I made a fully custom made GPT in Jax (with Keras 3), using Tensorflow for the data pipeline.
I've trained the model on the Shakespeare dataset and got good results (so no problem with the model). Now I want to train it on the Tiny-Stories dataset which is pretty big with GPT of 15M parameters.
Here is the code for loading the data:
def get_dataset_lists(ds_path:str):
dataset = open(ds_path, "r", encoding="utf-8").read() # [...]
dataset = dataset.split("<|endoftext|>")
r.shuffle(dataset)
dataset:list = spm.Encode( # llama's sentence piece encoder
tf.strings.strip(dataset).numpy().tolist(),
add_bos=True,
add_eos=False
) # [[SOS story], ..., [SOS story]]
print("\tNumber of stories:", len(dataset))
return dataset
def tf_dataload(
dataset:list,
batch_size:int,
maxlen:int,
shift:int,
):
import functools; import operator
dataset = functools.reduce(operator.iconcat, dataset, [])
num_tokens = len(dataset); print("\tNumber of tokens in the dataset is", num_tokens)
unique_tok = set(dataset); print("\tNumber of unique tokens in the dataset is", len(unique_tok))
# [SOS story ... SOS story]
dataset = tf.data.Dataset.from_tensor_slices(dataset)
dataset = dataset.window(maxlen+1, shift=shift, drop_remainder=True)
# [[...], [...], [...], ...] shape(m, maxlen+1)
dataset = dataset.flat_map(lambda window: window.batch(maxlen+1))
dataset = dataset.shuffle(10_000*batch_size, reshuffle_each_iteration=reshuffle_each_iteration)
# [ [ [...], [...], [...], ...], ...] shape(m//B, B, maxlen+1)
dataset = dataset.batch(batch_size, drop_remainder=True, num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.shuffle(batch_size*100)
dataset = dataset.map(lambda window: (window[:, :-1], window[:, 1:]), num_parallel_calls=tf.data.AUTOTUNE).prefetch(tf.data.AUTOTUNE)
return dataset # (shape(m//B, B, maxlen) shape(m//B, B, maxlen))
def load_data(
train_ds_path:str,
val_ds_path:str,
batch_size:int,
maxlen:int,
shift:int,
):
print("Training Dataset:")
train_ds = tf_dataload(get_dataset_lists(train_ds_path), batch_size, maxlen, shift, reshuffle_each_iteration=True)
print("Validation Dataset:")
val_ds = tf_dataload(get_dataset_lists(val_ds_path), batch_size, maxlen, shift, reshuffle_each_iteration=True)
print(f"\n{train_ds}\n{val_ds}")
datasets = {"train": train_ds.repeat(), "val":val_ds}
return datasets
- I've certain questions regarding
the value of the
shift?
First I set it equal to 1, but the training was very slow, even after 100000 steps it didn't converge even though it was decreasing slowly (I think there's no problem with the learning rate as I plotted Loss Vs Lr and selected the max learning rate possible and used cosine decay with warmup)
