I want to parallelize over single examples or batch of example (in my situation is that I only have cpus, I have up to 112). I tried it but I get a bug that the losses cannot have the gradient out of separate processes (which entirely ruins my attempt). I still want to do it and it essential that after the multiproessing happens that I can do an optimizer step. How do I get around it? I made a totally self contained example:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import Dataset, DataLoader
from torch.multiprocessing import Pool
class SimpleDataSet(Dataset):
def __init__(self, Din, num_examples=23):
self.x_dataset = [torch.randn(Din) for _ in range(num_examples)]
# target function is x*x
self.y_dataset = [x**2 for x in self.x_dataset]
def __len__(self):
return len(self.x_dataset)
def __getitem__(self, idx):
return self.x_dataset[idx], self.y_dataset[idx]
def get_loss(args):
x, y, model = args
y_pred = model(x)
criterion = nn.MSELoss()
loss = criterion(y_pred, y)
return loss
def get_dataloader(D, num_workers, batch_size):
ds = SimpleDataSet(D)
dl = DataLoader(ds, batch_size=batch_size, num_workers=num_workers)
return dl
def train_fake_data():
num_workers = 2
Din, Dout = 3, 1
model = nn.Linear(Din, Dout).share_memory()
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
batch_size = 2
num_epochs = 10
# num_batches = 5
num_procs = 5
dataloader = get_dataloader(Din, num_workers, batch_size)
scheduler = StepLR(optimizer, step_size=1, gamma=0.7)
for epoch in range(num_epochs):
for _, batch in enumerate(dataloader):
batch = [(torch.randn(Din), torch.randn(Dout), model) for _ in batch]
with Pool(num_procs) as pool:
optimizer.zero_grad()
losses = pool.map(get_loss, batch)
loss = torch.mean(losses)
loss.backward()
optimizer.step()
# scheduler
scheduler.step()
if __name__ == '__main__':
# start = time.time()
# train()
train_fake_data()
# print(f'execution time: {time.time() - start}')
Error:
Traceback (most recent call last):
File "/Users/brando/anaconda3/envs/coq_gym/lib/python3.7/site-packages/IPython/core/interactiveshell.py", line 3427, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-2-ea57e03ba088>", line 1, in <module>
runfile('/Users/brando/ML4Coq/playground/multiprocessing_playground/multiprocessing_cpu_pytorch.py', wdir='/Users/brando/ML4Coq/playground/multiprocessing_playground')
File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/_pydev_bundle/pydev_umd.py", line 197, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/Users/brando/ML4Coq/playground/multiprocessing_playground/multiprocessing_cpu_pytorch.py", line 95, in <module>
train_fake_data()
File "/Users/brando/ML4Coq/playground/multiprocessing_playground/multiprocessing_cpu_pytorch.py", line 83, in train_fake_data
losses = pool.map(get_loss, batch)
File "/Users/brando/anaconda3/envs/coq_gym/lib/python3.7/multiprocessing/pool.py", line 290, in map
return self._map_async(func, iterable, mapstar, chunksize).get()
File "/Users/brando/anaconda3/envs/coq_gym/lib/python3.7/multiprocessing/pool.py", line 683, in get
raise self._value
multiprocessing.pool.MaybeEncodingError: Error sending result: '[tensor(0.5237, grad_fn=<MseLossBackward>)]'. Reason: 'RuntimeError('Cowardly refusing to serialize non-leaf tensor which requires_grad, since autograd does not support crossing process boundaries. If you just want to transfer the data, call detach() on the tensor before serializing (e.g., putting it on the queue).')'
I am sure I want to do this. How should I be doing this?
New attempt using DDP
"""
Based on: https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
Note: as opposed to the multiprocessing (torch.multiprocessing) package, processes can use
different communication backends and are not restricted to being executed on the same machine.
"""
import torch
from torch import nn, optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
import os
num_epochs = 5
batch_size = 8
Din, Dout = 10, 5
data_x = torch.randn(batch_size, Din)
data_y = torch.randn(batch_size, Dout)
data = [(i*data_x, i*data_y) for i in range(num_epochs)]
class OneDeviceModel(nn.Module):
"""
Toy example for a model ran in parallel but not distributed accross gpus
(only processes with their own gpu or hardware)
"""
def __init__(self):
super().__init__()
self.net1 = nn.Linear(Din, Din)
self.relu = nn.ReLU()
self.net2 = nn.Linear(Din, Dout)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def setup_process(rank, world_size, backend='gloo'):
"""
Initialize the distributed environment (for each process).
gloo: is a collective communications library (https://github.com/facebookincubator/gloo). My understanding is that
it's a library/API for process to communicate/coordinate with each other/master. It's a backend library.
