Is there a command I can invoke which will count the lines changed by a specific author in a Git repository? I know that there must be ways to count the number of commits as Github does this for their Impact graph.
How to count total lines changed by a specific author in a Git repository?
Using
Using
Using
Asked Answered
The output of the following command should be reasonably easy to send to script to add up the totals:
git log --author="<authorname>" --oneline --shortstat
This gives stats for all commits on the current HEAD. If you want to add up stats in other branches you will have to supply them as arguments to git log.
For passing to a script, removing even the "oneline" format can be done with an empty log format, and as commented by Jakub Narębski, --numstat is another alternative. It generates per-file rather than per-line statistics but is even easier to parse.
git log --author="<authorname>" --pretty=tformat: --numstat
May want to add "--no-merges" in there too. –
Predicative
sorry for this questions, but what are the numbers telling me? There are two rows and I have no idea what they are telling me. Lines chenged and added? –
Masonite
-M -C are missed as well. –
Ere @Masonite
git help log tells me that the first are lines added, the second lines deleted. –
Letter This gives some statistics about the author, modify as required.
Using Gawk:
git log --author="_Your_Name_Here_" --pretty=tformat: --numstat \
| gawk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s removed lines: %s total lines: %s\n", add, subs, loc }' -
Using Awk on Mac OSX:
git log --author="_Your_Name_Here_" --pretty=tformat: --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }' -
Using count-lines git-alias:
Simply create count-lines alias (once per system), like:
git config --global alias.count-lines "! git log --author=\"\$1\" --pretty=tformat: --numstat | awk '{ add += \$1; subs += \$2; loc += \$1 - \$2 } END { printf \"added lines: %s, removed lines: %s, total lines: %s\n\", add, subs, loc }' #"
And use each time later, like:
git count-lines [email protected]
For Windows, works after adding Git-Bash to
PATH(environment-variable).
For Linux, maybe replaceawkpart withgawk.
For MacOS, works without any change.
Using existing script (Update 2017)
There is a new package on github that looks slick and uses bash as dependencies (tested on linux). It's more suitable for direct usage rather than scripts.
It's git-quick-stats (github link).
Copy git-quick-stats to a folder and add the folder to path.
mkdir ~/source
cd ~/source
git clone [email protected]:arzzen/git-quick-stats.git
mkdir ~/bin
ln -s ~/source/git-quick-stats/git-quick-stats ~/bin/git-quick-stats
chmod +x ~/bin/git-quick-stats
export PATH=${PATH}:~/bin
Usage:
git-quick-stats
Also as this shows, to get accurate counts for a specific author you might need to exclude some files (such as libraries etc) which were committed by them but not really authored by them. –
Hildegard
This is wrong. You have to supply
-M -C to the command line. –
Ere @AndyShevchenko Please could you expand on how/why it is wrong and what M and C do? –
Zarathustra
-M is for bignum arithmetic (integer overflows). in gawk -C is copyright (useless) and -c is traditional parsing. –
Biotype @samthebest, because moving file is not reflecting a proper statistics. The lines are not changed. To Alex: I'm talking about Git. Btw, see my comment to the original question. –
Ere
Little addition to this great answer, inspired by https://mcmap.net/q/12697/-pipes-in-a-git-alias. You can add this line under the
[alias] section in you config file to define a new git subcommand: contrib = ! "git log --author=\"Conan O'Brien\" --pretty=tformat: --numstat" | "gawk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf \"added lines: %s removed lines: %s total lines: %s\\n\", add, subs, loc }' -" –
Preuss If the url doesn't work for you, try this:
git clone https://github.com/arzzen/git-quick-stats.git –
Flaxman you can actually do
brew install git-quick-stats –
Myriagram I think you have a '\' leftover character in the first command, it returns syntax error on Git Bash console –
Sympetalous
it's a newline separator. if its on the same line it'll fail –
Biotype
@AlexanderOh Is there any way to find the lines of code in a certain period of time? –
Seng
On Ubuntu>=20 you can just
sudo apt install git-quick-stats and then git-quick-stats in a repo folder –
Schoolmistress Wonderful, thank you. Nice is that this also works with
git show and the output is easy to tweak, e.g. just showing totals with printf "%s\t%s\t%s\n". –
Chyack The output of the following command should be reasonably easy to send to script to add up the totals:
git log --author="<authorname>" --oneline --shortstat
This gives stats for all commits on the current HEAD. If you want to add up stats in other branches you will have to supply them as arguments to git log.
