What is the difference between a generative and a discriminative algorithm?
What is the difference between a generative and a discriminative algorithm? [closed]
Asked Answered
This document (also pointed out by anguyen8 below) is a good one: cs229.stanford.edu/notes/cs229-notes2.pdf –
Stewart
See also the same question on stats.SE: Generative vs. Discriminative –
Euboea
I’m voting to close this question because [Machine learning (ML) theory questions are off-topic on Stack Overflow](ttps://meta.https://mcmap.net/q/64943/-passing-around-xml-object-vs-populating-a-struct/291015#291015) - gift-wrap candidate for Cross-Validated –
Theodolite
That link is broken; here's the correct version: meta.#291509 –
Appraisal
Let's say you have input data x and you want to classify the data into labels y. A generative model learns the joint probability distribution p(x,y) and a discriminative model learns the conditional probability distribution p(y|x) - which you should read as "the probability of y given x".
Here's a really simple example. Suppose you have the following data in the form (x,y):
(1,0), (1,0), (2,0), (2, 1)
p(x,y) is
y=0 y=1
-----------
x=1 | 1/2 0
x=2 | 1/4 1/4
p(y|x) is
y=0 y=1
-----------
x=1 | 1 0
x=2 | 1/2 1/2
If you take a few minutes to stare at those two matrices, you will understand the difference between the two probability distributions.
The distribution p(y|x) is the natural distribution for classifying a given example x into a class y, which is why algorithms that model this directly are called discriminative algorithms. Generative algorithms model p(x,y), which can be transformed into p(y|x) by applying Bayes rule and then used for classification. However, the distribution p(x,y) can also be used for other purposes. For example, you could use p(x,y) to generate likely (x,y) pairs.
From the description above, you might be thinking that generative models are more generally useful and therefore better, but it's not as simple as that. This paper is a very popular reference on the subject of discriminative vs. generative classifiers, but it's pretty heavy going. The overall gist is that discriminative models generally outperform generative models in classification tasks.
Thanks for the paper. The author is now professor at Stanford and has wonderful resources at stanford.edu/class/cs229/materials.html –
Roden
A nice explanation also by Andrew Ng here –
Wilberwilberforce
When staring at the matrices observe that in the first one, all entries sum up to 1.0, while in the second one each row sums up to one. This will speed the enlightenment (and reduce confusion) –
Complect
A note by Andrew Ng here is also very useful: cs229.stanford.edu/notes/cs229-notes2.pdf –
Villous
The original paper link is gone, here's another: cs.cmu.edu/~aarti/Class/10701/readings/NgJordanNIPS2001.pdf –
Sorry
I believe you misrepresented that paper. The statement that discriminative was probably due to Vapnik. The paper it self is to say that discriminative isn't always better, and it depends on the regime. However, the paper looks at only Logistic Regression vs Naive Bayes. –
Dotterel
This is kind of hard paper to read. If you want the somewhat more accessible gist of - have a look at 10-601 by Tom Mitchell. –
Crowbar
"which is why algorithms that model this directly are called discriminative algorithms", still not sure why
p(y|x) implies that algorithms that model it are called "discriminative models". –
Worriment This is old but I just thought I'd add that even thought this has been chosen best answer, one thing was left out that is crucial in understanding why one outperforms the other depending on the size of the dataset. What was forgotten to mention is that for a discriminative model to outperform a generative model, the dataset has to be large enough for LR to have better performance, generative models tend to outperform discriminative models with small datasets. –
Trainbearer
For those who don't have time to read Ng & Jordan paper cited there, the main takeaway messages are: 1. the discriminative logistic regression algorithm has a lower asymptotic error, 2. the generative naive Bayes classifier may also converge more quickly to its (higher) asymptotic error. –
Koeppel
The videos by Andrew Ng mentioned by clyfe@ require flash, but the raw mp4's are here: openclassroom.stanford.edu/MainFolder/courses/MachineLearning/… –
Maher
A generative algorithm models how the data was generated in order to categorize a signal. It asks the question: based on my generation assumptions, which category is most likely to generate this signal?
A discriminative algorithm does not care about how the data was generated, it simply categorizes a given signal.
