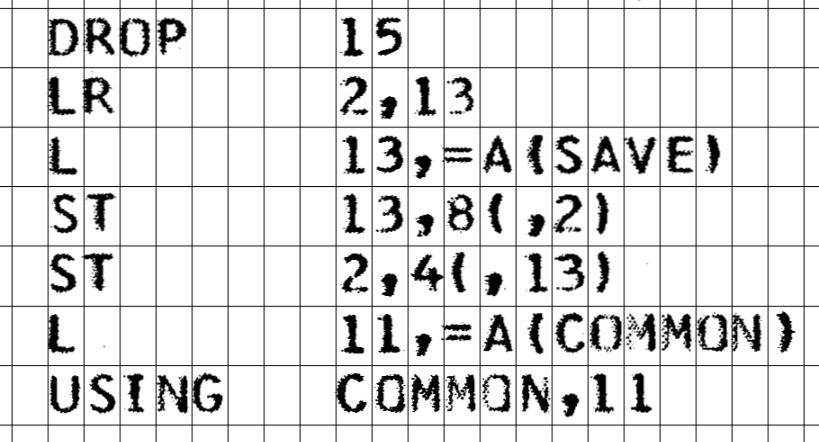
I sometimes have to take some printed source code and manually type the source code into a text editor.
Obviously typing it up takes a long time and always extra time to debug typing errors (oops missed a "$" sign there).
I decided to try some OCR solutions like:
- Microsoft Document Imaging - has built in OCR
- Result: Missed all the leading whitespace, missed all the underscores, interpreted many of the punctuation characters incorrectly.
- Conclusion: Slower than manually typing in code.
- Various online web OCR apps
- Result: Similar or worse than Microsoft Document Imaging
- Conclusion: Slower than manually typing in code.
I feel like source code would be very easy to OCR given the font is sans serif and monospace.
Have any of you found a good OCR solution that works well on source code?
Maybe I just need a better OCR solution (not necessarily source code specific)?