For passing to a script, removing even the "oneline" format can be done with an empty log format, and as commented by Jakub Narębski, --numstat is another alternative. It generates per-file rather than per-line statistics but is even easier to parse.
git log --author="<authorname>" --pretty=tformat: --numstat
May want to add "--no-merges" in there too. –
Predicative
sorry for this questions, but what are the numbers telling me? There are two rows and I have no idea what they are telling me. Lines chenged and added? –
Masonite
-M -C are missed as well. –
Ere @Masonite
git help log tells me that the first are lines added, the second lines deleted. –
Letter In case anyone wants to see the stats for every user in their codebase, a couple of my coworkers recently came up with this horrific one-liner:
git log --shortstat --pretty="%cE" | sed 's/\(.*\)@.*/\1/' | grep -v "^$" | awk 'BEGIN { line=""; } !/^ / { if (line=="" || !match(line, $0)) {line = $0 "," line }} /^ / { print line " # " $0; line=""}' | sort | sed -E 's/# //;s/ files? changed,//;s/([0-9]+) ([0-9]+ deletion)/\1 0 insertions\(+\), \2/;s/\(\+\)$/\(\+\), 0 deletions\(-\)/;s/insertions?\(\+\), //;s/ deletions?\(-\)//' | awk 'BEGIN {name=""; files=0; insertions=0; deletions=0;} {if ($1 != name && name != "") { print name ": " files " files changed, " insertions " insertions(+), " deletions " deletions(-), " insertions-deletions " net"; files=0; insertions=0; deletions=0; name=$1; } name=$1; files+=$2; insertions+=$3; deletions+=$4} END {print name ": " files " files changed, " insertions " insertions(+), " deletions " deletions(-), " insertions-deletions " net";}'
(Takes a few minutes to crunch through our repo, which has around 10-15k commits.)
What does 'net' mean? –
Snafu
@EugenKonkov in the code it's defined as insertions - deletions. –
Delapaz
that's the only command which gives total result for a repository and runs without any plugin. –
Felten
I'm getting a bunch of users listed together, almost every possible combination of developers coming back. weirdness on my end? –
Badderlocks
@Damon, I think that should only happen if you have commits where multiple users are listed. (The script doesn't try to share / distribute credit across users for shared commits.) –
Delapaz
I think it breaks when the username has spaces in it. –
Accentor
It's grouped by the commiter, not the author, so results might be a bit confusing. –
Unterwalden
Didn't really work for me. Number were much smaller than what should have been. –
Eigenfunction
@Damon, I fixed the problem with users listed together by adding --no-merges git log --shortstat --no-merges --pretty="%cE" ... –
Continuant
for all branches: just add
--all to the beginning of the command, like this: git log --shortstat --all –
Jeneejenei git-fame
https://github.com/oleander/git-fame-rb
This is a nice tool to get the count for all authors at once, including commit and modified files count:
sudo apt-get install ruby-dev
sudo gem install git_fame
cd /path/to/gitdir && git fame
There is also Python version at https://github.com/casperdcl/git-fame (mentioned by @fracz):
sudo apt-get install python-pip python-dev build-essential
pip install --user git-fame
cd /path/to/gitdir && git fame
Sample output:
Total number of files: 2,053
Total number of lines: 63,132
Total number of commits: 4,330
+------------------------+--------+---------+-------+--------------------+
| name | loc | commits | files | percent |
+------------------------+--------+---------+-------+--------------------+
| Johan Sørensen | 22,272 | 1,814 | 414 | 35.3 / 41.9 / 20.2 |
| Marius Mathiesen | 10,387 | 502 | 229 | 16.5 / 11.6 / 11.2 |
| Jesper Josefsson | 9,689 | 519 | 191 | 15.3 / 12.0 / 9.3 |
| Ole Martin Kristiansen | 6,632 | 24 | 60 | 10.5 / 0.6 / 2.9 |
| Linus Oleander | 5,769 | 705 | 277 | 9.1 / 16.3 / 13.5 |
| Fabio Akita | 2,122 | 24 | 60 | 3.4 / 0.6 / 2.9 |
| August Lilleaas | 1,572 | 123 | 63 | 2.5 / 2.8 / 3.1 |
| David A. Cuadrado | 731 | 111 | 35 | 1.2 / 2.6 / 1.7 |
| Jonas Ängeslevä | 705 | 148 | 51 | 1.1 / 3.4 / 2.5 |
| Diego Algorta | 650 | 6 | 5 | 1.0 / 0.1 / 0.2 |
| Arash Rouhani | 629 | 95 | 31 | 1.0 / 2.2 / 1.5 |
| Sofia Larsson | 595 | 70 | 77 | 0.9 / 1.6 / 3.8 |
| Tor Arne Vestbø | 527 | 51 | 97 | 0.8 / 1.2 / 4.7 |
| spontus | 339 | 18 | 42 | 0.5 / 0.4 / 2.0 |
| Pontus | 225 | 49 | 34 | 0.4 / 1.1 / 1.7 |
+------------------------+--------+---------+-------+--------------------+
But be warned: as mentioned by Jared in the comment, doing it on a very large repository will take hours. Not sure if that could be improved though, considering that it must process so much Git data.