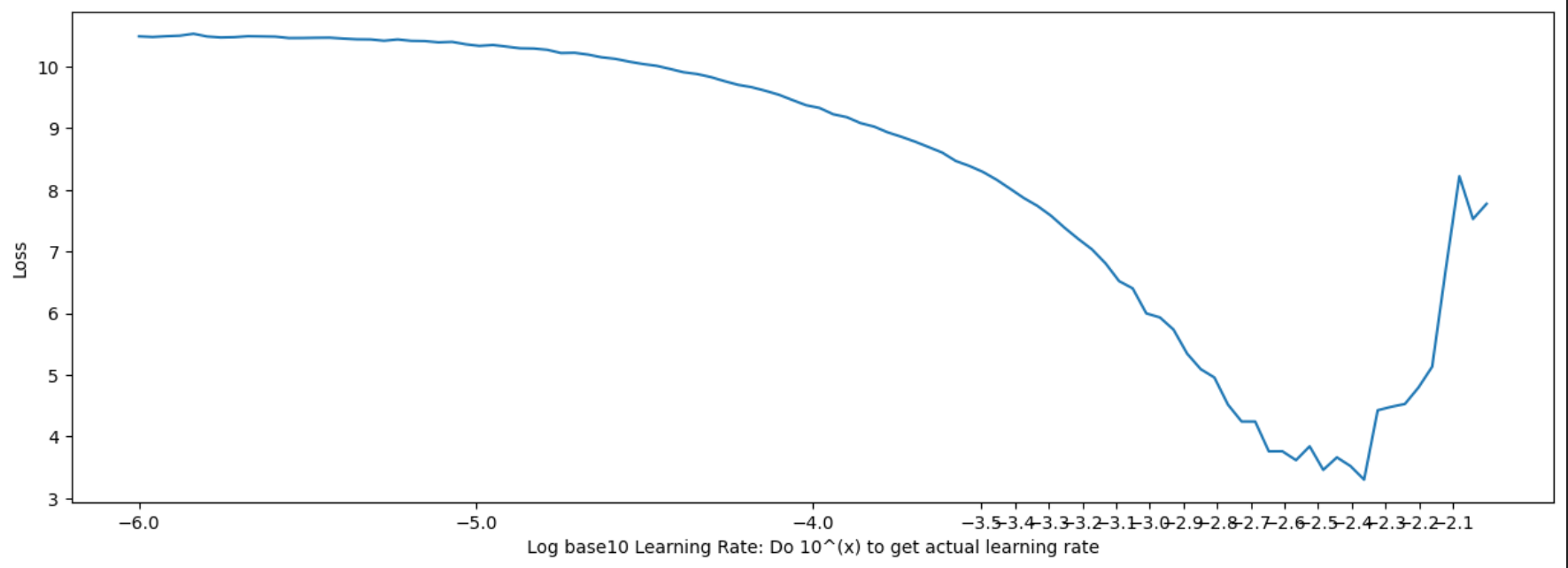
So I looked into Karpathy's llama-2 repo and the shift was equal to maxlen.
So I set it equal to maxlen and trained it for 100000 steps but the model is learning very slowly, and didn't get a loss even close to what Karpathy got
(I don't know what's the problem, as I've closely followed Karpathy's llama2 repo)
What is shift generally equal to when pre-training an LLM on Language Modelling?
Shouldn't it be 1, because the transformer model is not positionally invariant, and it would affect model performance if shift is not equal to 1? But then the number of samples will be very large...?
- And for what number of steps to train a LLM given the number of tokens
You may find the below helpful...
@dataclass
class GPTArgs:
"""GPT Configuration"""
d_model:int = 288
num_layers:int = 6
num_heads:int = 6
max_context_length:int = 256
vocab_size:int = VOCAB_SIZE # 32K
output_units:int = None # equal to vocab_size if None in model init
assert d_model % 2 == 0
assert d_model % num_heads == 0
dropout_rate:float = 0.1
@dataclass
class TArgs:
# lr scheduler
init_lr:float = 1e-7
max_lr:float = 6.5e-4
min_lr:float = 0.1*max_lr # The factor is usually 0.1 or 0.0
num_steps:int = 100_000
warmup_steps:int = 1000 # 1000, to make training more stable instead of 2000
decay_steps:int = num_steps
# optimizer
beta1:float = 0.9
beta2:float = 0.95
weight_decay:float = 1e-1
clipvalue:float = 1e0
num_grad_accumalation_steps:int = 4
# num_tok_per_update = batch_size * maxlen * gradient_accumalation = 128 * 256 * 4 = 131_072
# training
checkpoint:str = 'weights/GPTstories/Epoch{epoch}.weights.h5'
train_ds_path:str = "TinyStoriesDataset/TinyStories-train.txt"
val_ds_path:str = "TinyStoriesDataset/TinyStories-valid.txt"
steps_per_epoch = eval_freq = 2000
eval_steps:int = 200
batch_size:int = 128
patience:int = 10 # early stopping with restore best weights
Update 1:
I thought that the model wasn't getting the training samples uniformly so I modified the data pipeline and also increased the number of steps to 200,000. But there were no significant improvements. The training was still very slow by the end and loss was decreasing by 0.01 every epoch (of 2000 steps)... Got a loss of 1.67 on validation set
def pretokenize_and_save_dataset(dataset_path:str, num_shards:int, shard_dir:str):
dataset = open(dataset_path, "r", encoding="utf-8").read() # [...]
