Everywhere I look, I see that MongoDB is CP. But when I dig in I see it is eventually consistent. Is it CP when you use safe=true? If so, does that mean that when I write with safe=true, all replicas will be updated before getting the result?
Where does mongodb stand in the CAP theorem?
Asked Answered
MongoDB is strongly consistent by default - if you do a write and then do a read, assuming the write was successful you will always be able to read the result of the write you just read. This is because MongoDB is a single-master system and all reads go to the primary by default. If you optionally enable reading from the secondaries then MongoDB becomes eventually consistent where it's possible to read out-of-date results.
MongoDB also gets high-availability through automatic failover in replica sets: http://www.mongodb.org/display/DOCS/Replica+Sets
According to aphyr.com/posts/322-call-me-maybe-mongodb-stale-reads even if you read from the primary node in the replica set you may get stale or dirty data. So is MongoDB strong consistent?? –
Motherhood
Awesome experiments by Kyle. It really hunts mongo down. I wonder if there are production systems, for example using MongoDB doing payment transactions? If it's just a personal website, who cares strong consistency then. –
Antimatter
Just for the record, MongoDB v3.4 passed the test designed by Kyle so yes, MongoDB is strongly consistent, even with ReplicaSet and Sharding : mongodb.com/mongodb-3.4-passes-jepsen-test –
Inly
This answer might be a bit too simplistic, since MongoDB can sacrifice availability from time to time, based on configuration. JoCa's better explains the situations in which it behaves CA/CP/AP –
Brassware
So, when you say - "all reads go to primary by default" , heavy load on one node might cause latencies.. and also what if the primary goes down.. we are very vulnerable with this option correct ? Please correct me if wrong –
Emileeemili
@Emileeemili - if the primary goes down then a new one will be elected and your system will recover. Spreading reads across the whole replica set to increase query capacity can be dangerous if you're not careful. Imagine a system with 3 nodes, each processing 1/3 of the total read volume. The system is getting close to the max number of reads that any one node can handle. Now one of the nodes goes down for any reason (including planned maintenance!). That nodes reads then get sent to the remaining two nodes, which can push them over the limit of what they can handle and cause cascading failure. –
Indiscretion
For the record, I no longer stand completely by my original comment here from 9 years ago. The CAP theory is a poor way to reason about systems like this as it's a vast oversimplification of reality. Consistency and availability in the presence of network partitions is a spectrum with lots of little trade offs, rather than a single binary. While all the answers on this post are a bit of an oversimplification, including mine, JoCa's probably comes closest to a complete picture. –
Indiscretion
I agree with Luccas post. You can't just say that MongoDB is CP/AP/CA, because it actually is a trade-off between C, A and P, depending on both database/driver configuration and type of disaster: here's a visual recap, and below a more detailed explanation.
| Scenario | Main Focus | Description |
|---|---|---|
| No partition | CA | The system is available and provides strong consistency |
| partition, majority connected | AP | Not synchronized writes from the old primary are ignored |
| partition, majority not connected | CP | only read access is provided to avoid separated and inconsistent systems |
Consistency:
MongoDB is strongly consistent when you use a single connection or the correct Write/Read Concern Level (Which will cost you execution speed). As soon as you don't meet those conditions (especially when you are reading from a secondary-replica) MongoDB becomes Eventually Consistent.
Availability:
MongoDB gets high availability through Replica-Sets. As soon as the primary goes down or gets unavailable else, then the secondaries will determine a new primary to become available again. There is an disadvantage to this: Every write that was performed by the old primary, but not synchronized to the secondaries will be rolled back and saved to a rollback-file, as soon as it reconnects to the set(the old primary is a secondary now). So in this case some consistency is sacrificed for the sake of availability.
Partition Tolerance:
Through the use of said Replica-Sets MongoDB also achieves the partition tolerance: As long as more than half of the servers of a Replica-Set is connected to each other, a new primary can be chosen. Why? To ensure two separated networks can not both choose a new primary. When not enough secondaries are connected to each other you can still read from them (but consistency is not ensured), but not write. The set is practically unavailable for the sake of consistency.
So if Im using the correct write/read concern level,it means all wrotes and reads go to the primary (if I understood correctly), so what exactly do the secondaries do? Just sit there on standby in case the primary goes down? –
Cohdwell
@Cohdwell you may want to read this section of the manual: You can use secondaries for reading. If you are using "majority" Read-Level the read will be valid as soon as a majority of the members acknowledged the read. The same goes for the "majority" Write-Level. If you are using "majority" Concern-Level for both, then you have a consistent database. You may want read more about this in the manual. –
Paraffinic
As a brilliant new article showed up and also some awesome experiments by Kyle in this field, you should be careful when labeling MongoDB, and other databases, as C or A.
Of course CAP helps to track down without much words what the database prevails about it, but people often forget that C in CAP means atomic consistency (linearizability), for example. And this caused me lots of pain to understand when trying to classify. So, besides MongoDB give strong consistency, that doesn't mean that is C. In this way, if one make this classifications, I recommend to also give more depth in how it actually works to not leave doubts.