This answer confuses me. Both classes of algorithsm fall into the class of supervised learning algorithms, which learn a model of labeled training data to derive a function that predicts other data. The discrimitive algorithm as you describe it sounds as if it does not create a model, is that correct? I would be glad if you could enhence your answer in that regard. –
Euboea
@mcb A generative algorithm models how the data was "generated", so you ask it "what's the likelihood this or that class generated this instance?" and pick the one with the better probability. A discriminative algorithm uses the data to create a decision boundary, so you ask it "what side of the decision boundary is this instance on?" So it doesn't create a model of how the data was generated, it makes a model of what it thinks the boundary between classes looks like. –
Chancey
So a generative model like Naive Bayes, does not have a decision boundary? –
Pneuma
So generative models seem like they are better for interpretability? –
Discordancy
Imagine your task is to classify a speech to a language.
You can do it by either:
- learning each language, and then classifying it using the knowledge you just gained
or
- determining the difference in the linguistic models without learning the languages, and then classifying the speech.
The first one is the generative approach and the second one is the discriminative approach.
Check this reference for more details: http://www.cedar.buffalo.edu/~srihari/CSE574/Discriminative-Generative.pdf.
Isn't it the other way round? Considering that you learned the language, you are operating on a conditional distribution and so it should be a discriminative approach? –
Castoff
I think it is the other way around as well after reading the answers below - Example from the lecture notes of CS299 by Ghrua –
Untoward
In practice, the models are used as follows.
In discriminative models, to predict the label y from the training example x, you must evaluate:

which merely chooses what is the most likely class y considering x. It's like we were trying to model the decision boundary between the classes. This behavior is very clear in neural networks, where the computed weights can be seen as a complexly shaped curve isolating the elements of a class in the space.
Now, using Bayes' rule, let's replace the  in the equation by
in the equation by  . Since you are just interested in the arg max, you can wipe out the denominator, that will be the same for every
. Since you are just interested in the arg max, you can wipe out the denominator, that will be the same for every y. So, you are left with

which is the equation you use in generative models.
While in the first case you had the conditional probability distribution p(y|x), which modeled the boundary between classes, in the second you had the joint probability distribution p(x, y), since p(x | y) p(y) = p(x, y), which explicitly models the actual distribution of each class.
With the joint probability distribution function, given a y, you can calculate ("generate") its respective x. For this reason, they are called "generative" models.
By this reasoning, aren't the generative and the discriminative model equal when applied to the same distribution? Why is there a difference in classification behavior then? Or are they just equal in this maximum likelihood context? –
Prejudice
To tell whether they are "equal" or not, we need first define what we mean by that. The are many things in common, but the strongest difference is the strategy employed: model the distribution (generative) vs. predict a class, regardless of distribution (discriminative) -- think about KNN for a second for an example. –
Dobbins
@SaulBerardo If we have
p(x, y) how can we calculate p(x|y) p(y)? I mean we can derive it from conditional probability but we still don't know p(x|y) and p(y). Others define generative models as estimating the distribution p(x|y) so what is correct? –
Ethic Here's the most important part from the lecture notes of CS299 (by Andrew Ng) related to the topic, which really helps me understand the difference between discriminative and generative learning algorithms.
Suppose we have two classes of animals, elephant (y = 1) and dog (y = 0). And x is the feature vector of the animals.
Given a training set, an algorithm like logistic regression or the perceptron algorithm (basically) tries to find a straight line — that is, a decision boundary — that separates the elephants and dogs. Then, to classify a new animal as either an elephant or a dog, it checks on which side of the decision boundary it falls, and makes its prediction accordingly. We call these discriminative learning algorithm.
Here's a different approach. First, looking at elephants, we can build a model of what elephants look like. Then, looking at dogs, we can build a separate model of what dogs look like. Finally, to classify a new animal, we can match the new animal against the elephant model, and match it against the dog model, to see whether the new animal looks more like the elephants or more like the dogs we had seen in the training set. We call these generative learning algorithm.
