I want to solve Ax = b where A is a very large square positive definite symmetric block matrix and x and b are vectors. When I say large I mean for a nxn matrix an n as large as 300,000.
Here is an example of a much smaller but representative matrix I want to solve.
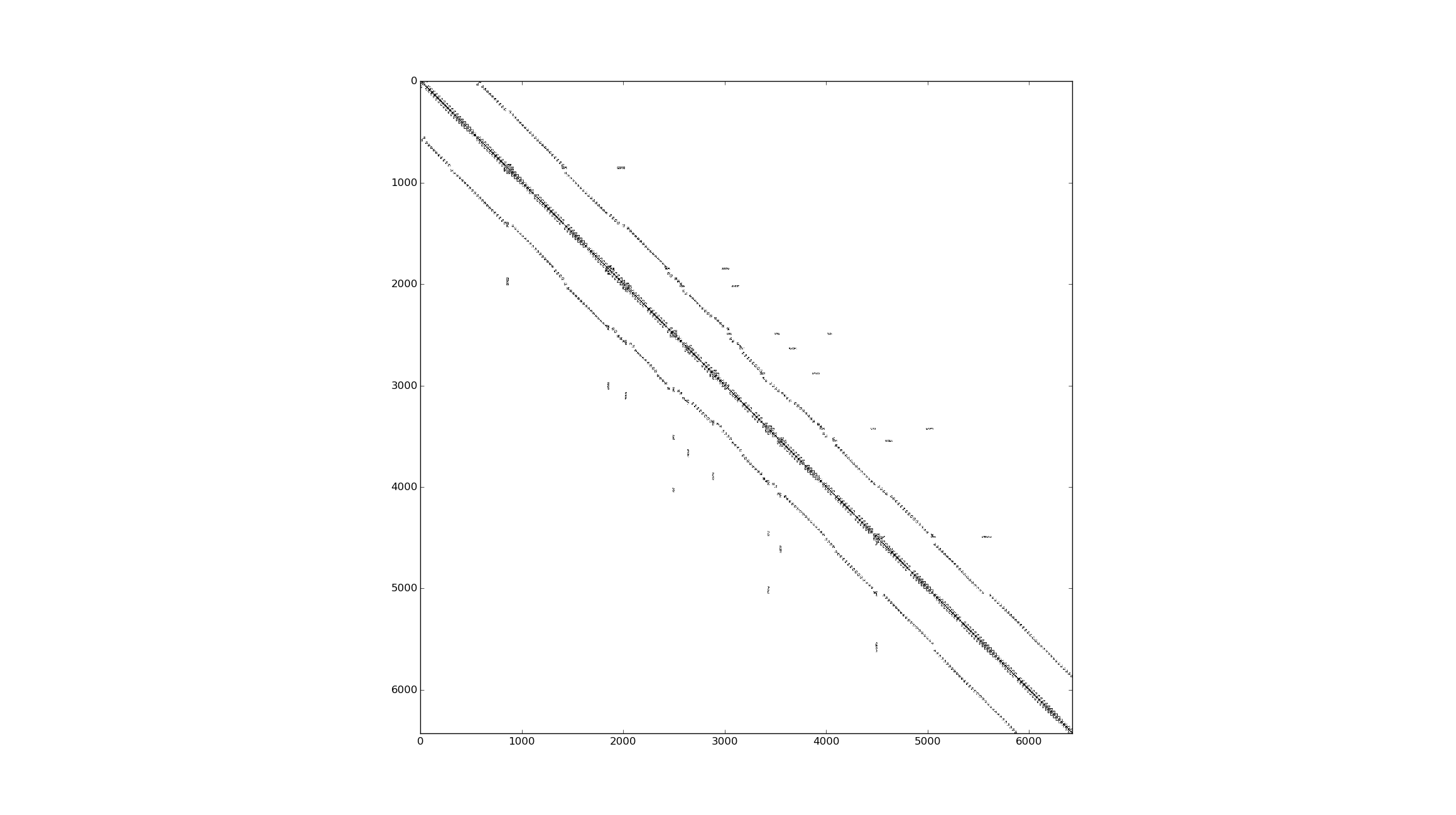
And here is the same matrix zoomed in showing that it is composed of blocks of dense matricies.
