that's true...
one example is below:
C program:
int f,g,y;//global variables
int sum(int a, int b){
return (a+b);
}
int main(void){
f = 2;
g = 3;
y = sum(f, g);
return y;
}
compile to assembly:
00008390 <sum>:
int sum(int a, int b) {
return (a + b);
}
8390: e0800001 add r0, r0, r1
8394: e12fff1e bx lr
00008398 <main>:
int f, g, y; // global variables
int sum(int a, int b);
int main(void) {
8398: e92d4008 push {r3, lr}
f = 2;
839c: e3a00002 mov r0, #2
83a0: e59f301c ldr r3, [pc, #28] ; 83c4 <main+0x2c>
83a4: e5830000 str r0, [r3]
g = 3;
83a8: e3a01003 mov r1, #3
83ac: e59f3014 ldr r3, [pc, #20] ; 83c8 <main+0x30>
83b0: e5831000 str r1, [r3]
y = sum(f,g);
83b4: ebfffff5 bl 8390 <sum>
83b8: e59f300c ldr r3, [pc, #12] ; 83cc <main+0x34>
83bc: e5830000 str r0, [r3]
return y;
}
83c0: e8bd8008 pop {r3, pc}
83c4: 00010570 .word 0x00010570
83c8: 00010574 .word 0x00010574
83cc: 00010578 .word 0x00010578
see the above LDR's PC value--here is used to load variable f,g,y's address to r3.
83a0: e59f301c ldr r3, [pc, #28];83c4 main+0x2c
PC=0x83c4-28=0x83a8-0x1C = 0x83a8
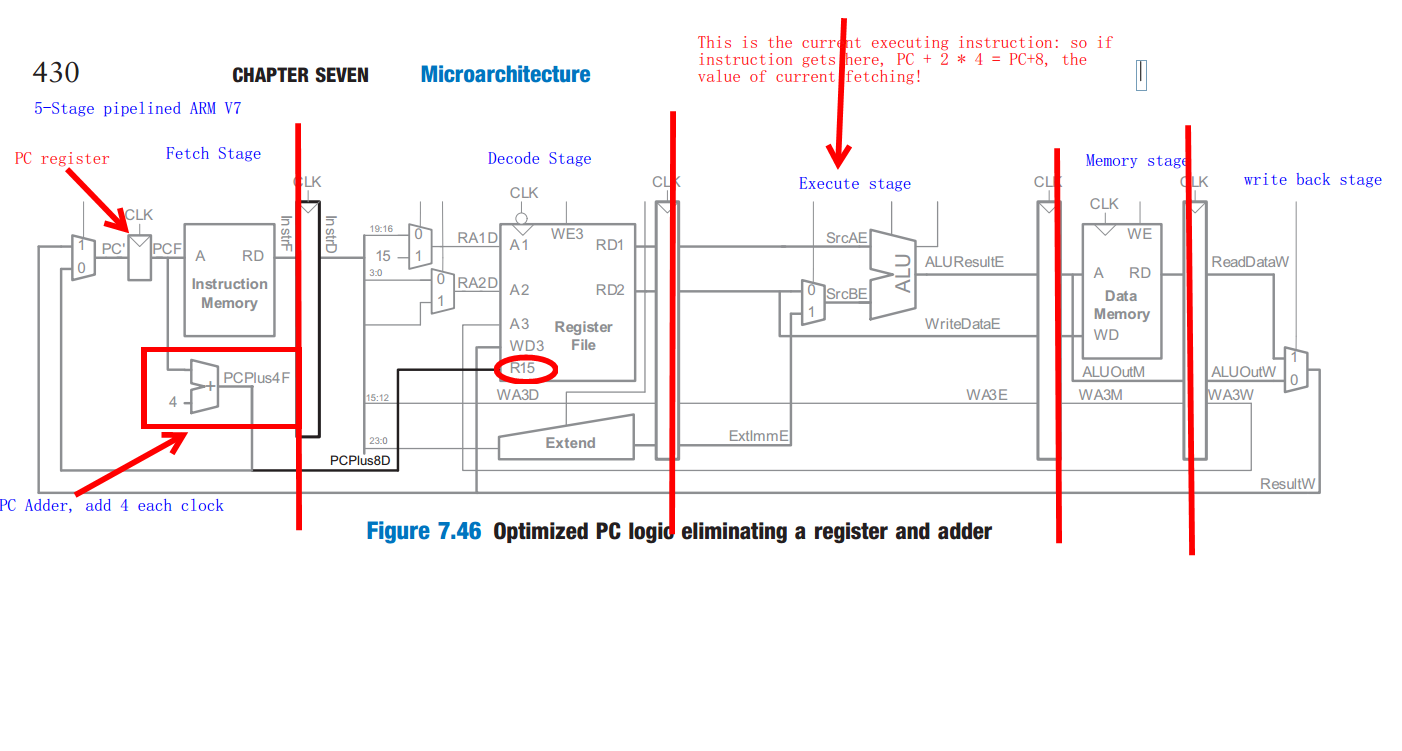
PC's value is just the current executing instruction's next's next instruction. as ARM uses 32bits instruction, but it's using byte address, so + 8 means 8bytes, two instructions' length.
so attached ARM archi's 5 stage pipe linefetch, decode, execute, memory, writeback
ARM's 5 stage pipeline
the PC register is added by 4 each clock, so when instruction bubbled to execute--the current instruction, PC register's already 2 clock passed! now it's + 8. that actually means: PC points the "fetch" instruction, current instruction means "execute" instruction, so PC means the next next to be executed.
BTW:
the pic is from Harris's book of Digital Design and Computer Architecture ARM Edition
{kind=link}
lea rax, [rip]. On x86-32, the most direct way is probably with acallinstruction, whichpushes EIP as the return address. It's nowhere near as exposed as it is on ARM, though, where it can be a src or dst for pretty much any instruction or addressing mode, IIRC. – Plastometer