Worked well on mid 2015 macbook and medium large Android project (127k LoC 'is). Couple of minutes. –
Giannini
@Giannini I tried that on the Linux kernel :-) Sounds consistent with what I see. –
Nomarchy
what are the numbers in the percent column? –
Cadmann
@Cadmann percent of toal loc / commits / files for current user. –
Nomarchy
Change branch, timeout, and exclude a folder:
git fame --branch=dev --timeout=-1 --exclude=Pods/* –
Earnestineearnings @fracz nice, hope it kills the ruby one so we can get rid of ruby :-) –
Nomarchy
I am not sure I understand why this is a git command, why not just call it 'fame' or 'gitfame'? –
Idzik
Why am I seeing "Note: Files matching MIME type image, binary has been ignored" –
Idzik
@AlexanderMills I'm guessing it is because you can't meaningfully count lines on blobs –
Nomarchy
Obviously never sudo install packages, both because you're sudo installing, and because you're installing to your OS's core python installation lol –
Primaveria
@AndyRay do you mean
sudo apt-get install python-pip? What's the better command? –
Nomarchy @BarryZhong thanks for the feedback, if you can provide a reproduction, please create a bug in their bug tracker, and I'll link to it. –
Nomarchy
warning: file with emoji in name crashed whole git fame :D –
Mary
If you are windows user you need to run
python -m gitfame in project folder after installation of this package. –
Embree Not able to specify multiple file extensions for inclusion. This works
git fame --incl=".java", but this doesn't - git fame --incl=".java,.json" –
Mastermind Which project is the sample from? –
Unconscionable
I found the following to be useful to see who had the most lines that were currently in the code base:
git ls-files -z | xargs -0n1 git blame -w | ruby -n -e '$_ =~ /^.*\((.*?)\s[\d]{4}/; puts $1.strip' | sort -f | uniq -c | sort -n
The other answers have mostly focused on lines changed in commits, but if commits don't survive and are overwritten, they may just have been churn. The above incantation also gets you all committers sorted by lines instead of just one at a time. You can add some options to git blame (-C -M) to get some better numbers that take file movement and line movement between files into account, but the command might run a lot longer if you do.
Also, if you're looking for lines changed in all commits for all committers, the follow little script is helpful:
I was about to give a +1, but then I realised that solution depends from ruby... :( –
Caroylncarp
You could modify it to not use ruby pretty easily since I just use ruby for the string substitution. You could use perl, sed, python, etc –
Hyperostosis
@Hyperostosis https://mcmap.net/q/65218/-git-blame-commit-statistics there is also a non ruby version –
Biotype
doesn't work for me: -e:1:in `<main>': invalid byte sequence in UTF-8 (ArgumentError) –
Swedenborgianism
/^.*\((.*?)\s[\d]{4}/ should be /^.*?\((.*?)\s[\d]{4}/ to prevent matching parentheses in the source as an author. –
Rosenberg @MichałDębski didn't work me either, see my answer for a more robust variant https://mcmap.net/q/63987/-how-to-count-total-lines-changed-by-a-specific-author-in-a-git-repository –
Alverta
how can I make it ignore certain set of file extensions? –
Finish
mmm my executions showed lots of user that don't even exists, due to bad parsing. I think it isn't a reliable answer. –
Creosol
The option
-C should be given twice -C -C. Otherwise it attributes all the lines in a newly created file to its committer even if it is a complete copy of an already existed file. Such a weird syntax... –
Mercurio So great answer but I was getting one of the authors as:
int i = 0; i < and I'm pretty sure part of a for loop didn't write any of the codebase =) I fixed it with the following sed replacing the ruby ...sed -r "s/.*\((.*)\s[[:digit:]]{4}-[[:digit:]]{2}-[[:digit:]]{2}.*/\1/g"... –
Aestivation After looking at Alex's and Gerty3000's answer, I have tried to shorten the one-liner:
Basically, using git log numstat and not keeping track of the number of files changed.
