I am interested to do web crawling. I was looking at solr.
Does solr do web crawling, or what are the steps to do web crawling?
I am interested to do web crawling. I was looking at solr.
Does solr do web crawling, or what are the steps to do web crawling?
Solr 5+ DOES in fact now do web crawling! http://lucene.apache.org/solr/
Older Solr versions do not do web crawling alone, as historically it's a search server that provides full text search capabilities. It builds on top of Lucene.
If you need to crawl web pages using another Solr project then you have a number of options including:
If you want to make use of the search facilities provided by Lucene or SOLR you'll need to build indexes from the web crawl results.
See this also:
Solr does not in of itself have a web crawling feature.
Nutch is the "de-facto" crawler (and then some) for Solr.
Solr 5 started supporting simple webcrawling (Java Doc). If want search, Solr is the tool, if you want to crawl, Nutch/Scrapy is better :)
To get it up and running, you can take a detail look at here. However, here is how to get it up and running in one line:
java
-classpath <pathtosolr>/dist/solr-core-5.4.1.jar
-Dauto=yes
-Dc=gettingstarted -> collection: gettingstarted
-Ddata=web -> web crawling and indexing
-Drecursive=3 -> go 3 levels deep
-Ddelay=0 -> for the impatient use 10+ for production
org.apache.solr.util.SimplePostTool -> SimplePostTool
http://datafireball.com/ -> a testing wordpress blog
The crawler here is very "naive" where you can find all the code from this Apache Solr's github repo.
Here is how the response looks like:
SimplePostTool version 5.0.0
Posting web pages to Solr url http://localhost:8983/solr/gettingstarted/update/extract
Entering auto mode. Indexing pages with content-types corresponding to file endings xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
SimplePostTool: WARNING: Never crawl an external web site faster than every 10 seconds, your IP will probably be blocked
Entering recursive mode, depth=3, delay=0s
Entering crawl at level 0 (1 links total, 1 new)
POSTed web resource http://datafireball.com (depth: 0)
Entering crawl at level 1 (52 links total, 51 new)
POSTed web resource http://datafireball.com/2015/06 (depth: 1)
...
Entering crawl at level 2 (266 links total, 215 new)
...
POSTed web resource http://datafireball.com/2015/08/18/a-few-functions-about-python-path (depth: 2)
...
Entering crawl at level 3 (846 links total, 656 new)
POSTed web resource http://datafireball.com/2014/09/06/node-js-web-scraping-using-cheerio (depth: 3)
