After going through a large amount of the PDF Spec and many PDFBox examples I was able to fix all issues reported by PAC 2. There were several steps involved to create the verified PDF (with a complex table structure) and the full source code is available here on github. I will attempt to do an overview of the major portions of the code below. (Some method calls will not be explained here!)
Step 1 (Setup metadata)
Various setup info like document title and language
//Setup new document
pdf = new PDDocument();
acroForm = new PDAcroForm(pdf);
pdf.getDocumentInformation().setTitle(title);
//Adjust other document metadata
PDDocumentCatalog documentCatalog = pdf.getDocumentCatalog();
documentCatalog.setLanguage("English");
documentCatalog.setViewerPreferences(new PDViewerPreferences(new COSDictionary()));
documentCatalog.getViewerPreferences().setDisplayDocTitle(true);
documentCatalog.setAcroForm(acroForm);
documentCatalog.setStructureTreeRoot(structureTreeRoot);
PDMarkInfo markInfo = new PDMarkInfo();
markInfo.setMarked(true);
documentCatalog.setMarkInfo(markInfo);
Embed all fonts directly into resources.
//Set AcroForm Appearance Characteristics
PDResources resources = new PDResources();
defaultFont = PDType0Font.load(pdf,
new PDTrueTypeFont(PDType1Font.HELVETICA.getCOSObject()).getTrueTypeFont(), true);
resources.put(COSName.getPDFName("Helv"), defaultFont);
acroForm.setNeedAppearances(true);
acroForm.setXFA(null);
acroForm.setDefaultResources(resources);
acroForm.setDefaultAppearance(DEFAULT_APPEARANCE);
Add XMP Metadata for PDF/UA spec.
//Add UA XMP metadata based on specs at https://taggedpdf.com/508-pdf-help-center/pdfua-identifier-missing/
XMPMetadata xmp = XMPMetadata.createXMPMetadata();
xmp.createAndAddDublinCoreSchema();
xmp.getDublinCoreSchema().setTitle(title);
xmp.getDublinCoreSchema().setDescription(title);
xmp.createAndAddPDFAExtensionSchemaWithDefaultNS();
xmp.getPDFExtensionSchema().addNamespace("http://www.aiim.org/pdfa/ns/schema#", "pdfaSchema");
xmp.getPDFExtensionSchema().addNamespace("http://www.aiim.org/pdfa/ns/property#", "pdfaProperty");
xmp.getPDFExtensionSchema().addNamespace("http://www.aiim.org/pdfua/ns/id/", "pdfuaid");
XMPSchema uaSchema = new XMPSchema(XMPMetadata.createXMPMetadata(),
"pdfaSchema", "pdfaSchema", "pdfaSchema");
uaSchema.setTextPropertyValue("schema", "PDF/UA Universal Accessibility Schema");
uaSchema.setTextPropertyValue("namespaceURI", "http://www.aiim.org/pdfua/ns/id/");
uaSchema.setTextPropertyValue("prefix", "pdfuaid");
XMPSchema uaProp = new XMPSchema(XMPMetadata.createXMPMetadata(),
"pdfaProperty", "pdfaProperty", "pdfaProperty");
uaProp.setTextPropertyValue("name", "part");
uaProp.setTextPropertyValue("valueType", "Integer");
uaProp.setTextPropertyValue("category", "internal");
uaProp.setTextPropertyValue("description", "Indicates, which part of ISO 14289 standard is followed");
uaSchema.addUnqualifiedSequenceValue("property", uaProp);
xmp.getPDFExtensionSchema().addBagValue("schemas", uaSchema);
xmp.getPDFExtensionSchema().setPrefix("pdfuaid");
xmp.getPDFExtensionSchema().setTextPropertyValue("part", "1");
XmpSerializer serializer = new XmpSerializer();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
serializer.serialize(xmp, baos, true);
PDMetadata metadata = new PDMetadata(pdf);
metadata.importXMPMetadata(baos.toByteArray());
pdf.getDocumentCatalog().setMetadata(metadata);
Step 2 (Setup document tag structure)
You will need to add the root structure element and all necessary structure elements as children to the root element.
//Adds a DOCUMENT structure element as the structure tree root.
void addRoot() {
PDStructureElement root = new PDStructureElement(StandardStructureTypes.DOCUMENT, null);
root.setAlternateDescription("The document's root structure element.");
root.setTitle("PDF Document");
pdf.getDocumentCatalog().getStructureTreeRoot().appendKid(root);
currentElem = root;
rootElem = root;
}
Each marked content element (text and background graphics) will need to have an MCID and an associated tag for reference in the parent tree which will be explained in step 3.
