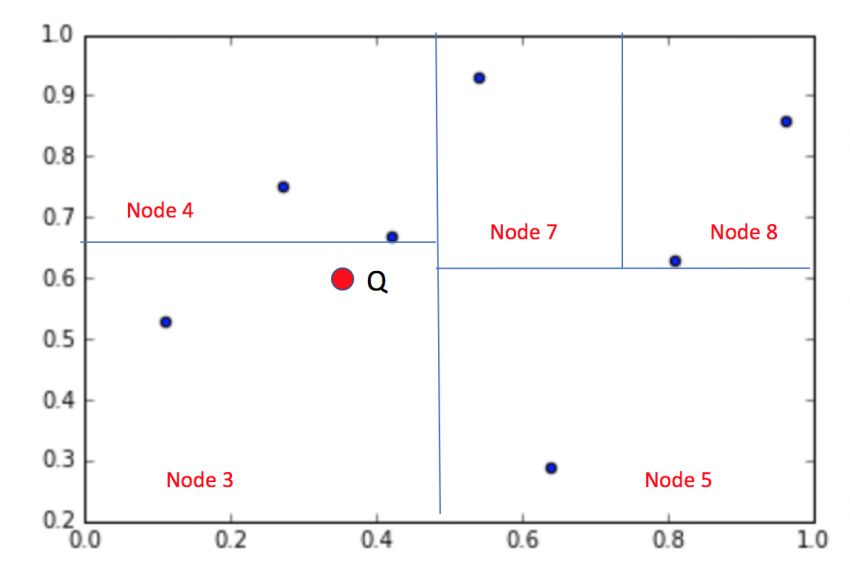
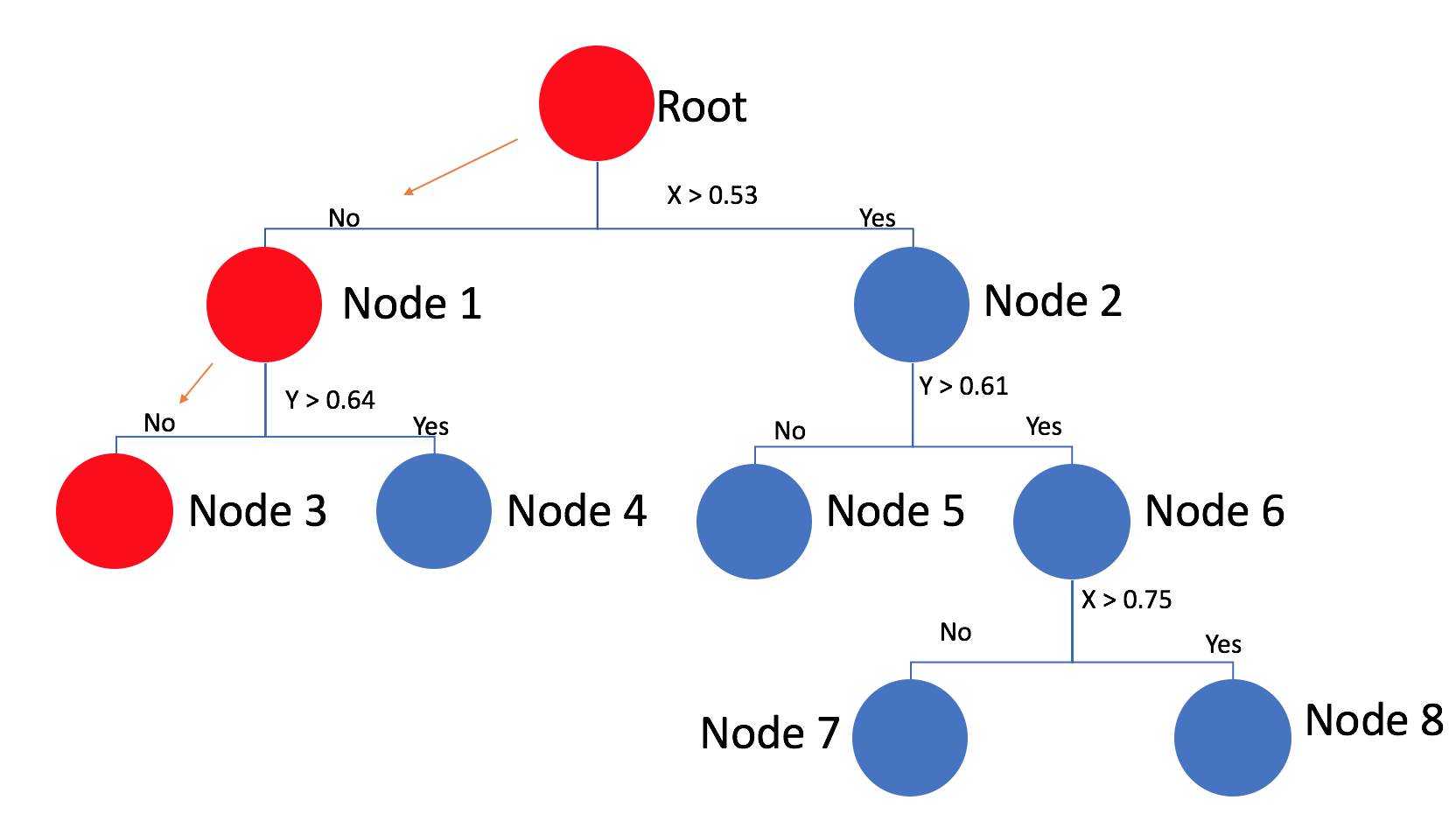
I've just spend some time puzzling out the Wikipedia description of the algorithm myself, and came up with the following Python implementation that may help: https://gist.github.com/863301
The first phase of closest_point is a simple depth first search to find the best matching leaf node.
Instead of simply returning the best node found back up the call stack, a second phase checks to see if there could be a closer node on the "away" side: (ASCII art diagram)
n current node
b | best match so far
| p | point we're looking for
|< >| | error
|< >| distance to "away" side
|< | >| error "sphere" extends to "away" side
| x possible better match on the "away" side
The current node n splits the space along a line, so we only need to look on the "away" side if the "error" between the point p and the best match b is greater than the distance from point p and the line though n. If it is, then we check to see if there are any points on the "away" side that are closer.
Because our best matching node is passed into this second test, it doesn't have to do a full traversal of the branch and will stop pretty quickly if it's on the wrong track (only heading down the "near" child nodes until it hits a leaf.)
To compute the distance between the point p and the line splitting the space through the node n, we can simply "project" the point down onto the axis by copying the appropriate coordinate as the axes are all orthogonal (horizontal or vertical).