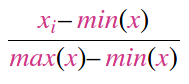I've looked everywhere but couldn't quite find what I want. Basically the MNIST dataset has images with pixel values in the range [0, 255]. People say that in general, it is good to do the following:
- Scale the data to the
[0,1]range. - Normalize the data to have zero mean and unit standard deviation
(data - mean) / std.
Unfortunately, no one ever shows how to do both of these things. They all subtract a mean of 0.1307 and divide by a standard deviation of 0.3081. These values are basically the mean and the standard deviation of the dataset divided by 255:
from torchvision.datasets import MNIST
import torchvision.transforms as transforms
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True)
print('Min Pixel Value: {} \nMax Pixel Value: {}'.format(trainset.data.min(), trainset.data.max()))
print('Mean Pixel Value {} \nPixel Values Std: {}'.format(trainset.data.float().mean(), trainset.data.float().std()))
print('Scaled Mean Pixel Value {} \nScaled Pixel Values Std: {}'.format(trainset.data.float().mean() / 255, trainset.data.float().std() / 255))
This outputs the following
Min Pixel Value: 0
Max Pixel Value: 255
Mean Pixel Value 33.31002426147461
Pixel Values Std: 78.56748962402344
Scaled Mean: 0.13062754273414612
Scaled Std: 0.30810779333114624
However clearly this does none of the above! The resulting data 1) will not be between [0, 1] and will not have mean 0 or std 1. In fact this is what we are doing:
[data - (mean / 255)] / (std / 255)
which is very different from this
[(scaled_data) - (mean/255)] / (std/255)
where scaled_data is just data / 255.