//Assign an id for the next marked content element.
private void setNextMarkedContentDictionary(String tag) {
currentMarkedContentDictionary = new COSDictionary();
currentMarkedContentDictionary.setName("Tag", tag);
currentMarkedContentDictionary.setInt(COSName.MCID, currentMCID);
currentMCID++;
}
Artifacts (background graphics) will not be detected by the screen reader. Text needs to be detectable so a P structure element is used here when adding text.
//Set up the next marked content element with an MCID and create the containing TD structure element.
PDPageContentStream contents = new PDPageContentStream(
pdf, pages.get(pageIndex), PDPageContentStream.AppendMode.APPEND, false);
currentElem = addContentToParent(null, StandardStructureTypes.TD, pages.get(pageIndex), currentRow);
//Make the actual cell rectangle and set as artifact to avoid detection.
setNextMarkedContentDictionary(COSName.ARTIFACT.getName());
contents.beginMarkedContent(COSName.ARTIFACT, PDPropertyList.create(currentMarkedContentDictionary));
//Draws the cell itself with the given colors and location.
drawDataCell(table.getCell(i, j).getCellColor(), table.getCell(i, j).getBorderColor(),
x + table.getRows().get(i).getCellPosition(j),
y + table.getRowPosition(i),
table.getCell(i, j).getWidth(), table.getRows().get(i).getHeight(), contents);
contents.endMarkedContent();
currentElem = addContentToParent(COSName.ARTIFACT, StandardStructureTypes.P, pages.get(pageIndex), currentElem);
contents.close();
//Draw the cell's text as a P structure element
contents = new PDPageContentStream(
pdf, pages.get(pageIndex), PDPageContentStream.AppendMode.APPEND, false);
setNextMarkedContentDictionary(COSName.P.getName());
contents.beginMarkedContent(COSName.P, PDPropertyList.create(currentMarkedContentDictionary));
//... Code to draw actual text...//
//End the marked content and append it's P structure element to the containing TD structure element.
contents.endMarkedContent();
addContentToParent(COSName.P, null, pages.get(pageIndex), currentElem);
contents.close();
Annotation Widgets (form objects in this case) will need to be nested within Form structure elements.
//Add a radio button widget.
if (!table.getCell(i, j).getRbVal().isEmpty()) {
PDStructureElement fieldElem = new PDStructureElement(StandardStructureTypes.FORM, currentElem);
radioWidgets.add(addRadioButton(
x + table.getRows().get(i).getCellPosition(j) -
radioWidgets.size() * 10 + table.getCell(i, j).getWidth() / 4,
y + table.getRowPosition(i),
table.getCell(i, j).getWidth() * 1.5f, 20,
radioValues, pageIndex, radioWidgets.size()));
fieldElem.setPage(pages.get(pageIndex));
COSArray kArray = new COSArray();
kArray.add(COSInteger.get(currentMCID));
fieldElem.getCOSObject().setItem(COSName.K, kArray);
addWidgetContent(annotationRefs.get(annotationRefs.size() - 1), fieldElem, StandardStructureTypes.FORM, pageIndex);
}
//Add a text field in the current cell.
if (!table.getCell(i, j).getTextVal().isEmpty()) {
PDStructureElement fieldElem = new PDStructureElement(StandardStructureTypes.FORM, currentElem);
addTextField(x + table.getRows().get(i).getCellPosition(j),
y + table.getRowPosition(i),
table.getCell(i, j).getWidth(), table.getRows().get(i).getHeight(),
table.getCell(i, j).getTextVal(), pageIndex);
fieldElem.setPage(pages.get(pageIndex));
COSArray kArray = new COSArray();
kArray.add(COSInteger.get(currentMCID));
fieldElem.getCOSObject().setItem(COSName.K, kArray);
addWidgetContent(annotationRefs.get(annotationRefs.size() - 1), fieldElem, StandardStructureTypes.FORM, pageIndex);
}
Step 3
After all content elements have been written to the content stream and tag structure has been setup, it is necessary to go back and add the parent tree to the structure tree root. Note: Some method calls (addWidgetContent() and addContentToParent()) in the above code setup the necessary COSDictionary objects.