Git version 2.1.0 on Mac OSX:
git log --format='%aN' | sort -u | while read name; do echo -en "$name\t"; git log --author="$name" --pretty=tformat: --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }' -; done
Example:
Jared Burrows added lines: 6826, removed lines: 2825, total lines: 4001
This was the most useful to me –
Tombstone
To count number of commits by a given author (or all authors) on a given branch you can use git-shortlog; see especially its --numbered and --summary options, e.g. when run on git repository:
$ git shortlog v1.6.4 --numbered --summary
6904 Junio C Hamano
1320 Shawn O. Pearce
1065 Linus Torvalds
692 Johannes Schindelin
443 Eric Wong
Note that
v1.6.4 is here in this example to make output deterministic: it will be the same no matter when did you clone and/or fetch from git repository. –
Douai including
v1.6.4 gives me: fatal: ambiguous argument 'v1.6.4': unknown revision or path not in the working tree. –
Roseannaroseanne @Vlad: did you run this command in git.git repository (the git repository of the git source code)? WORKSFORME –
Douai
Ah, no, I missed "when run on git repository". To be fair, most people wont run this command on the git repo. By a pretty big margin, actually. –
Roseannaroseanne
git shortlog -sne or, if you'd rather not include merges git shortlog -sne --no-merges –
Poleyn @Swards:
-s is --summary, -n is --numbered, and [new] -e is --email to show emails of authors (and count separately the same author with different email address, taking into account .mailmap corrections). Good call about --no-merges. –
Douai How does it tell the number of lines ? It tells only the number commits. Doesn't it ? –
Floe
Please don't delete
v1.6.4 from code snippet - it is what makes result reproductible (which means that anybody running the command will get the same results). –
Douai Shortlog is useful. Agree it does't technically answer the question, but the way Google works, often searches for "by author" bring up these kind of answers. Isn't obvious that you mean the git.git repo btw. I realised that the tag specified is just an example though –
Th
The Answer from AaronM using the shell one-liner is good, but actually, there is yet another bug, where spaces will corrupt the user names if there are different amounts of white spaces between the user name and the date. The corrupted user names will give multiple rows for user counts and you have to sum them up yourself.
This small change fixed the issue for me:
git ls-files -z | xargs -0n1 git blame -w --show-email | perl -n -e '/^.*?\((.*?)\s+[\d]{4}/; print $1,"\n"' | sort -f | uniq -c | sort -n
Notice the + after \s which will consume all whitespaces from the name to the date.
Actually adding this answer as much for my own rememberance as for helping anyone else, since this is at least the second time I google the subject :)
- Edit 2019-01-23 Added
--show-emailtogit blame -wto aggregate on email instead, since some people use differentNameformats on different computers, and sometimes two people with the same name are working in the same git.
This answer using perl appeared to fare a little better than the ruby based ones. Ruby choked on lines that were not actual UTF-8 text, perl did not complain. But did perl do the right thing? I don't know. –
Alverta
Submodules result into
unsupported file type but otherwise it seems to work OK even with them (it skips them). –
Bratwurst Here's a short one-liner that produces stats for all authors. It's much faster than Dan's solution above at https://mcmap.net/q/63987/-how-to-count-total-lines-changed-by-a-specific-author-in-a-git-repository (mine has time complexity O(N) instead of O(NM) where N is the number of commits, and M the number of authors).
git log --no-merges --pretty=format:%an --numstat | awk '/./ && !author { author = $0; next } author { ins[author] += $1; del[author] += $2 } /^$/ { author = ""; next } END { for (a in ins) { printf "%10d %10d %10d %s\n", ins[a] - del[a], ins[a], del[a], a } }' | sort -rn
Nice but what does the output mean? –
Sahara
You should add
--no-show-signature, otherwise people who pgp-sign their commits aren't going to get counted. –
Tenaille ins[a] - del[a], ins[a], del[a], a , so if i'm right insertion-deletion, insertion, deletion, name –
Letterperfect
How can I add this command to my git config so that I can call it with "git count-lines"? –
Sonatina
Never mind, I figured it out:
count-lines = "!f() { git log --no-merges --pretty=format:%an --numstat | awk '/./ && !author { author = $0; next } author { ins[author] += $1; del[author] += $2 } /^$/ { author = \"\"; next } END { for (a in ins) { printf \"%10d %10d %10d %s\\n\", ins[a] - del[a], ins[a], del[a], a } }' | sort -rn; }; f". (Note I'm on Windows; you may need to use different kinds of quotes) –
Sonatina Nice! Though I don't think it sorts in linear time given the use of
sort. Even though it's using the numeric sorting algorithm. –
Prudential @mmrobins @AaronM @ErikZ @JamesMishra provided variants that all have an problem in common: they ask git to produce a mixture of info not intended for script consumption, including line contents from repository on the same line, then match the mess with a regexp.
This is a problem when some lines aren't valid UTF-8 text, and also when some lines happen to match the regexp (this happened here).
Here's a modified line that doesn't have these problems. It requests git to output data cleanly on separate lines, which makes it easy to filter what we want robustly:
git ls-files -z | xargs -0n1 git blame -w --line-porcelain | grep -a "^author " | sort -f | uniq -c | sort -n
You can grep for other strings, like author-mail, committer, etc.
Perhaps first do export LC_ALL=C (assuming bash) to force byte-level processing (this also happens to speed up grep tremendously from the UTF-8-based locales).
