learn nothing, you take the maximum. You can consider the maxpooling is like a convolution but with fixed coefficients, and instead of summing, taking the maximum.
You perform this for each input element. What happens an the input image corners, depens on what your choice: discard the input elements at the sides/corners, pad, etc.. Also you can not move continuously, pixel by pixel, by jumping, etc...
- what is used for: max_pooling reduces the size of the input, and performs kind of summarization of the data, and at the same time provides some invariance to translational transformations (e.g. if the object moves left-right, up-down). convultion, depending on the conditions on the filter coefficients (e.g. a column must be negative, while other positive) can be regarded as filters allowing to extract some patterns, like vertical lines, horizontal lines, etc...
![input image, max_pool_kernel, conv_kernel]()