//Adds the parent tree to root struct element to identify tagged content
void addParentTree() {
COSDictionary dict = new COSDictionary();
nums.add(numDictionaries);
for (int i = 1; i < currentStructParent; i++) {
nums.add(COSInteger.get(i));
nums.add(annotDicts.get(i - 1));
}
dict.setItem(COSName.NUMS, nums);
PDNumberTreeNode numberTreeNode = new PDNumberTreeNode(dict, dict.getClass());
pdf.getDocumentCatalog().getStructureTreeRoot().setParentTreeNextKey(currentStructParent);
pdf.getDocumentCatalog().getStructureTreeRoot().setParentTree(numberTreeNode);
}
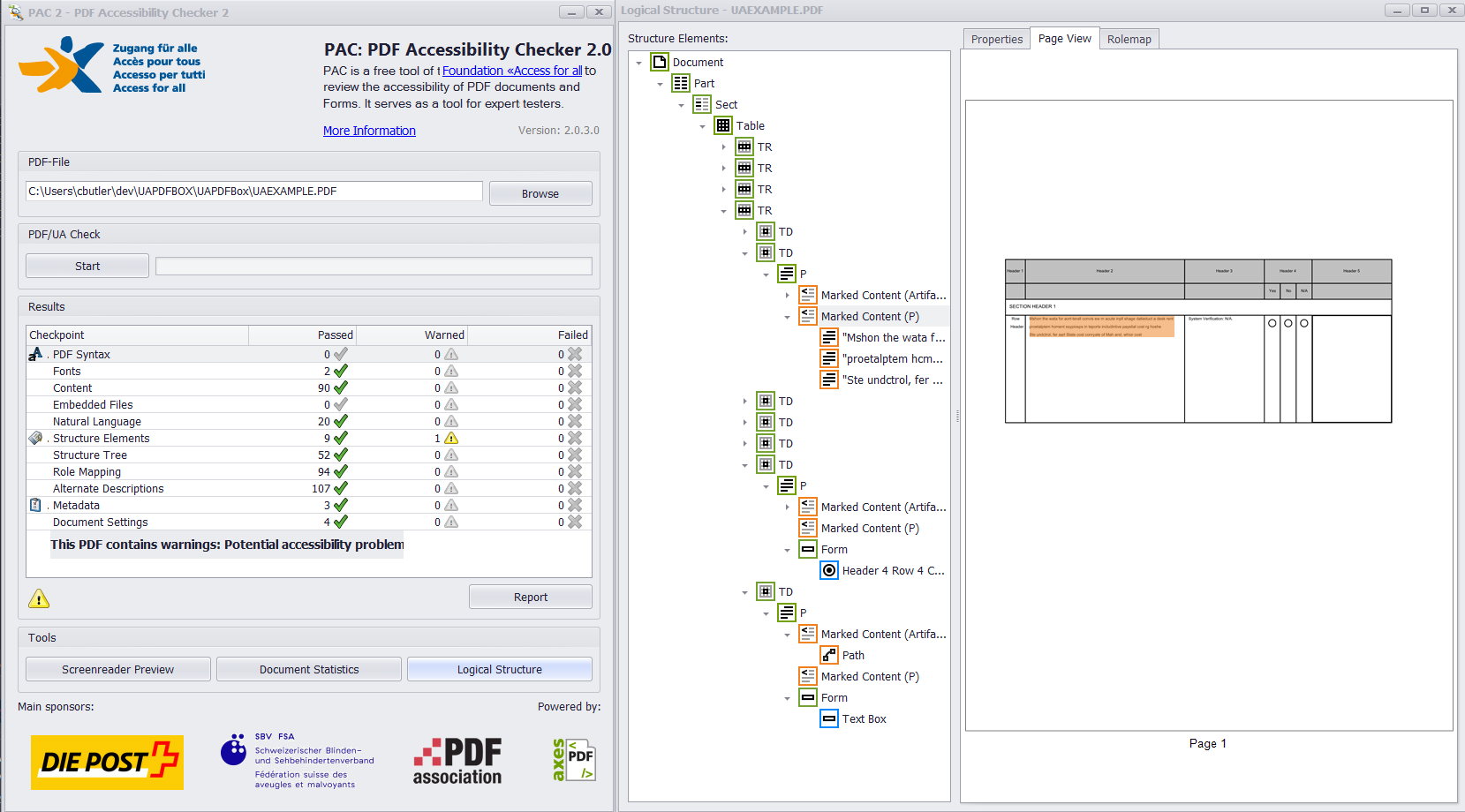
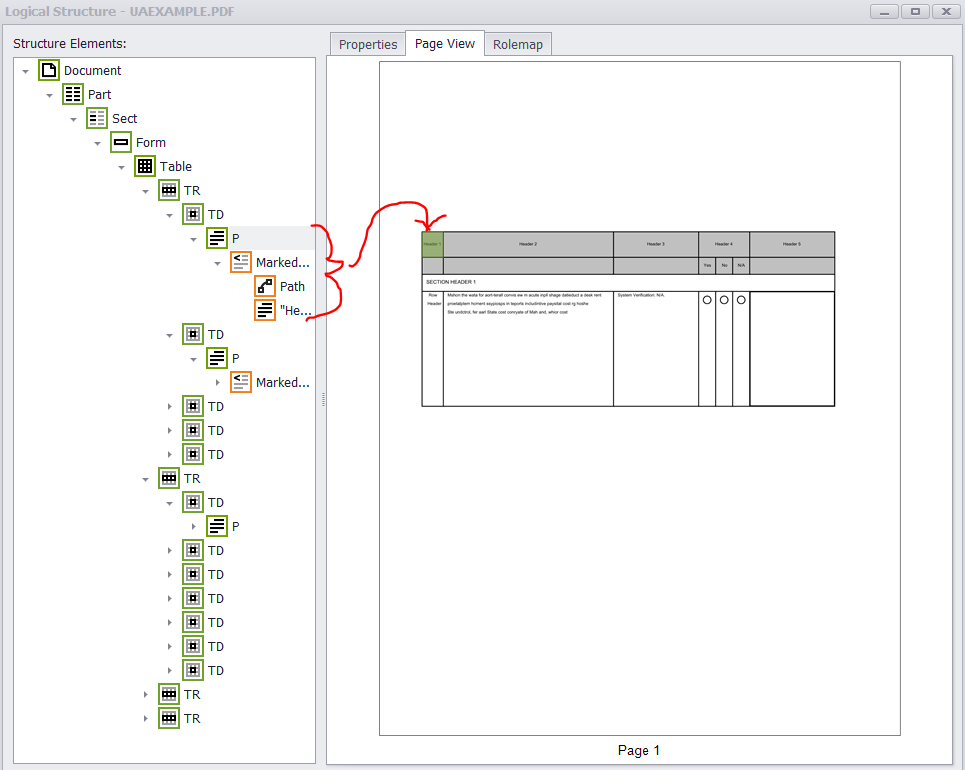
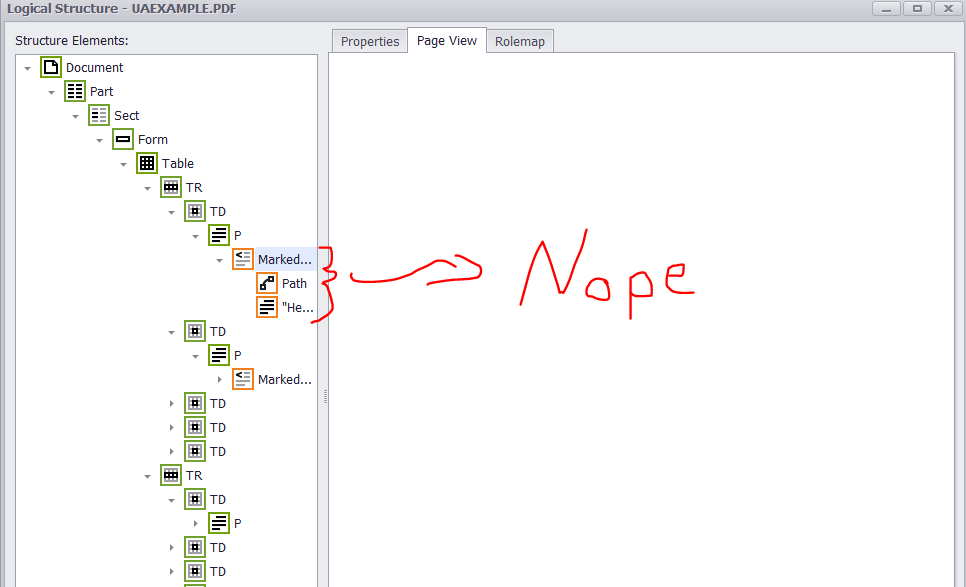
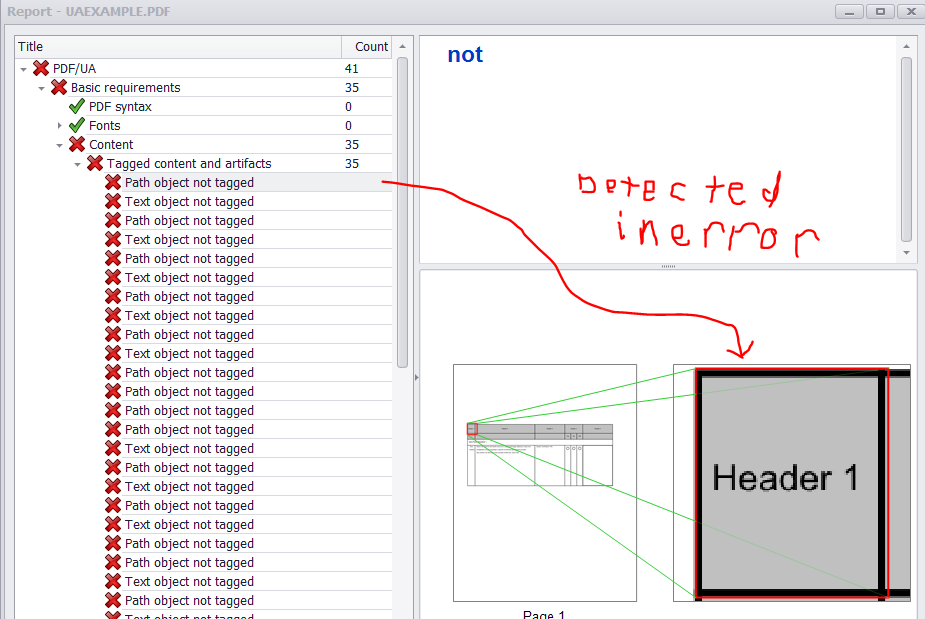
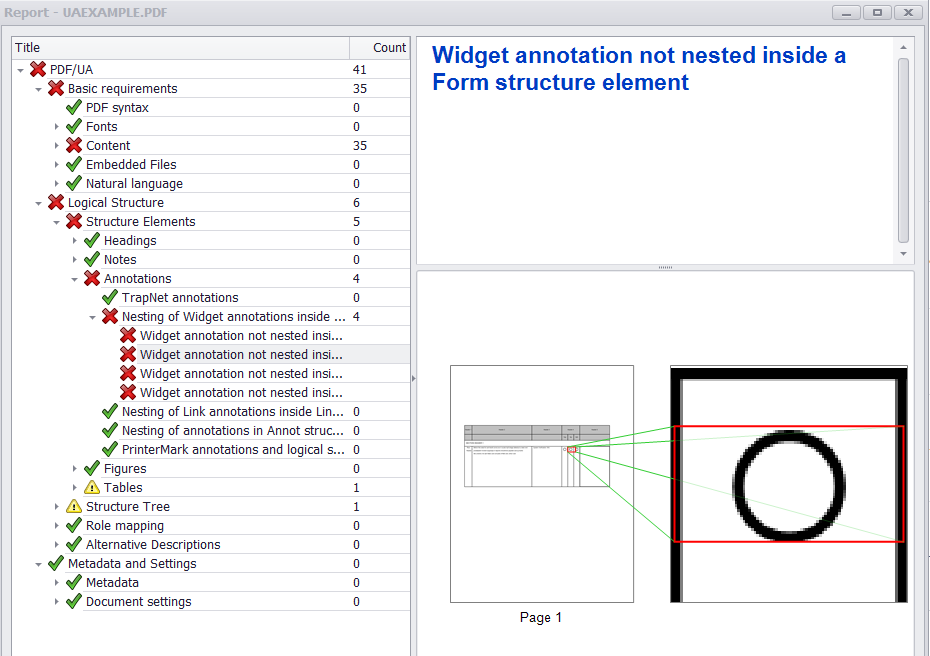
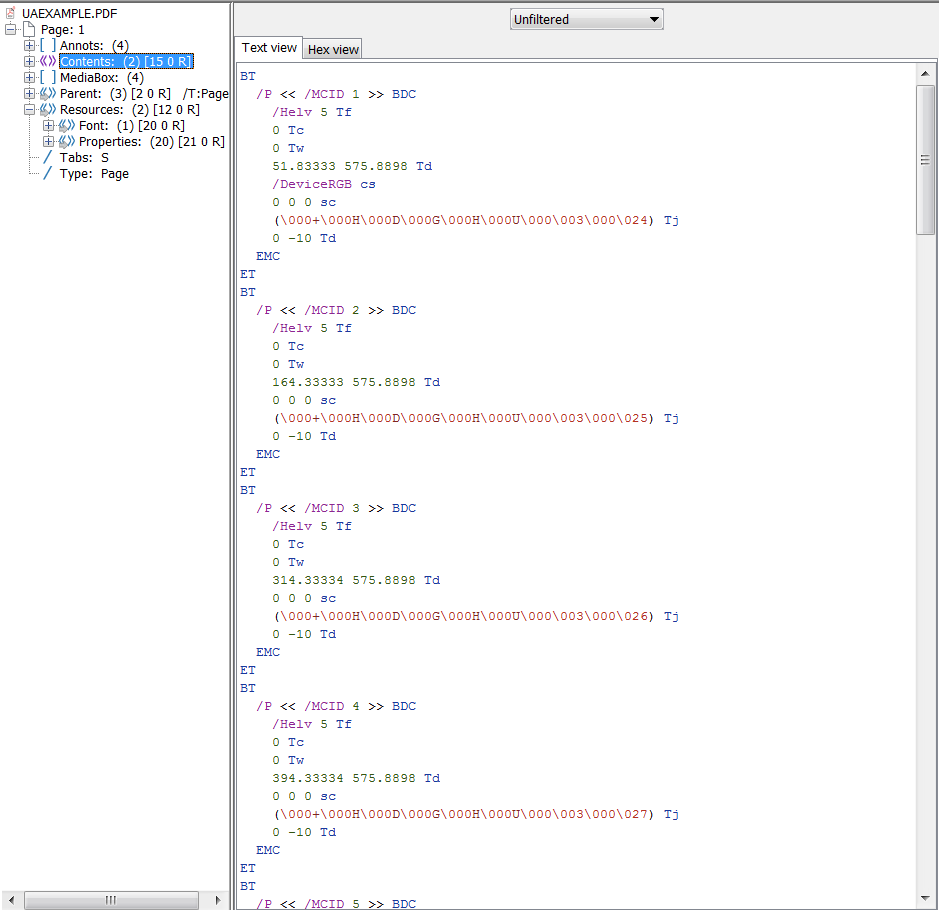
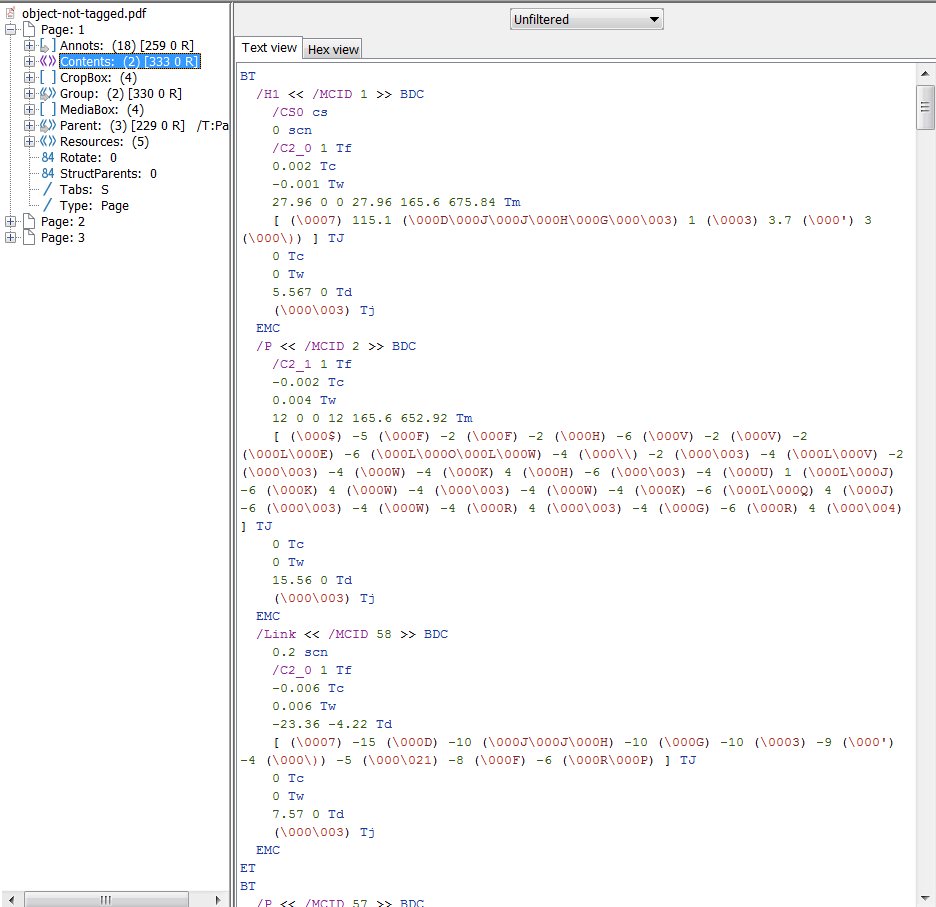
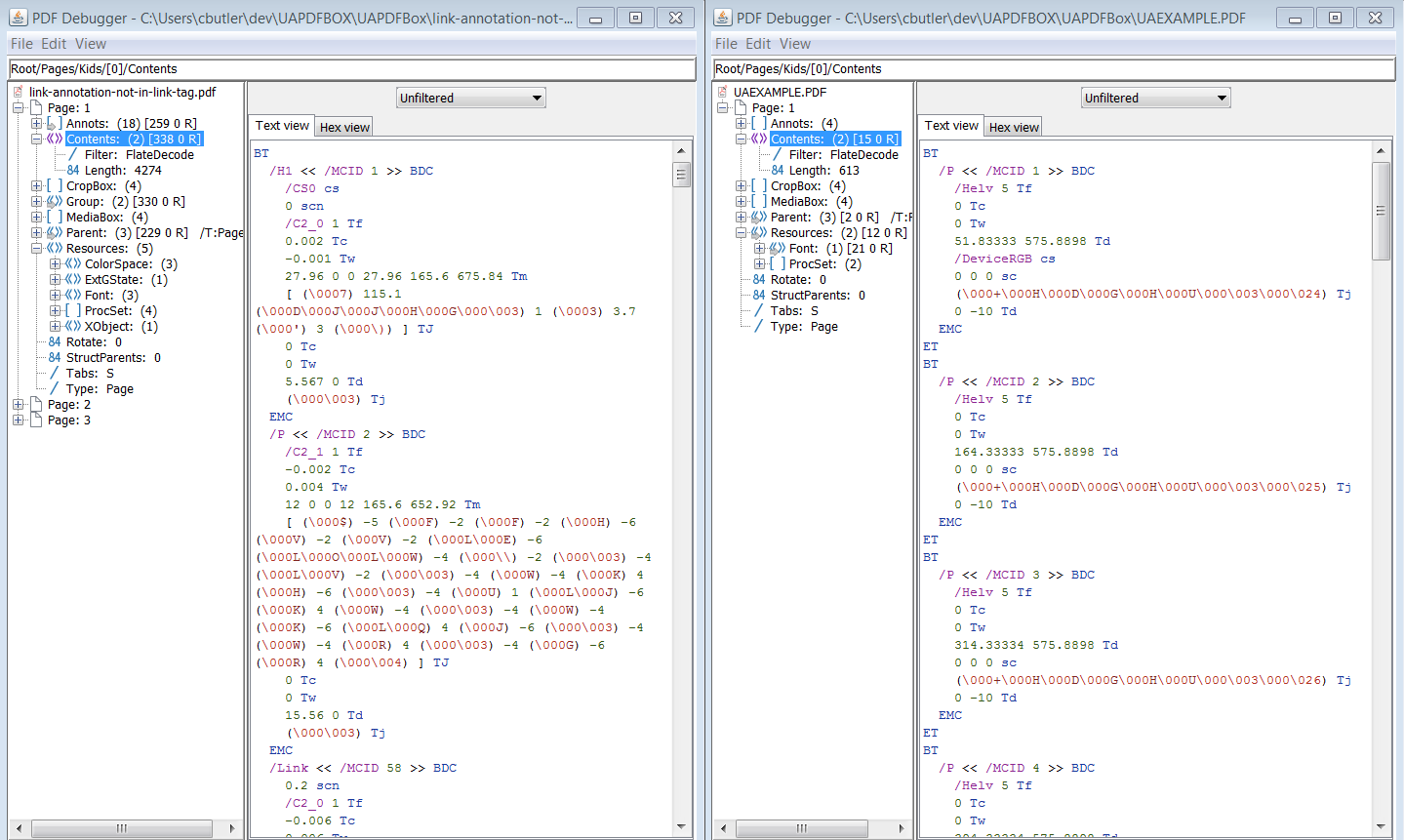
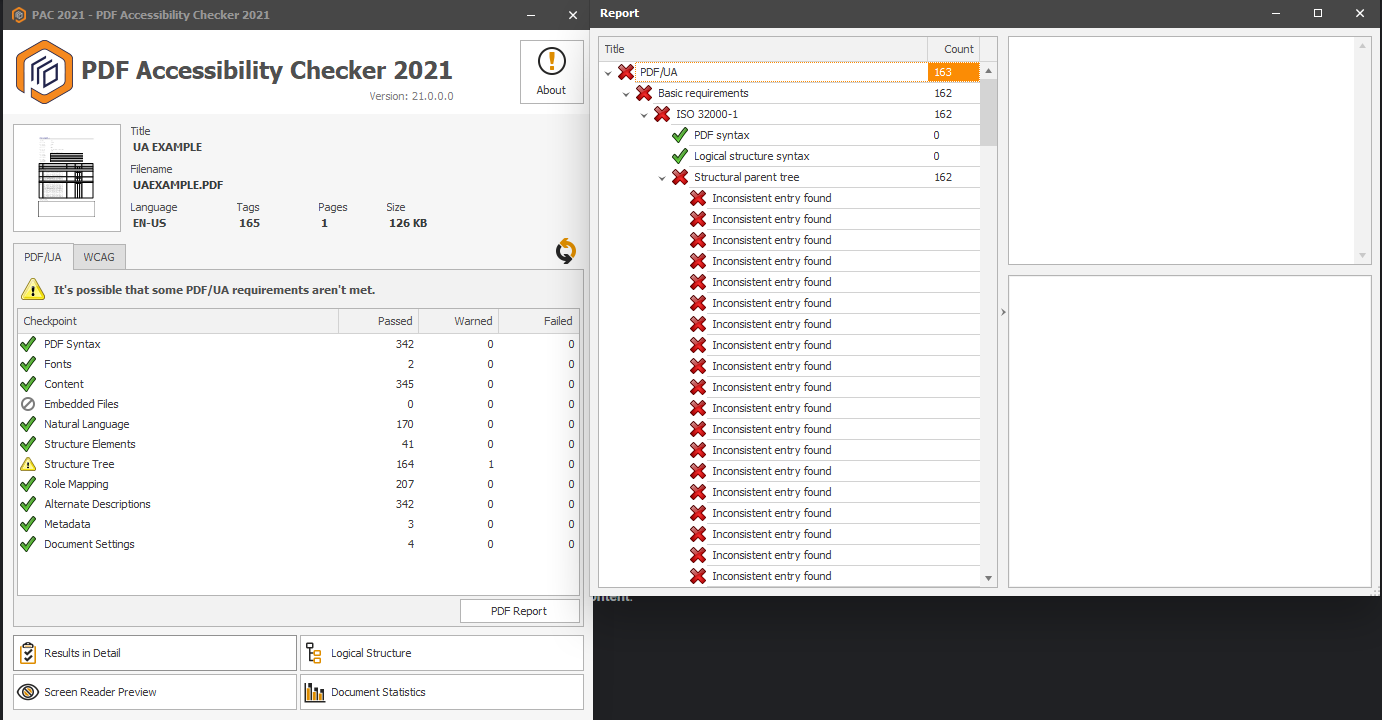
If all widget annotations and marked content were added correctly to the structure tree and parent tree then you should get something like this from PAC 2 and PDFDebugger.
![Verified PDF]()
![Debugger]()