The different models are summed up in the table below:
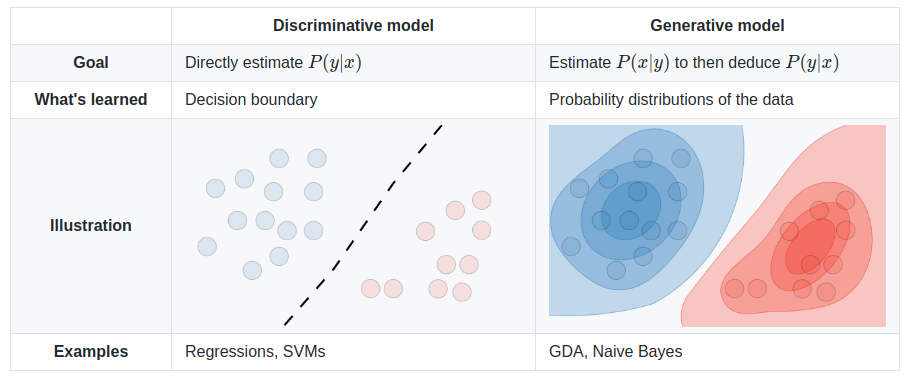
Image source: Supervised Learning cheatsheet - Stanford CS 229 (Machine Learning)
Generally, there is a practice in machine learning community not to learn something that you don’t want to. For example, consider a classification problem where one's goal is to assign y labels to a given x input. If we use generative model
p(x,y)=p(y|x).p(x)
we have to model p(x) which is irrelevant for the task in hand. Practical limitations like data sparseness will force us to model p(x) with some weak independence assumptions. Therefore, we intuitively use discriminative models for classification.
The short answer
Many of the answers here rely on the widely-used mathematical definition [1]:
- Discriminative models directly learn the conditional predictive distribution
p(y|x).- Generative models learn the joint distribution
p(x,y)(or rather,p(x|y)andp(y)).
- Predictive distribution
p(y|x)can be obtained with Bayes' rule.
Although very useful, this narrow definition assumes the supervised setting, and is less handy when examining unsupervised or semi-supervised methods. It also doesn't apply to many contemporary approaches for deep generative modeling. For example, now we have implicit generative models, e.g. Generative Adversarial Networks (GANs), which are sampling-based and don't even explicitly model the probability density p(x) (instead learning a divergence measure via the discriminator network). But we call them "generative models” since they are used to generate (high-dimensional [10]) samples.
A broader and more fundamental definition [2] seems equally fitting for this general question:
- Discriminative models learn the boundary between classes.
- So they can discriminate between different kinds of data instances.
- Generative models learn the distribution of data.
- So they can generate new data instances.
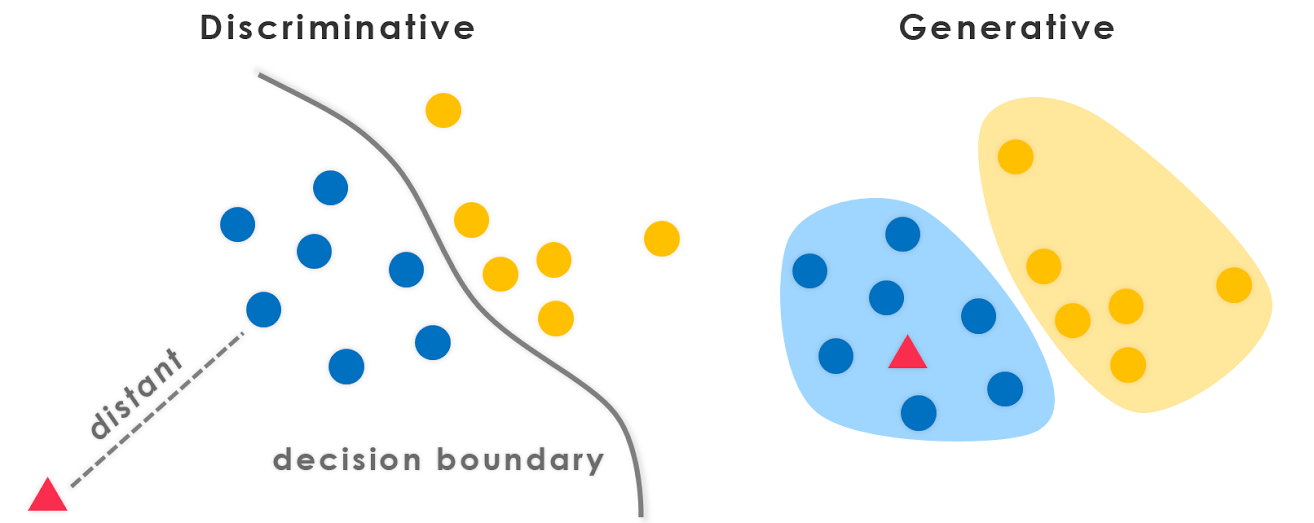
A closer look
Even so, this question implies somewhat of a false dichotomy [3]. The generative-discriminative "dichotomy" is in fact a spectrum which you can even smoothly interpolate between [4].