Yes, it is CP when using safe=true. This simply means, the data made it to the masters disk.
If you want to make sure it also arrived on some replica, look into the 'w=N' parameter where N is the number of replicas the data has to be saved on.
MongoDB selects Consistency over Availability whenever there is a Partition. What it means is that when there's a partition(P) it chooses Consistency(C) over Availability(A).
To understand this, Let's understand how MongoDB does replica set works. A Replica Set has a single Primary node. The only "safe" way to commit data is to write to that node and then wait for that data to commit to a majority of nodes in the set. (you will see that flag for w=majority when sending writes)
Partition can occur in two scenarios as follows :
- When Primary node goes down: system becomes unavailable until a new primary is selected.
- When Primary node looses connection from too many Secondary nodes: system becomes unavailable. Other secondaries will try to elect a new Primary and current primary will step down.
Basically, whenever a partition happens and MongoDB needs to decide what to do, it will choose Consistency over Availability. It will stop accepting writes to the system until it believes that it can safely complete those writes.
"It will stop accepting writes to the system until it believes that it can safely complete those writes." What about reads? Would it remain read-available during that time? –
Educated
Yes it would remain read-available, if you've specified a read preference of 'primaryPreferred', 'secondaryPrefered', 'secondary' or 'closest'. –
Ppi
Mongodb never allows write to secondary. It allows optional reads from secondary but not writes. So if your primary goes down, you can't write till a secondary becomes primary again. That is how, you sacrifice High Availability in CAP theorem. By keeping your reads only from primary you can have strong consistency.
I'm not sure about P for Mongo. Imagine situation:
- Your replica gets split into two partitions.
- Writes continue to both sides as new masters were elected
- Partition is resolved - all servers are now connected again
- What happens is that new master is elected - the one that has highest oplog, but the data from the other master gets reverted to the common state before partition and it is dumped to a file for manual recovery
- all secondaries catch up with the new master
The problem here is that the dump file size is limited and if you had a partition for a long time you can loose your data forever.
You can say that it's unlikely to happen - yes, unless in the cloud where it is more common than one may think.
This example is why I would be very careful before assigning any letter to any database. There's so many scenarios and implementations are not perfect.
If anyone knows if this scenario has been addressed in later releases of Mongo please comment! (I haven't been following everything that was happening for some time..)
MongoDB's election protocol is designed to have (at most) a single primary. A primary can only be elected (and sustained) by a strict majority of configured replica set voting members (n/2 +1). In the event of a network partition, only one partition (with the majority of voting members) can elect a primary; a prior primary in a minority partition will step down and become a secondary. This is the way replica sets have always worked. In the event a former primary has accepted writes that were not replicated, they will be rolled back (saved to disk) when that member rejoins the replica set. –
Endophyte
Mongodb gives up availability. When we talk about availability in the context of the CAP theorem, it is about avoiding single points of failure that can go down. In mongodb. there is a primary router host. and if that goes down,there is gonna be some downtime in the time that it takes for it to elect a new replacement server to take its place. In practical, that is gonna happen very qucikly. we do have a couple of hot standbys sitting there ready to go. So as soon as the system detects that primary routing host went down, it is gonna switch over to a new one pretty much right away. Technically speaking it is still single point of failure. There is still a chance of downtime when that happens.
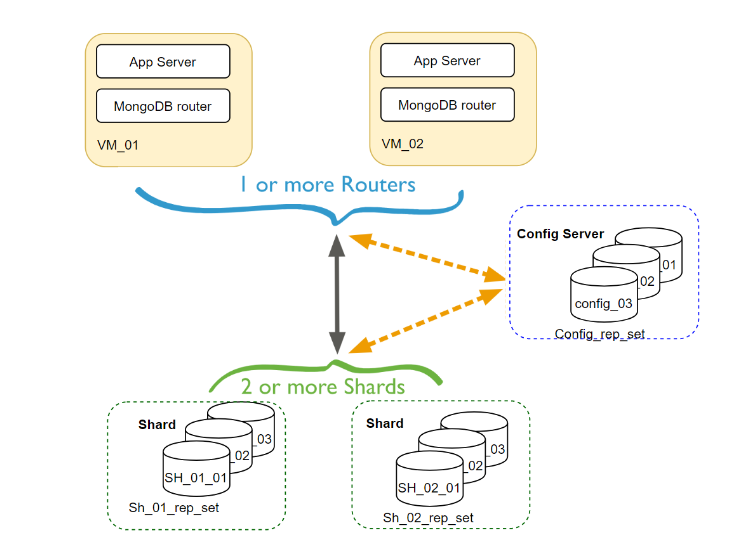
There is a config server, that is the primary and we have an app server, that is primary at any given time. even though we have multiple backups, there is gonna be a brief period of downtime if any of those servers go down. the system has to first detect that there was an outage and then remaining servers need to reelect a new primary host to take its place. that might take a few seconds and this is enough to say that mongodb is trading off the availability
© 2022 - 2024 — McMap. All rights reserved.