TL;DR
Yes, a backtracking-based Sudoku solver can, depending on the puzzle, benefit considerably from parallelization! A puzzle's search space can be modeled as a tree data structure, and backtracking performs a depth-first search (DFS) of this tree, which is inherently not parallelizable. However, by combining DFS with its opposite form of tree traversal, breadth-first search (BFS), parallelism can be unlocked. This is because BFS allows multiple independent sub-trees to be discovered simultaneously, which can then be searched in parallel.
Because BFS unlocks parallelism, employing it warrants the use of a global thread-safe queue, onto/from which the discovered sub-trees can be pushed/popped by all threads, and this entails significant performance overhead compared to DFS. Hence parallelizing such a solver requires fine-tuning the amount of BFS carried out such that just enough is performed to ensure the traversal of the tree is sufficiently parallelized but not too much such that the overhead of thread communication (pushing/popping sub-trees of the queue) outweighs the speedup parallelization provides.
I parallelized a backtracking-based Sudoku solver a while back, and implemented 4 different parallel solver variants along with a sequential (single-threaded) solver. The parallel variants all combined DFS and BFS in different ways and to varying extents, and the fastest variant was on average over three times as fast as the single-threaded solver (see the graph at the bottom).
Also, to answer your question, in my implementation each thread receives a copy of the initial puzzle (once when the thread is spawned) so the required memory is slightly higher than the sequential solver - which is not uncommon when parallelizing something. But that's the only "inefficiency" as you put it: As mentioned above, if the amount of BFS is appropriately fine-tuned, the attainable speedup via parallelization greatly outweighs the parallel overhead from thread communication as well as the higher memory footprint. Also, while my solvers assumed unique solutions, extending them to handle non-proper puzzles and find all their solutions would be simple and wouldn't significantly, if at all, reduce the speedup, due to the nature of the solver's design. See the full answer below for more details.
FULL ANSWER
Whether a Sudoku solver benefits from multithreading strongly depends on its underlying algorithm. Common approaches such as constraint propagation (i.e. a rule-based method) where the puzzle is modeled as a constraint satisfaction problem, or stochastic search, don't really benefit since single-threaded solvers using these approaches are already exceptionally fast. Backtracking however, can benefit considerably most of the time (depending on the puzzle).
As you probably already know, a Sudoku's search space can be modeled as a tree data structure: The first level of the three represents the first empty cell, the second level the second empty cell, and so on. At each level, the nodes represent the potential values of that cell given the values of their ancestor nodes. Thus searching this space can be parallelized by searching independent sub-trees at the same time. A single-threaded backtracking solver must traverse the whole tree by itself, one sub-tree after another, but a parallel solver can have each thread search a separate sub-tree in parallel.
There are multiple ways to realize this, but they're all based on the principle of combining depth-first search (DFS) with breadth-first search (BFS), which are two (opposite) forms of tree traversal. A single-threaded backtracking solver only carries out DFS the entire search, which is inherently non-parallelizable. By adding BFS into the mix however, parallelism can be unlocked. This is because BFS traverses the tree level-by-level (as opposed to branch-by-branch with DFS) and thereby finds all possible nodes on a given level before moving to the next lower level, whereas DFS takes the first possible node and completely searches its sub-tree before moving to the next possible node. As a result, BFS enables multiple independent sub-trees to be discovered right away that can then be searched by separate threads; DFS doesn't know anything about additional independent sub-trees right from the get go, because it's busy searching the first one it finds in a depth-first manner.
As is usually the case with multi-threading, parallelizing your code is tricky and initial attempts often decrease performance if you don't know exactly what you're doing. In this case, it's important to realize that BFS is much slower than DFS, so the chief concern is tweaking the amount of DFS and BFS you carry out such that just enough BFS is executed in order to unlock the ability to discover multiple sub-trees simultaneously, but also minimizing it so its slowness doesn't end up outweighing that ability. Note that BFS isn't inherently slower than DFS, it's just that the threads need access to the discovered sub-trees so they can search them. Thus BFS requires a global thread-safe data structure (e.g. a queue) onto/from which the sub-trees can be pushed/popped by separate threads, and this entails significant overhead compared to DFS which doesn't require any communication between threads. Hence parallelizing such a solver is a fine-tuning process and one wants to conduct enough BFS to provide all threads with enough sub-trees to search (i.e. achieve a good load balancing among all threads) while minimizing the communication between threads (the pushing/popping of sub-trees onto/off the queue).
