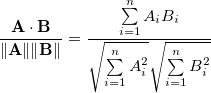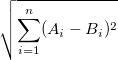I have been reading the papers on Word2Vec (e.g. this one), and I think I understand training the vectors to maximize the probability of other words found in the same contexts.
However, I do not understand why cosine is the correct measure of word similarity. Cosine similarity says that two vectors point in the same direction, but they could have different magnitudes.
For example, cosine similarity makes sense comparing bag-of-words for documents. Two documents might be of different length, but have similar distributions of words.
Why not, say, Euclidean distance?
Can anyone one explain why cosine similarity works for word2Vec?