As the question is quite broad, I'll try to shed a little different light and touch on different topics than what was shown in
@Daniel's in-depth answer.
Training
Data parallelization vs model parallelization
As mentioned by @Daniel data parallelism is used way more often and is easier to do correctly. Major caveat of model parallelism is the need to wait for part of neural network and synchronization between them.
Say you have a simple feedforward 5 layer neural network spread across 5 different GPUs, each layer for one device. In this case, during each forward pass each device has to wait for computations from the previous layers. In this simplistic case, copying data between devices and synchronization would take a lot longer and won't bring benefits.
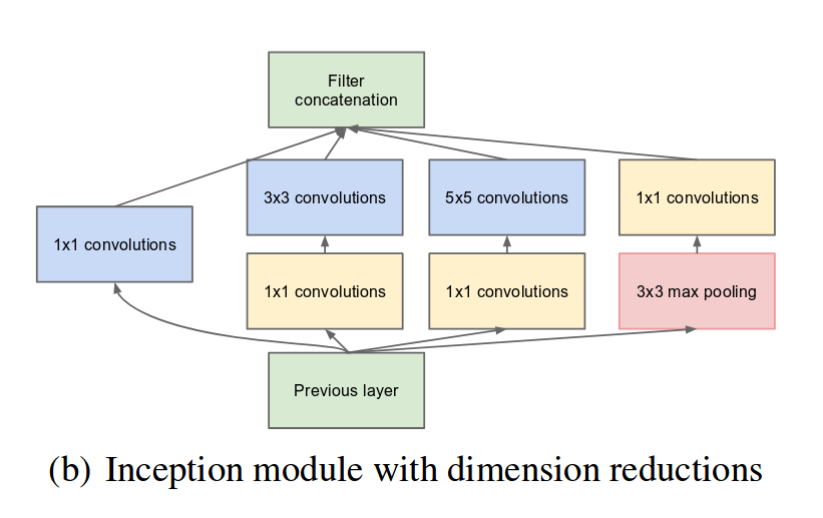
On the other hand, there are models better suited for model parallelization like Inception networks, see picture below:
![inception block]()
Here you can see 4 independent paths from previous layer which could go in parallel and only 2 synchronization points (Filter concatenation and Previous Layer).
Questions
E.g. backpropagation through the graph itself can be parallelized e.g.
by having different layers hosted on different machines since (I
think?) the autodiff graph is always a DAG.
It's not that easy. Gradients are calculated based on the loss value (usually) and you need to know gradients of deeper layers to calculate gradients for the more shallow ones. As above, if you have independent paths it's easier and may help, but it's way easier on a single device.
I believe this is also called gradient accumulation (?)
No, it's actually reduction across multiple devices. You can see some of that in PyTorch tutorial. Gradient accumulation is when you run your forward pass (either on single or multiple devices) N times and backpropagate (the gradient is kept in the graph and the values are added during each pass) and optimizer only makes a single step to change neural network's weights (and clears the gradient). In this case, loss is usually divided by the number of steps without optimizer. This is used for more reliable gradient estimation, usually when you are unable to use large batches.
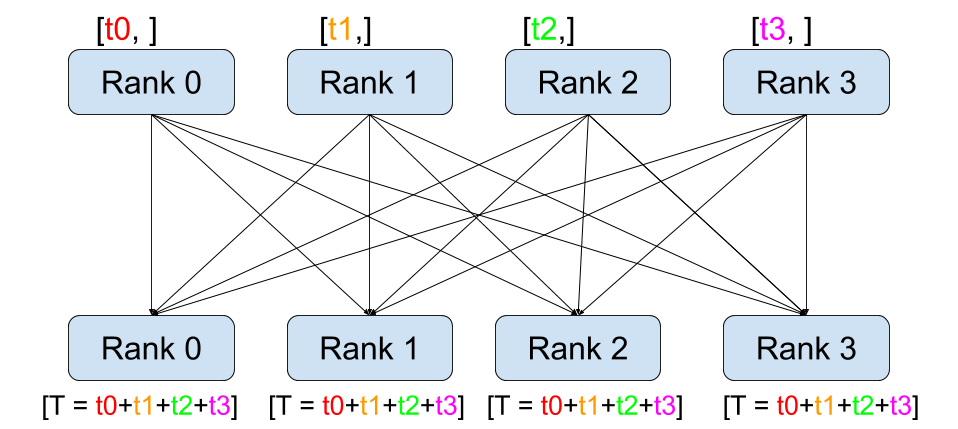
Reduction across devices looks like this:
![reduction]()
This is all-reduce in data parallelization, each device calculates the values which are send to all other devices and backpropagated there.
When is each strategy better for what type of problem or neural
network?
Described above, data parallel is almost always fine if you have enough of data and the samples are big (up to 8k samples or more can be done at once without very big struggle).
Which modes are supported by modern libraries?
tensorflow and pytorch both support either, most modern and maintained libraries have those functionalities implemented one way or another
can one combine all four (2x2) strategies
Yes, you can parallelize both model and data across and within machines.
synchronous vs asynchronous
asynchronous
Described by @Daniel in brief, but it's worth mentioning updates are not totally separate. That would make little sense, as we would essentially train N different models based on their batches.
Instead, there is a global parameter space, where each replica is supposed to share calculated updates asynchronously (so forward pass, backward, calculate update with optimizer and share this update to global params).