"""
# set up the master's ip address so this child process can coordinate
# os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# - use NCCL if you are using gpus: https://pytorch.org/tutorials/intermediate/dist_tuto.html#communication-backends
if torch.cuda.is_available():
backend = 'nccl'
# Initializes the default distributed process group, and this will also initialize the distributed package.
dist.init_process_group(backend, rank=rank, world_size=world_size)
def cleanup():
""" Destroy a given process group, and deinitialize the distributed package """
dist.destroy_process_group()
def run_parallel_training_loop(rank, world_size):
"""
Distributed function to be implemented later.
This is the function that is actually ran in each distributed process.
Note: as DDP broadcasts model states from rank 0 process to all other processes in the DDP constructor,
you don’t need to worry about different DDP processes start from different model parameter initial values.
"""
print()
print(f"Start running DDP with model parallel example on rank: {rank}.")
print(f'current process: {mp.current_process()}')
print(f'pid: {os.getpid()}')
setup_process(rank, world_size)
# create model and move it to GPU with id rank
model = OneDeviceModel().to(rank) if torch.cuda.is_available() else OneDeviceModel().share_memory()
# ddp_model = DDP(model, device_ids=[rank])
ddp_model = DDP(model)
for batch_idx, batch in enumerate(data):
x, y = batch
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(x)
labels = y.to(rank) if torch.cuda.is_available() else y
# Gradient synchronization communications take place during the backward pass and overlap with the backward computation.
loss_fn(outputs, labels).backward() # When the backward() returns, param.grad already contains the synchronized gradient tensor.
optimizer.step() # TODO how does the optimizer know to do the gradient step only once?
print()
print(f"Start running DDP with model parallel example on rank: {rank}.")
print(f'current process: {mp.current_process()}')
print(f'pid: {os.getpid()}')
# Destroy a given process group, and deinitialize the distributed package
cleanup()
def main():
print()
print('running main()')
print(f'current process: {mp.current_process()}')
print(f'pid: {os.getpid()}')
# args
world_size = mp.cpu_count()
mp.spawn(run_parallel_training_loop, args=(world_size,), nprocs=world_size)
if __name__ == "__main__":
print('starting __main__')
main()
print('Done!\a\n')
it seems it works but my question is in line 74 do I need to do this
model = OneDeviceModel().to(rank) if torch.cuda.is_available() else OneDeviceModel().share_memory()
or
model = OneDeviceModel().to(rank) if torch.cuda.is_available() else OneDeviceModel()
for it to work properly in multiple CPUs?
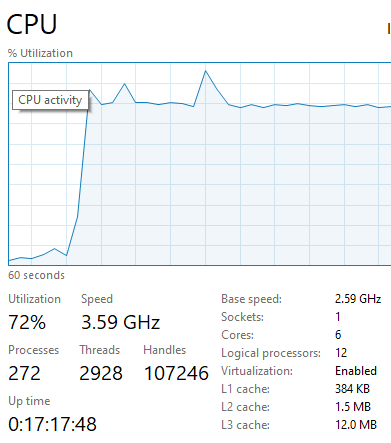
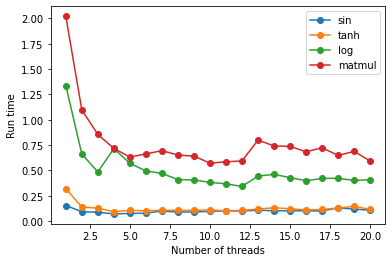
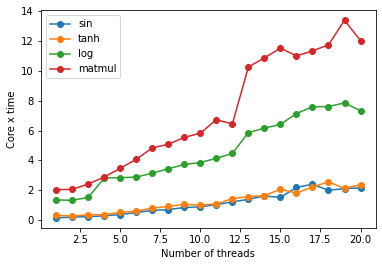
Serial is faster than parallel even if I have 112 cpu cores?
My current issue is that the cpu parallel job is slower than the serially running one when only cpus are available.
I want to know how to set up python and parallel cpus. e.g. if I have X cpus how many processes should I be running...X? or what? How do I choose this number, even if its heursitics rough.
related links from research:
loss = criterion(y_pred, y).detach()which removed that error message, and gave a new one complaining that withloss = torch.mean(losses),lossesmust be a tensor rather than a list (pool.map is returning a list of tensors from the batch). – Plustorchrunlaunching utility. Details here: github.com/learnables/learn2learn/issues/… – Sizable