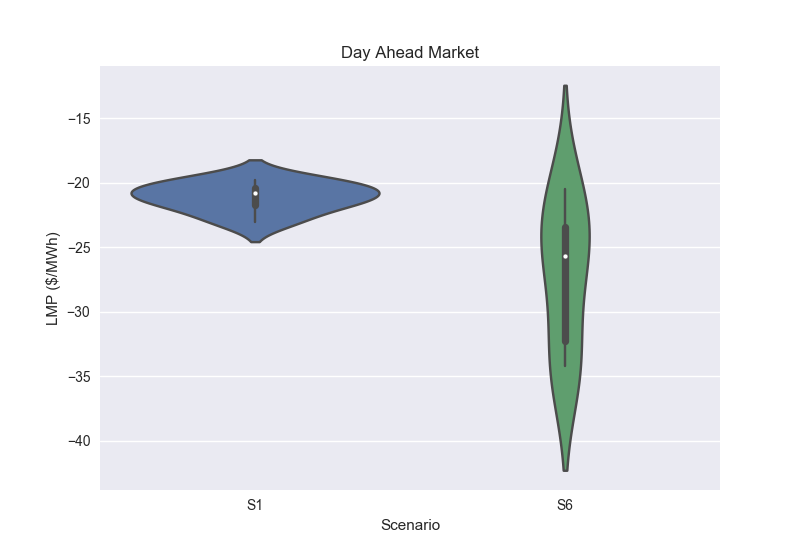
I have data I'm reading from an Excel spreadsheet. The data has a number of observations for each of six scenarios, S1 to S6. When I read in the data to my dataframe df, it looks as follows:
Scenario LMP
0 S1 -21.454544
1 S1 -20.778094
2 S1 -20.027689
3 S1 -19.747170
4 S1 -20.814405
5 S1 -21.955406
6 S1 -23.018960
...
12258 S6 -34.089906
12259 S6 -34.222814
12260 S6 -26.712010
12261 S6 -24.555973
12262 S6 -23.062616
12263 S6 -20.488411
I want to create a violinplot that has a different violin for each of the six scenarios. I'm new to Pandas and dataframes, and despite much research/testing over the last day, I can't quite figure out an elegant way to pass some reference(s) to my dataframe (to split it into different series for each scenario) that will work in the axes.violinplot() statement. For instance, I've tried the following, which doesn't work. I get a "ValueError: cannot copy sequence with size 1752 to array axis with dimension 2" on my axes.violinplot statement.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# load data into a dataframe
df = pd.read_excel('Modeling analysis charts.xlsx',
sheetname='lmps',
parse_cols=[7,12],
skiprows=0,
header=1)
fontsize = 10
fig, axes = plt.subplots()
axes.violinplot(dataset = [[df.loc[df.Scenario == 'S1']],
[df.loc[df.Scenario == 'S2']],
[df.loc[df.Scenario == 'S3']],
[df.loc[df.Scenario == 'S4']],
[df.loc[df.Scenario == 'S5']],
[df.loc[df.Scenario == 'S6']]
]
)
axes.set_title('Day Ahead Market')
axes.yaxis.grid(True)
axes.set_xlabel('Scenario')
axes.set_ylabel('LMP ($/MWh)')
plt.show()
dataset = [group['LMP'].values for name , group in df.groupby('Scenario')]might be more concise. – Helgoland