This approach has one problem though: there is no guarantee that when one worker calculated forward pass another worker updated the parameters, so the update is calculated with respect to old set of params and this is called stale gradients. Due to this, convergence might be hurt.
Other approach is to calculate N steps and updates for each worker and synchronize them afterwards, though it's not used as often.
This part was based on great blogpost and you should definitely read it if interested (there is more about staleness and some solutions).
synchronous
Mostly described previously, there are different approaches but PyTorch gathers output from network and backpropagates on them (torch.nn.parallel.DistributedDataParallel)[https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel]. BTW. You should solely this (no torch.nn.DataParallel) as it overcomes Python's GIL problem.
Takeaways
- Data parallelization is always almost used when going for speed up as you "only" have to replicate neural network on each device (either over the network or within single machine), run part of batch on each during the forward pass, concatenate them into a single batch (synchronization) on one device and backpropagate on said.
- There are multiple ways to do data parallelization, already introduced by @Daniel
- Model parallelization is done when the model is too large to fit on single machine (OpenAI's GPT-3 would be an extreme case) or when the architecture is suited for this task, but both are rarely the case AFAIK.
- The more and the longer parallel paths the model has (synchronization points), the better it might be suited for model parallelization
- It's important to start workers at similar times with similar loads in order not to way for synchronization processes in synchronous approach or not to get stale gradients in asynchronous (though in the latter case it's not enough).
Serving
Small models
As you are after large models I won't delve into options for smaller ones, just a brief mention.
If you want to serve multiple users over the network you need some way to scale your architecture (usually cloud like GCP or AWS). You could do that using Kubernetes and it's PODs or pre-allocate some servers to handle requests, but that approach would be inefficient (small number of users and running servers would generate pointless costs, while large numbers of users may halt the infrastructure and take too long to process resuests).
Other way is to use autoscaling based on serverless approach. Resources will be provided based on each request so it has large scaling abilities + you don't pay when the traffic is low. You can see Azure Functions as they are on the path to improve it for ML/DL tasks, or torchlambda for PyTorch (disclaimer, I'm the author) for smaller models.
Large models
As mentioned previously, you could use Kubernetes with your custom code or ready to use tools.
In the first case, you can spread the model just the same as for training, but only do forward pass. In this way even giant models can be put up on the network (once again, GPT-3 with 175B parameters), but requires a lot of work.
In the second, @Daniel provided two possibilities. Others worth mentioning could be (read respective docs as those have a lot of functionalities):
- KubeFlow - multiple frameworks, based on Kubernetes (so auto-scaling, multi-node), training, serving and what not, connects with other things like MLFlow below
- AWS SageMaker - training and serving with Python API, supported by Amazon
- MLFlow - multiple frameworks, for experiment handling and serving
- BentoML - multiple frameworks, training and serving
For PyTorch, you could read more here, while tensorflow has a lot of serving functionality out of the box via Tensorflow EXtended (TFX).
Questions from OP's comment
Are there any forms of parallelism that are better within a machine vs
across machines
The best for of parallelism would probably be within one giant computer as to minimize transfer between devices.
Additionally, there are different backends (at least in PyTorch) one can choose from (mpi, gloo, nccl) and not all of them support direct sending, receiving, reducing etc. data between devices (some may support CPU to CPU, others GPU to GPU). If there is no direct link between devices, those have to be first copied to another device and copied again to target device (e.g. GPU on other machine -> CPU on host -> GPU on host). See pytorch info.
The more data and the bigger network, the more profitable it should be to parallelize computations. If whole dataset can be fit on a single device there is no need for parallelization. Additionally, one should take into account things like internet transfer speed, network reliability etc. Those costs may outweigh benefits.
In general, go for data parallelization if you have lots of of data (say ImageNet with 1.000.000 images) or big samples (say images 2000x2000). If possible, within a single machine as to minimize between-machines transfer. Distribute model only if there is no way around it (e.g. it doesn't fit on GPU). Don't otherwise (there is little to no point to parallelize when training MNIST as the whole dataset will easily fit in RAM and the read will be fastest from it).
why bother build custom ML-specific hardware such as TPUs?
CPUs are not the best suited for highly parallel computations (e.g. matrices multiplication) + CPU may be occupied with many other tasks (like data loading), hence it makes sense to use GPU.
As GPU was created with graphics in mind (so algebraic transformation), it can take some of CPU duties and can be specialized (many more cores when compared to CPU but simpler ones, see V100 for example).
Now, TPUs are tailored specificially for tensor computations (so deep learning mainly) and originated in Google, still WIP when compared to GPUs. Those are suited for certain types of models (mainly convolutional neural networks) and can bring speedups in this case. Additionally one should use the largest batches with this device (see here), best to be divisible by 128. You can compare that to NVidia's Tensor Cores technology (GPU) where you are fine with batches (or layer sizes) divisible by 16 or 8 (float16 precision and int8 respectively) for good utilization (although the more the better and depends on number of cores, exact graphic card and many other stuff, see some guidelines here).
On the other hand, TPUs support still isn't the best, although two major frameworks support it (tensorflow officially, while PyTorch with torch_xla package).
In general, GPU is a good default choice in deep learning right now, TPUs for convolution heavy architectures, though might give some headache tbh. Also (once again thanks @Daniel), TPUs are more power effective, hence should be cheaper when comparing single floating point operation cost.
Horovodwith AWS SageMaker in the past which is the recommended approach when doing distributed computing with TS/Keras. Here is the link horovod.readthedocs.io/en/stable/summary_include.html – Coulter