I want to do is load a json file of forex historical price data by Pandas and do statistic with the data. I have go through many topics on Pandas and parsing json file. I want to pass a json file with extra value and nested list to a pandas dataframe.
I got a json file 'EUR_JPY_H8.json'
First I import the lib that required,
import pandas as pd
import json
from pandas.io.json import json_normalize
Then load the json file,
with open('EUR_JPY_H8.json') as data_file:
data = json.load(data_file)
I got a list below:
[{u'complete': True,
u'mid': {u'c': u'119.743',
u'h': u'119.891',
u'l': u'119.249',
u'o': u'119.341'},
u'time': u'1488319200.000000000',
u'volume': 14651},
{u'complete': True,
u'mid': {u'c': u'119.893',
u'h': u'119.954',
u'l': u'119.552',
u'o': u'119.738'},
u'time': u'1488348000.000000000',
u'volume': 10738},
{u'complete': True,
u'mid': {u'c': u'119.946',
u'h': u'120.221',
u'l': u'119.840',
u'o': u'119.888'},
u'time': u'1488376800.000000000',
u'volume': 10041}]
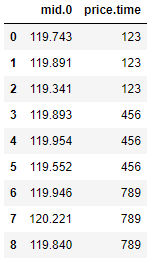
Then I pass the list to json_normalize. Try to get price which is in the nested list under 'mid'
result = json_normalize(data,'time',['time','volume','complete',['mid','h'],['mid','l'],['mid','c'],['mid','o']])
But I got such result,
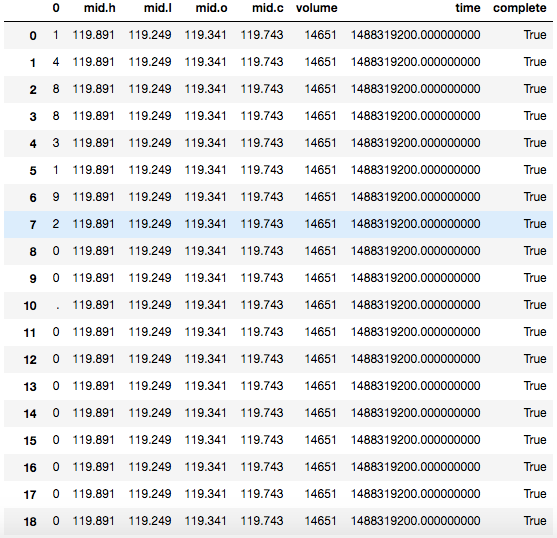
The 'time' data got breakdown into each integer row by row.
I have checked related document. I have to pass a string or list object to the 2nd parameter of json_normalize. How can I pass the timestamp there without breaking down?
The columns of my expected output are:
index | time | volumn | completed | mid.h | mid.l | mid.c | mid.o