Nice line there, very cool, that you can easily mix it up, however this fails to do what the original poster requested, provide a count by author from git. Sure you could run it and do a wc-l, etc, but then you would need to repeat for every author in the repository. –
Stannfield
@Stannfield I don't understand your criticism. This line AFAIK outputs the same statistics as yours, only more robust. So, if my answer "fails to do what the original poster requested, provide a count by author from git", then yours even more. Please enlighten me. –
Alverta
sorry I misread, I thought the command had to be modified for each different authors name. Your comment about grep for other strings led me there but it was my misunderstanding. –
Stannfield
@StéphaneGourichon Is this solution suitable to see who contributed how many lines that are currently (!) in the code base? –
Belongings
@Belongings if I understand your question correctly, yes. –
Alverta
A solution was given with ruby in the middle, perl being a little more available by default here is an alternative using perl for current lines by author.
git ls-files -z | xargs -0n1 git blame -w | perl -n -e '/^.*\((.*?)\s*[\d]{4}/; print $1,"\n"' | sort -f | uniq -c | sort -n
Updated regex doesn't make a meaningful difference, and it is broken as you did not escape the first paren. However, I can see some cases where my previous one might find some bits in the line of code to latch onto. This would work more reliably:git ls-files -z | xargs -0n1 git blame -w | perl -n -e '/^.*?\((.*?)\s[\d]{4}/; print $1,"\n"' | sort -f | uniq -c | sort -n –
Stannfield
thanks for trying to make a more reliable regexp. See my answer for a more robust variant https://mcmap.net/q/63987/-how-to-count-total-lines-changed-by-a-specific-author-in-a-git-repository –
Alverta
you can use whodid (https://www.npmjs.com/package/whodid)
$ npm install whodid -g
$ cd your-project-dir
and
$ whodid author --include-merge=false --path=./ --valid-threshold=1000 --since=1.week
or just type
$ whodid
then you can see result like this
Contribution state
=====================================================
score | author
-----------------------------------------------------
3059 | someguy <[email protected]>
585 | somelady <[email protected]>
212 | niceguy <[email protected]>
173 | coolguy <[email protected]>
=====================================================
What does 'score' mean? –
Fertile
Here is a great repo that makes your life easier
git-quick-stats
On a mac with brew installed
brew install git-quick-stats
Run
git-quick-stats
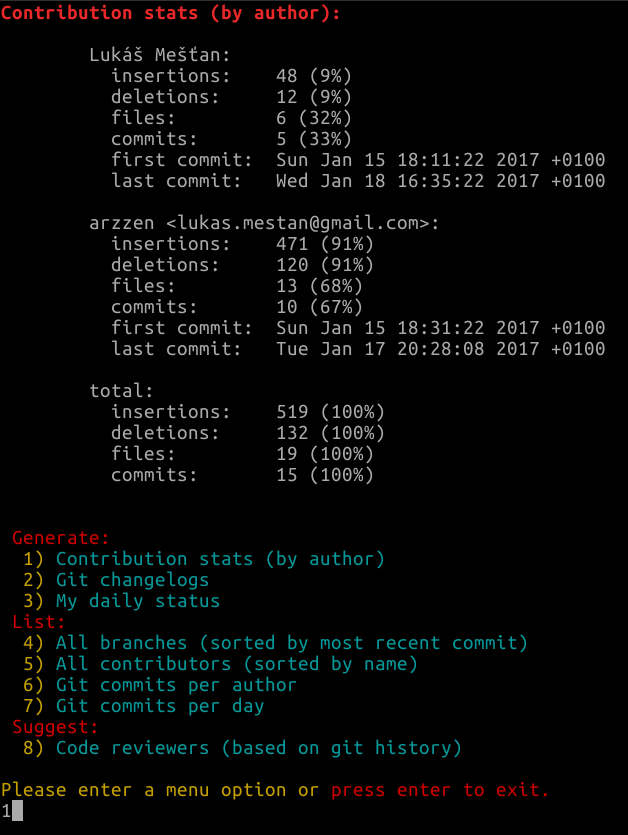
Just choose which option you want from this list by typing in the number listed and hitting enter.
Generate:
1) Contribution stats (by author)
2) Contribution stats (by author) on a specific branch
3) Git changelogs (last 10 days)
4) Git changelogs by author
5) My daily status
6) Save git log output in JSON format
List:
7) Branch tree view (last 10)
8) All branches (sorted by most recent commit)
9) All contributors (sorted by name)
10) Git commits per author
11) Git commits per date
12) Git commits per month
13) Git commits per weekday
14) Git commits per hour
15) Git commits by author per hour
Suggest:
16) Code reviewers (based on git history)
In addition to Charles Bailey's answer, you might want to add the -C parameter to the commands. Otherwise file renames count as lots of additions and removals (as many as the file has lines), even if the file content was not modified.