Thank you to Tilman Hausherr for pointing me in the right direction to solve this! I will most likely make some edits to this answer for additional clarity as recommended by others.
Edit 1:
If you want to have a table structure like the one I have generated you will also need to add correct table markup to fully comply with the 508 standard... The 'Scope', 'ColSpan', 'RowSpan', or 'Headers' attributes will need to be correctly added to each table cell structure element similar to this or this. The main purpose for this markup is to allow a screen reading software like JAWS to read the table content in an understandable way. These attributes can be added in a similar way as below...
private void addTableCellMarkup(Cell cell, int pageIndex, PDStructureElement currentRow) {
COSDictionary cellAttr = new COSDictionary();
cellAttr.setName(COSName.O, "Table");
if (cell.getCellMarkup().isHeader()) {
currentElem = addContentToParent(null, StandardStructureTypes.TH, pages.get(pageIndex), currentRow);
currentElem.getCOSObject().setString(COSName.ID, cell.getCellMarkup().getId());
if (cell.getCellMarkup().getScope().length() > 0) {
cellAttr.setName(COSName.getPDFName("Scope"), cell.getCellMarkup().getScope());
}
if (cell.getCellMarkup().getColspan() > 1) {
cellAttr.setInt(COSName.getPDFName("ColSpan"), cell.getCellMarkup().getColspan());
}
if (cell.getCellMarkup().getRowSpan() > 1) {
cellAttr.setInt(COSName.getPDFName("RowSpan"), cell.getCellMarkup().getRowSpan());
}
} else {
currentElem = addContentToParent(null, StandardStructureTypes.TD, pages.get(pageIndex), currentRow);
}
if (cell.getCellMarkup().getHeaders().length > 0) {
COSArray headerA = new COSArray();
for (String s : cell.getCellMarkup().getHeaders()) {
headerA.add(new COSString(s));
}
cellAttr.setItem(COSName.getPDFName("Headers"), headerA);
}
currentElem.getCOSObject().setItem(COSName.A, cellAttr);
}
Be sure to do something like currentElem.setAlternateDescription(currentCell.getText()); on each of the structure elements with text marked content for JAWS to read the text.
Note: Each of the fields (radio button and textbox) will need a unique name to avoid setting multiple field values. GitHub has been updated with a more complex example PDF with table markup and improved form fields!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}