I am creating a parser for the .one file extension, which when finished I will add to the Apache Tika project.
Here is the APL 2.0 licensed Open Source project I'm creating: https://github.com/nddipiazza/onenote-parser-java
I used the specification document here: https://learn.microsoft.com/en-us/openspecs/office_file_formats/ms-one/73d22548-a613-4350-8c23-07d15576be50
As a starting point, I ported over the code from this open source C++ project: https://github.com/dropbox/onenote-parser
I have gotten a long way in the parsing of the documents, but I've hit a road block.
Here is the OneNote file I'm using to parse: https://drive.google.com/file/d/1uROTEnKeBKU08CG_K5zdDTGHa178LgBK/view?usp=sharing

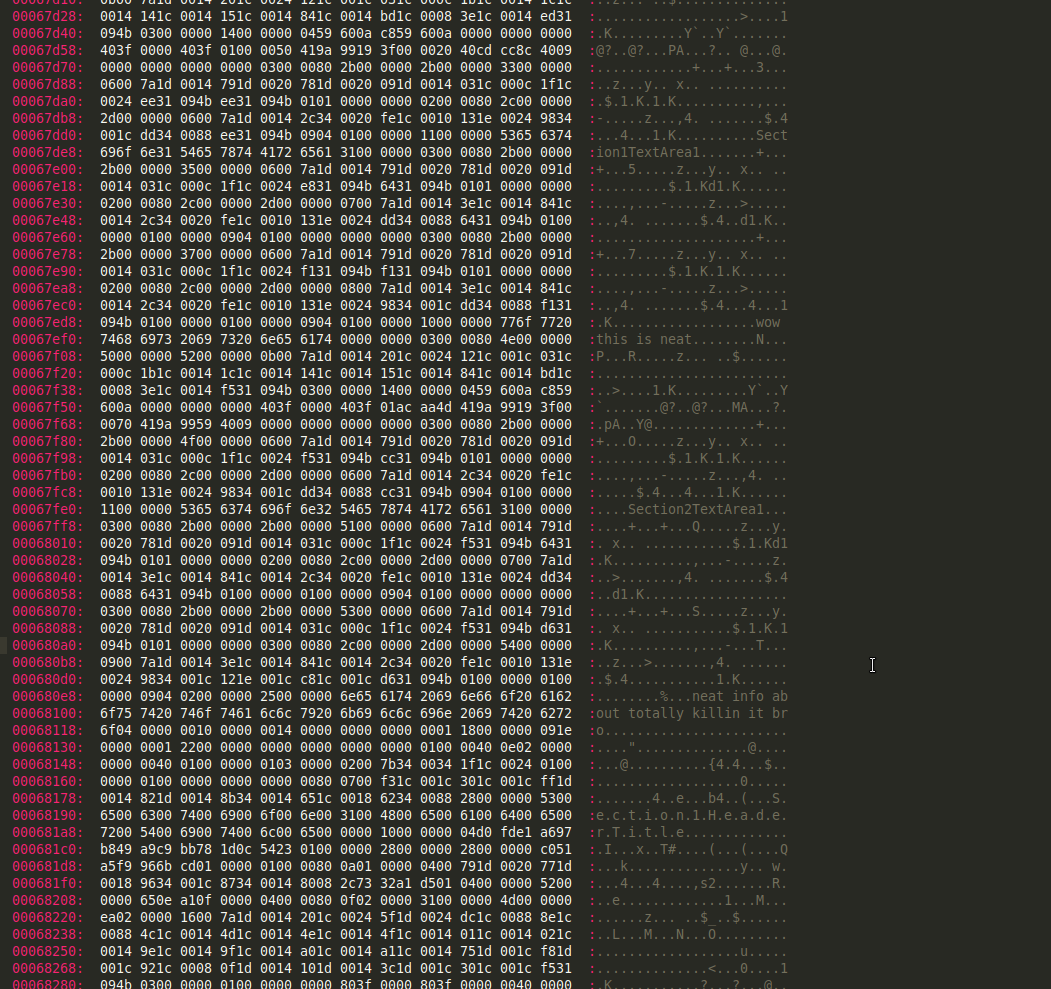
I am unable to view the Section1TextArea1 and Section1TextArea2 in my parsed results. So I'm missing some sort of key data parsing element or something.
It is definitely in the OneNote file itself. I can see it in the Hex viewer:
Here is the JSON parse output: https://gist.github.com/nddipiazza/02d2252d357b3b02a6b9ab1050474267
I feel like the spec document is missing some very important information needed in order to parse this proprietary format.
What major element(s) am I missing resulting in me not getting the actual text content?