To illustrate, here is a commit with lots of files being moved around from one of my projects, when using the git log --oneline --shortstat command:
9052459 Reorganized project structure
43 files changed, 1049 insertions(+), 1000 deletions(-)
And here the same commit using the git log --oneline --shortstat -C command which detects file copies and renames:
9052459 Reorganized project structure
27 files changed, 134 insertions(+), 85 deletions(-)
In my opinion the latter gives a more realistic view of how much impact a person has had on the project, because renaming a file is a much smaller operation than writing the file from scratch.
When i execute "git log --oneline --shortstat", i don't obtain your result. I have a list of commit with the number of editions but not the total number. How can i get the total number of lines edited in all git repository ? –
Sphericity
Here's a quick ruby script that corrals up the impact per user against a given log query.
For example, for rubinius:
Brian Ford: 4410668
Evan Phoenix: 1906343
Ryan Davis: 855674
Shane Becker: 242904
Alexander Kellett: 167600
Eric Hodel: 132986
Dirkjan Bussink: 113756
...
the script:
#!/usr/bin/env ruby
impact = Hash.new(0)
IO.popen("git log --pretty=format:\"%an\" --shortstat #{ARGV.join(' ')}") do |f|
prev_line = ''
while line = f.gets
changes = /(\d+) insertions.*(\d+) deletions/.match(line)
if changes
impact[prev_line] += changes[1].to_i + changes[2].to_i
end
prev_line = line # Names are on a line of their own, just before the stats
end
end
impact.sort_by { |a,i| -i }.each do |author, impact|
puts "#{author.strip}: #{impact}"
end
This script is great, but excludes authors who has only single-line commits! To fix, change as follows: changes = /(\d+) insertion.*(\d+) deletion/.match(line) –
Battlefield
I noticed only the last number of the deletions was being matched. A literal space between
* & ( is needed. For example, in a match of ` 1 file changed, 1 insertions(+), 123 deletions(-)` only the 3 would get matched for the deletions count. (\d+) insertion.* (\d+) deletion seemed to do the trick. –
Howse this is the best way and it also gives you a clear picture of total number of commits by all the user
git shortlog -s -n
Useful, but that's number of commits not total code lines –
Arndt
I provided a modification of a short answer above, but it wasnt sufficient for my needs. I needed to be able to categorize both committed lines and lines in the final code. I also wanted a break down by file. This code does not recurse, it will only return the results for a single directory, but it is a good start if someone wanted to go further. Copy and paste into a file and make executable or run it with Perl.
#!/usr/bin/perl
use strict;
use warnings;
use Data::Dumper;
my $dir = shift;
die "Please provide a directory name to check\n"
unless $dir;
chdir $dir
or die "Failed to enter the specified directory '$dir': $!\n";
if ( ! open(GIT_LS,'-|','git ls-files') ) {
die "Failed to process 'git ls-files': $!\n";
}
my %stats;
while (my $file = <GIT_LS>) {
chomp $file;
if ( ! open(GIT_LOG,'-|',"git log --numstat $file") ) {
die "Failed to process 'git log --numstat $file': $!\n";
}
my $author;
while (my $log_line = <GIT_LOG>) {
if ( $log_line =~ m{^Author:\s*([^<]*?)\s*<([^>]*)>} ) {
$author = lc($1);
}
elsif ( $log_line =~ m{^(\d+)\s+(\d+)\s+(.*)} ) {
my $added = $1;
my $removed = $2;
my $file = $3;
$stats{total}{by_author}{$author}{added} += $added;
$stats{total}{by_author}{$author}{removed} += $removed;
$stats{total}{by_author}{total}{added} += $added;
$stats{total}{by_author}{total}{removed} += $removed;
$stats{total}{by_file}{$file}{$author}{added} += $added;
$stats{total}{by_file}{$file}{$author}{removed} += $removed;
$stats{total}{by_file}{$file}{total}{added} += $added;
$stats{total}{by_file}{$file}{total}{removed} += $removed;
}
}
close GIT_LOG;
if ( ! open(GIT_BLAME,'-|',"git blame -w $file") ) {
die "Failed to process 'git blame -w $file': $!\n";
}
while (my $log_line = <GIT_BLAME>) {
if ( $log_line =~ m{\((.*?)\s+\d{4}} ) {
my $author = $1;
$stats{final}{by_author}{$author} ++;
$stats{final}{by_file}{$file}{$author}++;
$stats{final}{by_author}{total} ++;
$stats{final}{by_file}{$file}{total} ++;
$stats{final}{by_file}{$file}{total} ++;
}
}
close GIT_BLAME;
}
close GIT_LS;
print "Total lines committed by author by file\n";
printf "%25s %25s %8s %8s %9s\n",'file','author','added','removed','pct add';
foreach my $file (sort keys %{$stats{total}{by_file}}) {
printf "%25s %4.0f%%\n",$file
,100*$stats{total}{by_file}{$file}{total}{added}/$stats{total}{by_author}{total}{added};
