Every time I run a glue crawler on existing data, it changes the Serde serialization lib to LazySimpleSerDe, which doesn't classify correctly (e.g. for quoted fields with commas in)
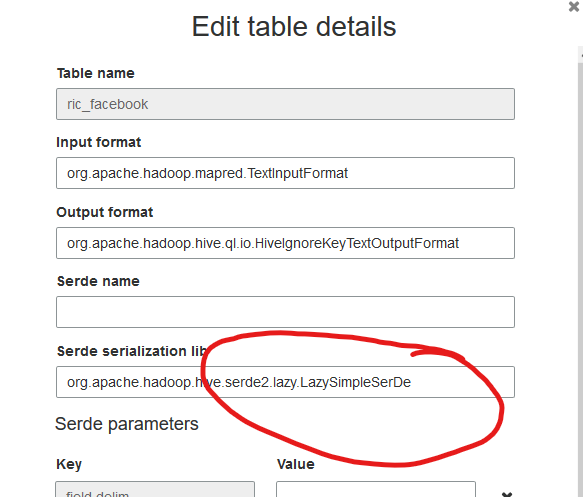
I then need to manually edit the table details in the Glue Catalog to change it to org.apache.hadoop.hive.serde2.OpenCSVSerde.
I've tried making my own csv Classifier but that doesn't help.
How do I get the crawler to specify a particular serialization lib for the tables produced or updated?