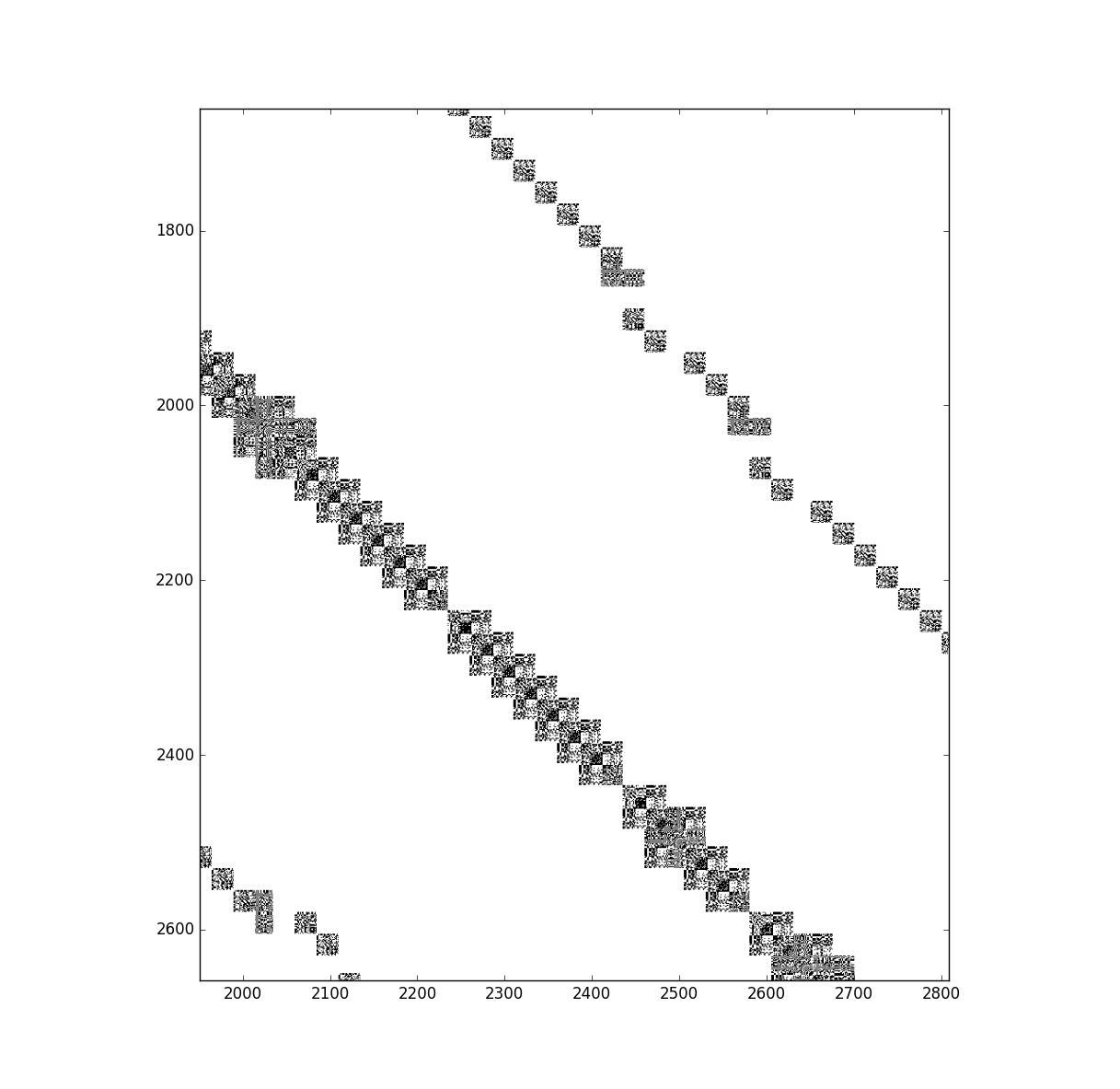
I previously (see here, here, and as far back as here) used Eigen's Cholesky solver which worked fine for n<10000 but with with n=300000 the Cholesky solver is too slow. However, I did not take advantage of the fact the I have a block matrix. Apparently, there exists algorithms for solving sparse block matrices (e.g. block cholesky factorization).
I would like to know specifically if Eigen has optimized algorithms, using factorization or iterative methods, for sparse dense block matrices which I can employ?
Also can you suggest other algorithms which might be ideal to solve my matrix? I mean as far as I understand at least for factorization finding a permutation matrix is NP hard so many different heuristic methods exist and as far as I can tell people build up an intuition of different matrix structures (e.g. banded matrix) and what algorithms work best with them. I don't have this intuition yet.
I am currently looking into using a conjugate gradient method. I have implemented this myself in C++ but still not taking advantage of the fact that the matrix is a block matrix.
//solve A*rk = xk
//Eigen::SparseMatrix<double> A;
//Eigen::VectorXd rk(n);
Eigen::VectorXd pk = rk;
double rsold = rk.dot(rk);
int maxiter = rk.size();
for (int k = 0; k < maxiter; k++) {
Eigen::VectorXd Ap = A*pk;
double ak = rsold /pk.dot(Ap);
xk += ak*pk, rk += -ak*Ap;
double rsnew = rk.dot(rk);
double xlength = sqrt(xk.dot(xk));
//relaxing tolerance when x is large
if (sqrt(rsnew) < std::max(std::min(tolerance * 10000, tolerance * 10 * xlength), tolerance)) {
rsold = rsnew;
break;
}
double bk = rsnew / rsold;
pk *= bk;
pk += rk;
rsold = rsnew;
}
unsupported / Eigen / src / SparseExtra / BlockSparseMatrix.h, not sure it still compile, but it used to work withConjugateGradient<>. Let us (i.e., Eigen's developers) known if you make any progress. – Prather