foreach my $author (sort keys %{$stats{total}{by_file}{$file}}) {
next if $author eq 'total';
if ( $stats{total}{by_file}{$file}{total}{added} ) {
printf "%25s %25s %8d %8d %8.0f%%\n",'', $author,@{$stats{total}{by_file}{$file}{$author}}{qw{added removed}}
,100*$stats{total}{by_file}{$file}{$author}{added}/$stats{total}{by_file}{$file}{total}{added};
} else {
printf "%25s %25s %8d %8d\n",'', $author,@{$stats{total}{by_file}{$file}{$author}}{qw{added removed}} ;
}
}
}
print "\n";
print "Total lines in the final project by author by file\n";
printf "%25s %25s %8s %9s %9s\n",'file','author','final','percent', '% of all';
foreach my $file (sort keys %{$stats{final}{by_file}}) {
printf "%25s %4.0f%%\n",$file
,100*$stats{final}{by_file}{$file}{total}/$stats{final}{by_author}{total};
foreach my $author (sort keys %{$stats{final}{by_file}{$file}}) {
next if $author eq 'total';
printf "%25s %25s %8d %8.0f%% %8.0f%%\n",'', $author,$stats{final}{by_file}{$file}{$author}
,100*$stats{final}{by_file}{$file}{$author}/$stats{final}{by_file}{$file}{total}
,100*$stats{final}{by_file}{$file}{$author}/$stats{final}{by_author}{total}
;
}
}
print "\n";
print "Total lines committed by author\n";
printf "%25s %8s %8s %9s\n",'author','added','removed','pct add';
foreach my $author (sort keys %{$stats{total}{by_author}}) {
next if $author eq 'total';
printf "%25s %8d %8d %8.0f%%\n",$author,@{$stats{total}{by_author}{$author}}{qw{added removed}}
,100*$stats{total}{by_author}{$author}{added}/$stats{total}{by_author}{total}{added};
};
print "\n";
print "Total lines in the final project by author\n";
printf "%25s %8s %9s\n",'author','final','percent';
foreach my $author (sort keys %{$stats{final}{by_author}}) {
printf "%25s %8d %8.0f%%\n",$author,$stats{final}{by_author}{$author}
,100*$stats{final}{by_author}{$author}/$stats{final}{by_author}{total};
}
Addressed the illegal division by zero on line 71. Think it occurs if there are no edits but it was a while ago I wrote this. –
Stannfield
The question asked for information on a specific author, but many of the answers were solutions that returned ranked lists of authors based on their lines of code changed.
This was what I was looking for, but the existing solutions were not quite perfect. In the interest of people that may find this question via Google, I've made some improvements on them and made them into a shell script, which I display below.
There are no dependencies on either Perl or Ruby. Furthermore, whitespace, renames, and line movements are taken into account in the line change count. Just put this into a file and pass your Git repository as the first parameter.
#!/bin/bash
git --git-dir="$1/.git" log > /dev/null 2> /dev/null
if [ $? -eq 128 ]
then
echo "Not a git repository!"
exit 128
else
echo -e "Lines | Name\nChanged|"
git --work-tree="$1" --git-dir="$1/.git" ls-files -z |\
xargs -0n1 git --work-tree="$1" --git-dir="$1/.git" blame -C -M -w |\
cut -d'(' -f2 |\
cut -d2 -f1 |\
sed -e "s/ \{1,\}$//" |\
sort |\
uniq -c |\
sort -nr
fi
Save your logs into file using:
git log --author="<authorname>" --oneline --shortstat > logs.txt
For Python lovers:
with open(r".\logs.txt", "r", encoding="utf8") as f:
files = insertions = deletions = 0
for line in f:
if ' changed' in line:
line = line.strip()
spl = line.split(', ')
if len(spl) > 0:
files += int(spl[0].split(' ')[0])
if len(spl) > 1:
insertions += int(spl[1].split(' ')[0])
if len(spl) > 2:
deletions += int(spl[2].split(' ')[0])
print(str(files).ljust(10) + ' files changed')
print(str(insertions).ljust(10) + ' insertions')
print(str(deletions).ljust(10) + ' deletions')
Your outputs would be like:
225 files changed
6751 insertions
1379 deletions
For windows users you can use following batch script that counts added/removed lines for specified author
@echo off
set added=0
set removed=0
for /f "tokens=1-3 delims= " %%A in ('git log --pretty^=tformat: --numstat --author^=%1') do call :Count %%A %%B %%C
@echo added=%added%
@echo removed=%removed%
goto :eof
:Count
if NOT "%1" == "-" set /a added=%added% + %1
if NOT "%2" == "-" set /a removed=%removed% + %2
goto :eof
https://gist.github.com/zVolodymyr/62e78a744d99d414d56646a5e8a1ff4f
The best tool so far I identfied is gitinspector. It give the set report per user, per week etc You can install like below with npm
npm install -g gitinspector
The links to get the more details
https://www.npmjs.com/package/gitinspector
https://github.com/ejwa/gitinspector/wiki/Documentation
https://github.com/ejwa/gitinspector
example commands are
gitinspector -lmrTw
gitinspector --since=1-1-2017 etc
I wrote this Perl script to accomplish that task.