SimplePostTool: WARNING: The URL http://datafireball.com/2014/09/06/r-lattice-trellis-another-framework-for-data-visualization/?share=twitter returned a HTTP result status of 302
423 web pages indexed.
COMMITting Solr index changes to http://localhost:8983/solr/gettingstarted/update/extract...
Time spent: 0:05:55.059
In the end, you can see all the data are indexed properly.
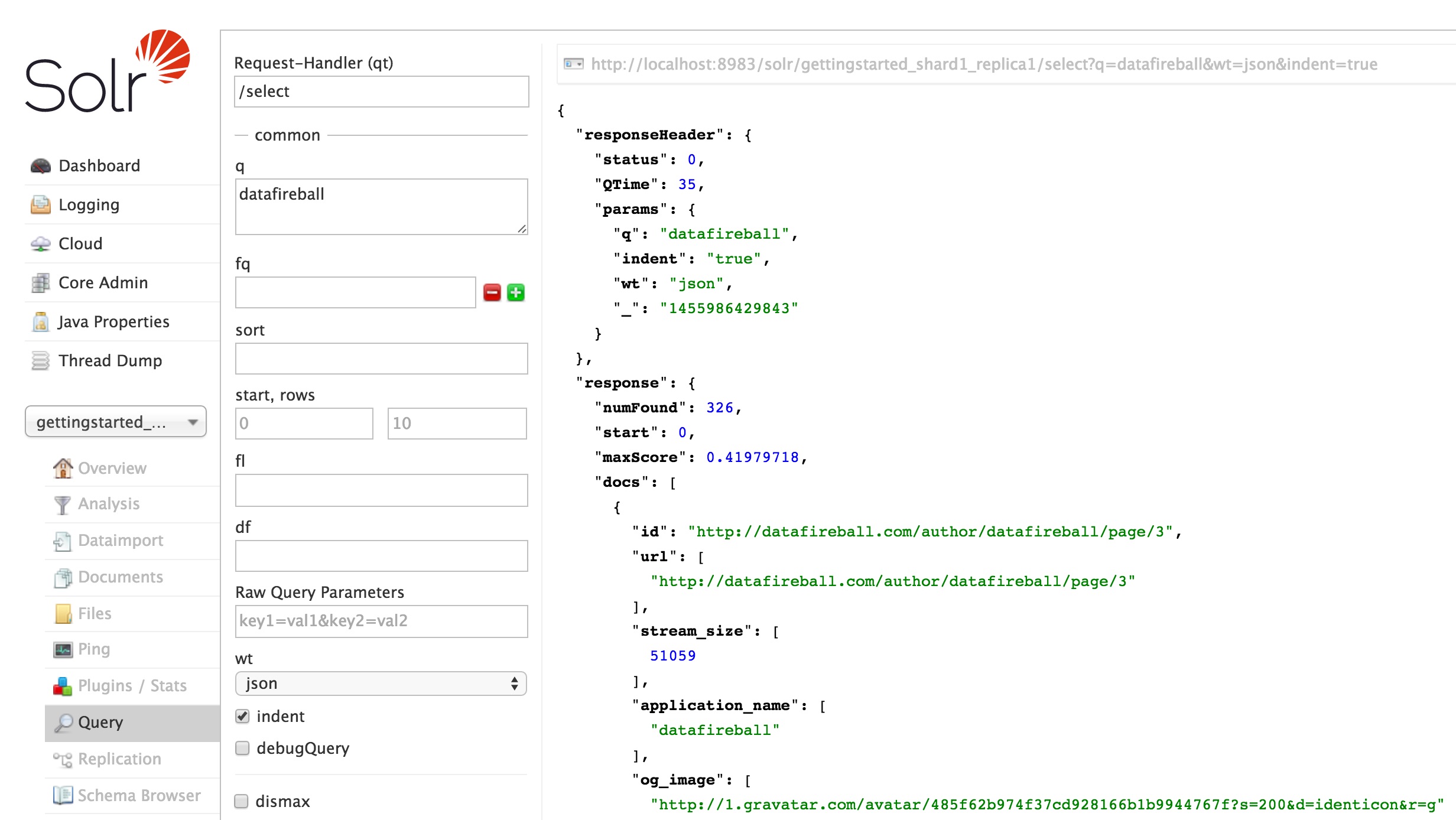
You might also want to take a look at
http://www.crawl-anywhere.com/
Very powerful crawler that is compatible with Solr.
I know this question is quite old, but I'll respond anyway for the newcomer that will wonder here.
In order to use Solr, you can use a web crawler that is capable of storing documents in Solr.
For instance, The Norconex HTTP Collector is a flexible and powerful open-source web crawler that is compatible with Solr.
To use Solr with the Norconex HTTP Collector you will need the Norconex HTTP Collector which is used to crawl the website that you want to collect data from, and you will need to install the Norconex Apache Solr Committer to store collected documents into Solr. When the committer is installed, you will need to configure the XML configuration file of the crawler. I would recommend that you follow this link to get started test how the crawler works and here to know how to configure the configuration file. Finally, you will need this link to configure the committer section of the configuration file with Solr.
Note that if your goal is not to crawl web pages, Norconex also has a Filesystem Collector that can be used with the Sorl Committer as well.
I have been using Nutch with Solr on my latest project and it seems to work quite nicely.
If you are using a Windows machine then I would strongly recommend following the 'No cygwin' instructions given by Jason Riffel too!
Yes, I agree with the other posts here, use Apache Nutch
bin/nutch crawl urls -solr http://localhost:8983/solr/ -depth 3 -topN 5
Although your solr version has the match the correct version of Nutch, because older versions of solr stores the indices in a different format
Its tutorial: http://wiki.apache.org/nutch/NutchTutorial
I know it's been a while, but in case someone else is searching for a Solr crawler like me, there is a new open-source crawler called Norconex HTTP Collector
Def Nutch ! Nutch also has a basic web front end which will let you query your search results. You might not even need to bother with SOLR depending on your requirements. If you do a Nutch/SOLR combination you should be able to take advantage of the recent work done to integrate SOLR and Nutch ... http://issues.apache.org/jira/browse/NUTCH-442
© 2022 - 2024 — McMap. All rights reserved.