I parallelized a backtracking-based Sudoku solver a while back, and implemented 4 different parallel solver variants and benchmarked them against a sequential (single-threaded) solver which I also implemented. They were all implemented in C++. The best (fastest) parallel variant's algorithm was as follows:
- Start with a DFS of the puzzle's tree, but only do it down to a certain level, or search-depth
- At the search-depth, conduct a BFS and push all the sub-trees discovered at that level onto the global queue
- The threads then pop these sub-trees off the queue and perform a DFS on them, all the way down to the last level (the last empty cell).
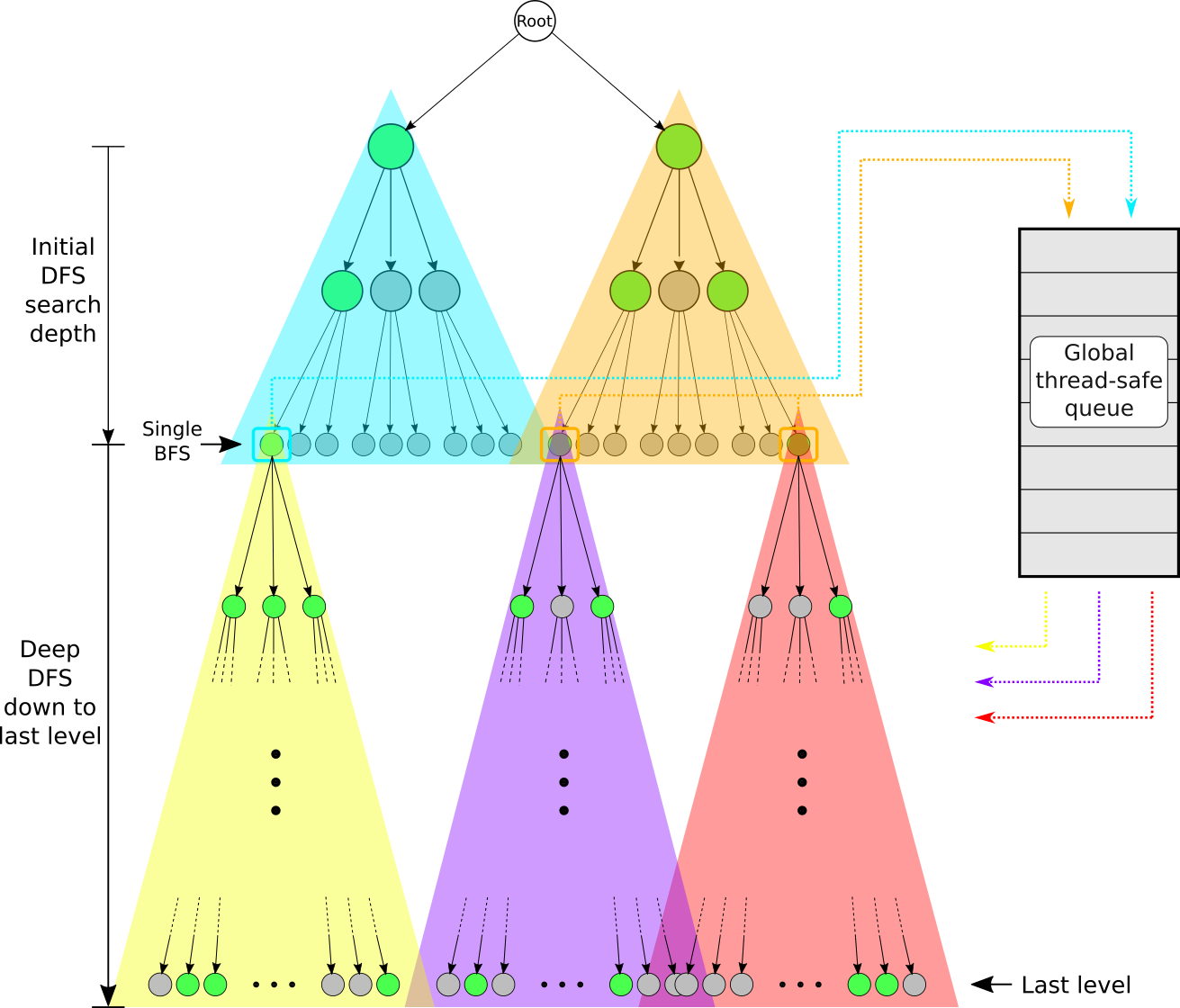
The following figure (taken from my report from back then) illustrates these steps: The different color triangles represent different threads and the sub-trees they traverse. The green nodes represent allowed cell values on that level. Note the single BFS carried out at the search-depth; The sub-trees discovered at this level (yellow, purple, and red) are pushed onto the global queue, which are then traversed independently in parallel all the way down to the last level (last empty cell) of the tree.
