I'm running Ignite in a Kubernetes cluster with persistence enabled. Each machine has a Java Heap of 24GB with 20GB devoted to durable memory with a memory limit of 110GB. My relevant JVM options are -XX:+AlwaysPreTouch -XX:+UseG1GC -XX:+ScavengeBeforeFullGC. After running DataStreamers on every node for several hours, nodes on my cluster hit their k8s memory limit triggering an OOM kill. After running Java NMT, I was surprised to find a huge amount of space allocated to internal memory.
Java Heap (reserved=25165824KB, committed=25165824KB)
(mmap: reserved=25165824KB, committed=25165824KB)
Internal (reserved=42425986KB, committed=42425986KB)
(malloc=42425954KB #614365)
(mmap: reserved=32KB, committed=32KB)
Kubernetes metrics confirmed this:
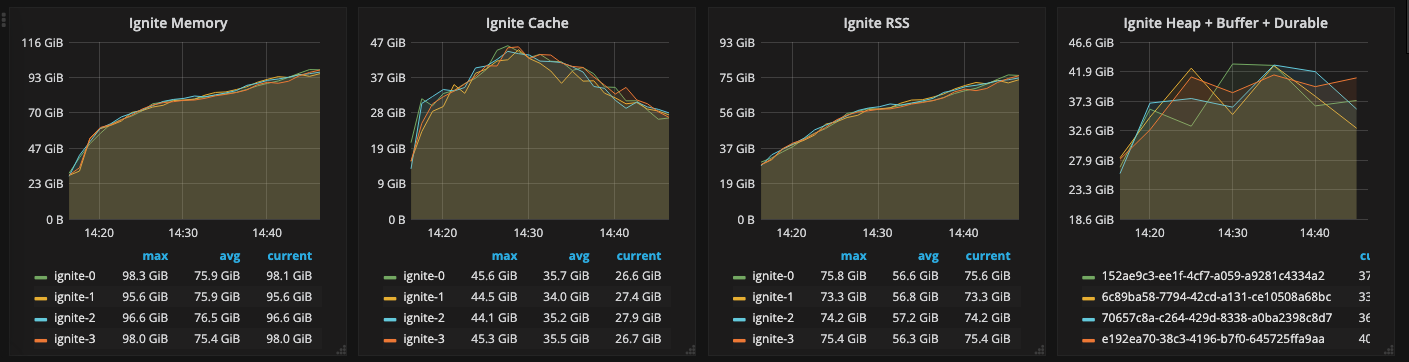
"Ignite Cache" is kernel page cache. The last panel "Heap + Durable + Buffer" is the sum of the ignite metrics HeapMemoryUsed + PhysicalMemorySize + CheckpointBufferSize.
I knew this couldn't be a result of data build-up because the DataStreamers are flushed after each file they read (up to about 250MB max), and no node is reading more than 4 files at once. After ruling out other issues on my end, I tried setting -XX:MaxDirectMemorySize=10G, and invoking manual GC, but nothing seems to have an impact other than periodically shutting down all of my pods and restarting them.
I'm not sure where to go from here. Is there a workaround in Ignite that doesn't force me to use a third-party database?
EDIT: My DataStorageConfiguration
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="metricsEnabled" value="true"/>
<property name="checkpointFrequency" value="300000"/>
<property name="storagePath" value="/var/lib/ignite/data/db"/>
<property name="walFlushFrequency" value="10000"/>
<property name="walMode" value="LOG_ONLY"/>
<property name="walPath" value="/var/lib/ignite/data/wal"/>
<property name="walArchivePath" value="/var/lib/ignite/data/wal/archive"/>
<property name="walSegmentSize" value="2147483647"/>
<property name="maxWalArchiveSize" value="4294967294"/>
<property name="walCompactionEnabled" value="false"/>
<property name="writeThrottlingEnabled" value="False"/>
<property name="pageSize" value="4096"/>
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
<property name="checkpointPageBufferSize" value="2147483648"/>
<property name="name" value="Default_Region"/>
<property name="maxSize" value="21474836480"/>
<property name="metricsEnabled" value="true"/>
</bean>
</property>
</bean>
</property>
UPDATE: When I disable persistence, internal memory is properly disposed of:
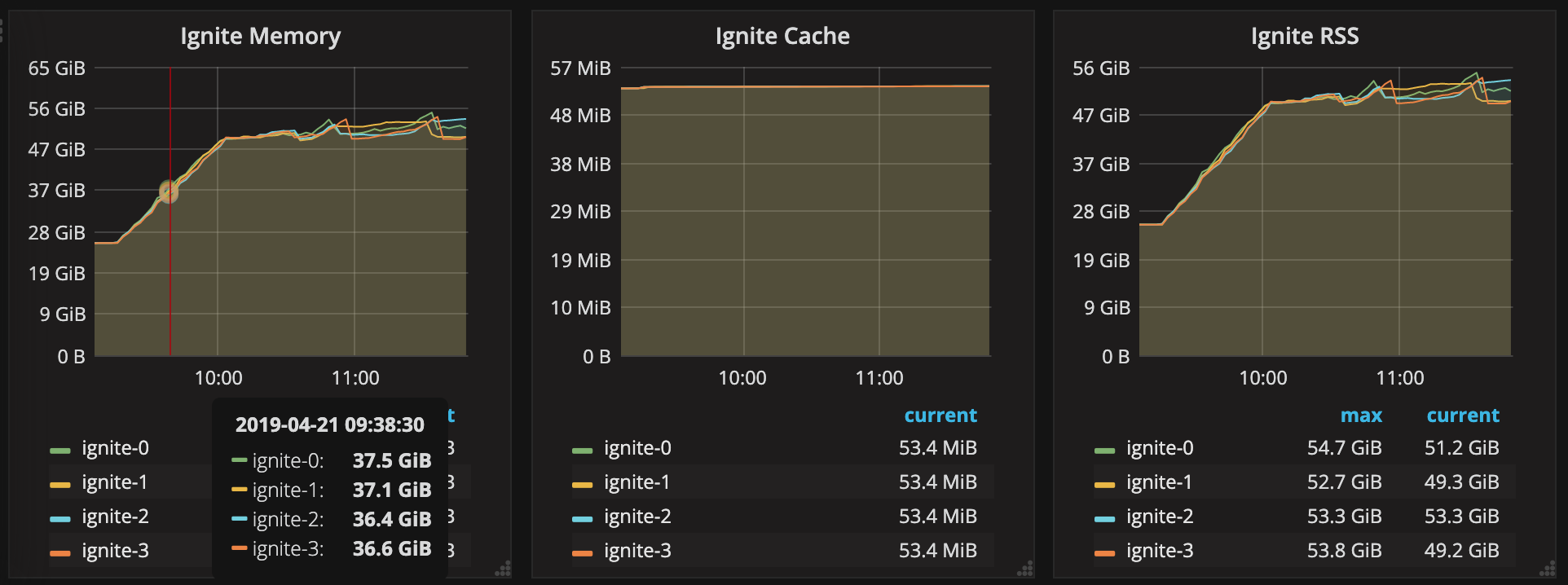
UPDATE: The issue is demonstrated here with a reproducible example. It's runnable on a machine with at least 22GB of memory for docker and about 50GB of storage. Interestingly the leak is only really noticeable when passing in a Byte Array or String as the value.