dataset = dataset.split("<|endoftext|>")
r.shuffle(dataset)
dataset:list = spm.Encode(
tf.strings.strip(dataset).numpy().tolist(),
add_bos=True,
add_eos=False
) # [[SOS story], ..., [SOS story]]
print("Dataset:")
print("\tNumber of stories:", len(dataset))
# flatten
dataset = functools.reduce(operator.iconcat, dataset, [])
num_tokens = len(dataset); print("\tNumber of tokens in the dataset:", num_tokens)
print("\tNumber of unique tokens in the dataset:", len(set(dataset)))
dataset = np.asarray(dataset, dtype=np.uint16) # [SOS story ... SOS story]
print("\tAvg length of story:", num_tokens/((dataset==1).sum()))
# shard and save dataset
sharded_datasets_list = np.array_split(dataset, num_shards) # [[SOS story...], [...], [...], ...]
filenames = [os.path.join(shard_dir, f"shard{i+1}.npy") for i in range(num_shards)]
for filename, sharded_ds in zip(filenames, sharded_datasets_list):
with open(filename, "wb") as f:
np.save(f, sharded_ds)
return filenames
def load_data_as_tfds(
dataset:np.ndarray,
maxlen:int,
shift:int,
):
# [SOS story ... SOS story]
dataset = tf.data.Dataset.from_tensor_slices(dataset.tolist())
dataset = dataset.window(maxlen+1, shift=shift, drop_remainder=True)
# [[...], [...], [...], ...] shape(m, maxlen+1)
dataset = dataset.flat_map(lambda window: window.batch(maxlen+1))
dataset = dataset.shuffle(10_000*128)
return dataset
def batch_tfds(
dataset:tf.data.Dataset,
batch_size:int,
):
dataset = dataset.batch(batch_size, drop_remainder=True, num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.shuffle(batch_size*1000)
dataset = dataset.map(lambda window: (window[:, :-1], window[:, 1:]), num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.repeat().prefetch(tf.data.AUTOTUNE)
return dataset
def load_data(
dataset_path:str,
batch_size:int,
maxlen:int,
shift:int,
num_shards:int,
shard_dir:str
):
if os.path.exists(shard_dir) and os.listdir(shard_dir):
filenames = glob.glob(os.path.join(shard_dir, "*.npy"))
else:
os.makedirs(shard_dir)
filenames = pretokenize_and_save_dataset(dataset_path, num_shards=num_shards, shard_dir=shard_dir)
r.shuffle(filenames)
to_tfds = lambda dataset: load_data_as_tfds(dataset, maxlen=maxlen, shift=shift)
num_train_shards = round(0.9651*num_shards)
num_val_shards = num_shards-num_train_shards
print("Training Dataset:")
print(f"\tNumber of files taken for training: {num_train_shards}/{num_shards}")
train_datasets_lists = [to_tfds(np.load(filename)) for filename in filenames[:num_train_shards]]
train_ds = tf.data.Dataset.sample_from_datasets(train_datasets_lists, weights=[1/num_train_shards]*num_train_shards)
# [ [ [...], [...], [...], ...], ...] shape(m//B, B, maxlen+1)
train_ds = batch_tfds(train_ds, batch_size=batch_size)
print("Validation Dataset:")
print(f"\tNumber of files taken for validation: {num_val_shards}/{num_shards}")
val_datasets_lists = [to_tfds(np.load(filename)) for filename in filenames[num_train_shards:]]
val_ds = tf.data.Dataset.sample_from_datasets(val_datasets_lists, weights=[1/num_val_shards]*num_val_shards)
# [ [ [...], [...], [...], ...], ...] shape(m//B, B, maxlen+1)
val_ds = batch_tfds(val_ds, batch_size=batch_size)
print(f"\n{train_ds}\n{val_ds}")
datasets = {"train": train_ds, "val":val_ds}
return datasets
Update 2
- Gradient accumulation results in slow training, so changed it to 1 and trained it for 200,000 epochs, got a validation loss of 1.60.