![enter image description here]()
As you can see, this implementation performs a BFS of only one level (at the search-depth). This search-depth is adjustable, and optimizing it represents the aforementioned fine-tuning process. The deeper the search-depth, the more BFS is carried out since a tree's width (# nodes on a given level) naturally increases the further down you go. Interestingly, the optimal search depth is typically at a quite shallow level (i.e. a not very deep level in the tree); This reveals that conducting even a small amount of BFS is already enough to generate ample sub-trees and provide a good load balance among all threads.
Also, thanks to the global queue, an arbitrary number of threads can be chosen. It's generally a good idea though to set the number of threads equal to the number of hardware threads (i.e. # logical cores); Choosing more typically won't further increase performance. Furthermore, it's also possible to parallelize the initial DFS performed at the start by performing a BFS of the first level of the tree (first empty cell): the sub-trees discovered at level 1 are then traversed in parallel, each thread stopping at the given search-depth. This is what's done in the figure above. This isn't strictly necessary though as the optimal search depth is typically quite shallow as mentioned above, hence a DFS down to the search-depth is still very quick even if it's single-threaded.
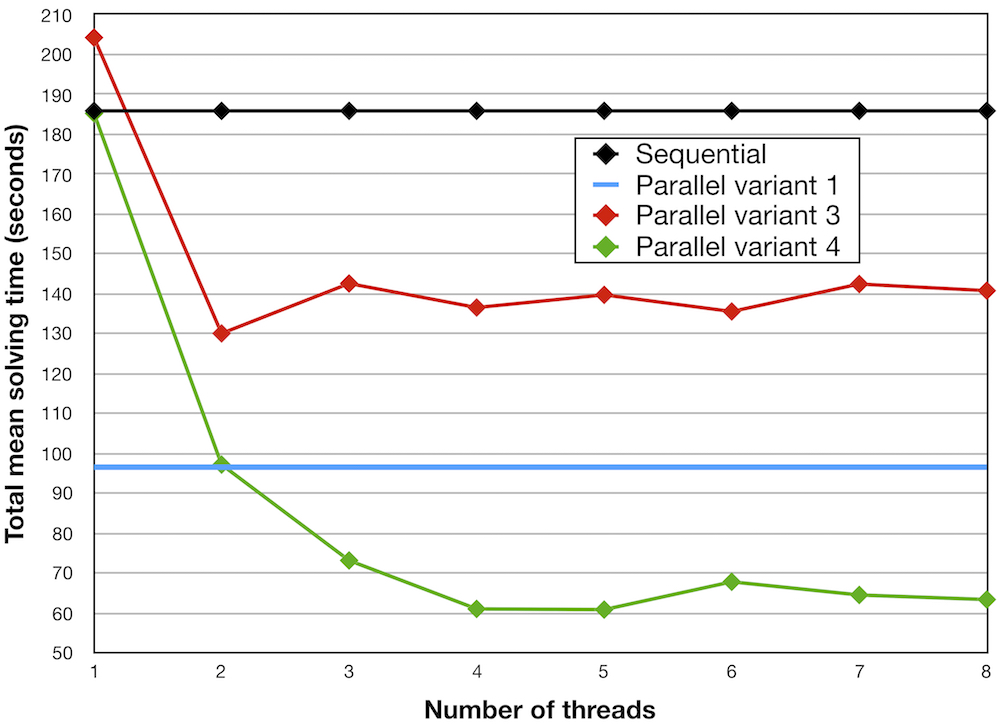
I thoroughly tested all solvers on 14 different Sudoku puzzles (specifically, a select set of puzzles specially designed to be difficult for a backtracking solver), and the figure below shows each solver's average time taken to solve all puzzles, for various thread counts (my laptop has four hardware threads). Parallel variant 2 isn't shown because it actually achieved significantly worse performance than the sequential solver. With parallel variant 1, the # threads was automatically determined during run-time, and depended on the puzzle (specifically, the branching factor of the first level); Hence the blue line represents its average total solving time regardless of the thread count.
![enter image description here]()
All parallel solver variants combine DFS and BFS in different ways and to varying extents. When utilizing 4 threads, the fastest parallel solver (variant 4) was on average over three times as fast as the single-threaded solver!