#!/usr/bin/env perl
use strict;
use warnings;
# save the args to pass to the git log command
my $ARGS = join(' ', @ARGV);
#get the repo slug
my $NAME = _get_repo_slug();
#get list of authors
my @authors = _get_authors();
my ($projectFiles, $projectInsertions, $projectDeletions) = (0,0,0);
#for each author
foreach my $author (@authors) {
my $command = qq{git log $ARGS --author="$author" --oneline --shortstat --no-merges};
my ($files, $insertions, $deletions) = (0,0,0);
my @lines = `$command`;
foreach my $line (@lines) {
if ($line =~ m/^\s(\d+)\s\w+\s\w+,\s(\d+)\s\w+\([\+|\-]\),\s(\d+)\s\w+\([\+|\-]\)$|^\s(\d+)\s\w+\s\w+,\s(\d+)\s\w+\(([\+|\-])\)$/) {
my $lineFiles = $1 ? $1 : $4;
my $lineInsertions = (defined $6 && $6 eq '+') ? $5 : (defined $2) ? $2 : 0;
my $lineDeletions = (defined $6 && $6 eq '-') ? $5 : (defined $3) ? $3 : 0;
$files += $lineFiles;
$insertions += $lineInsertions;
$deletions += $lineDeletions;
$projectFiles += $lineFiles;
$projectInsertions += $lineInsertions;
$projectDeletions += $lineDeletions;
}
}
if ($files || $insertions || $deletions) {
printf(
"%s,%s,%s,+%s,-%s,%s\n",
$NAME,
$author,
$files,
$insertions,
$deletions,
$insertions - $deletions
);
}
}
printf(
"%s,%s,%s,+%s,-%s,%s\n",
$NAME,
'PROJECT_TOTAL',
$projectFiles,
$projectInsertions,
$projectDeletions,
$projectInsertions - $projectDeletions
);
exit 0;
#get the remote.origin.url joins that last two pieces (project and repo folder)
#and removes any .git from the results.
sub _get_repo_slug {
my $get_remote_url = "git config --get remote.origin.url";
my $remote_url = `$get_remote_url`;
chomp $remote_url;
my @parts = split('/', $remote_url);
my $slug = join('-', @parts[-2..-1]);
$slug =~ s/\.git//;
return $slug;
}
sub _get_authors {
my $git_authors = 'git shortlog -s | cut -c8-';
my @authors = `$git_authors`;
chomp @authors;
return @authors;
}
I named it git-line-changes-by-author and put into /usr/local/bin. Because it is saved in my path, I can issue the command git line-changes-by-author --before 2018-12-31 --after 2020-01-01 to get the report for the 2019 year. As an example. And if I were to misspell the name git will suggest the proper spelling.
You may want to adjust the _get_repo_slug sub to only include the last portion of the remote.origin.url as my repos are saved as project/repo and your might not be.
This script here will do it. Put it into authorship.sh, chmod +x it, and you're all set.
#!/bin/sh
declare -A map
while read line; do
if grep "^[a-zA-Z]" <<< "$line" > /dev/null; then
current="$line"
if [ -z "${map[$current]}" ]; then
map[$current]=0
fi
elif grep "^[0-9]" <<<"$line" >/dev/null; then
for i in $(cut -f 1,2 <<< "$line"); do
map[$current]=$((map[$current] + $i))
done
fi
done <<< "$(git log --numstat --pretty="%aN")"
for i in "${!map[@]}"; do
echo -e "$i:${map[$i]}"
done | sort -nr -t ":" -k 2 | column -t -s ":"
no it WONT !, you posted this elsewhere, it generates errors on macs and linux, you know, the type of computers git was made on ! –
Geisel
You want Git blame.
There's a --show-stats option to print some, well, stats.
I tried
blame, but it didn't really give the stats I thought the OP would need? –
Tigges © 2022 - 2024 — McMap. All rights reserved.
git://git.lwn.net/gitdm.git. – Ere