As a consequence, this distinction gets arbitrary and confusing, especially when many popular models do not neatly fall into one or the other [5,6], or are in fact hybrid models (combinations of classically "discriminative" and "generative" models).
Nevertheless it's still a highly useful and common distinction to make. We can list some clear-cut examples of generative and discriminative models, both canonical and recent:
- Generative: Naive Bayes, latent Dirichlet allocation (LDA), Generative Adversarial Networks (GAN), Variational Autoencoders (VAE), normalizing flows.
- Discriminative: Support vector machine (SVM), logistic regression, most deep neural networks.
There is also a lot of interesting work deeply examining the generative-discriminative divide [7] and spectrum [4,8], and even transforming discriminative models into generative models [9].
In the end, definitions are constantly evolving, especially in this rapidly growing field :) It's best to take them with a pinch of salt, and maybe even redefine them for yourself and others.
Sources
- Possibly originating from "Machine Learning - Discriminative and Generative" (Tony Jebara, 2004).
- Crash Course in Machine Learning by Google
- The Generative-Discriminative Fallacy
- "Principled Hybrids of Generative and Discriminative Models" (Lasserre et al., 2006)
- @shimao's question
- Binu Jasim's answer
- Comparing logistic regression and naive Bayes:
- https://www.microsoft.com/en-us/research/wp-content/uploads/2016/04/DengJaitly2015-ch1-2.pdf
- "Your classifier is secretly an energy-based model" (Grathwohl et al., 2019)
- Stanford CS236 notes: Technically, a probabilistic discriminative model is also a generative model of the labels conditioned on the data. However, the term generative models is typically reserved for high dimensional data.
This really should have more upvotes. Your was the only answer that touched on the "false dichotomy" idea I found. My question os similar to this one: stats.stackexchange.com/questions/408421/… –
Griz
An addition informative point that goes well with the answer by StompChicken above.
The fundamental difference between discriminative models and generative models is:
Discriminative models learn the (hard or soft) boundary between classes
Generative models model the distribution of individual classes
Edit:
A Generative model is the one that can generate data. It models both the features and the class (i.e. the complete data).
If we model P(x,y): I can use this probability distribution to generate data points - and hence all algorithms modeling P(x,y) are generative.
Eg. of generative models
Naive Bayes models
P(c)andP(d|c)- wherecis the class anddis the feature vector.Also,
P(c,d) = P(c) * P(d|c)Hence, Naive Bayes in some form models,
P(c,d)Bayes Net
Markov Nets
A discriminative model is the one that can only be used to discriminate/classify the data points.
You only require to model P(y|x) in such cases, (i.e. probability of class given the feature vector).
Eg. of discriminative models:
logistic regression
Neural Networks
Conditional random fields
In general, generative models need to model much more than the discriminative models and hence are sometimes not as effective. As a matter of fact, most (not sure if all) unsupervised learning algorithms like clustering etc can be called generative, since they model P(d) (and there are no classes:P)
PS: Part of the answer is taken from source
A generative algorithm model will learn completely from the training data and will predict the response.
A discriminative algorithm job is just to classify or differentiate between the 2 outcomes.
What I get is generative model is supervised learning based while discriminating model is based on unsupervised learning. Am I Right? –
Basham
@WaseemAhmadNaeem Kind of, but kind of not. y is always the target, and needed as part of the input data, so both are supervised. Generative seems unsupervised because the first step is to get the complete distribution (in all vars, not considering y as special). If you stopped there and don't treat y as special then that part by itself is unsupervised. –
Faenza
@Faenza can I ask you to share some paper / notes / link on difference of both? actually I'm bit confused over this concept. Thank you in advance –
Basham
@WaseemAhmadNaeem Search at Cross Validated.SE (the stats/ML SE site) in particular Generative vs Discriminative or Generative vs discriminative models in a Bayesian context. Elementary examples Naive Bayes is generative, Logistic Regression is discriminative. More examples of both. –
Faenza
All previous answers are great, and I'd like to plug in one more point.
From generative algorithm models, we can derive any distribution; while we can only obtain the conditional distribution P(Y|X) from the discriminative algorithm models(or we can say they are only useful for discriminating Y’s label), and that's why it is called discriminative model. The discriminative model doesn't assume that the X's are independent given the Y($X_i \perp X_{-i} | Y$) and hence is usually more powerful for calculating that conditional distribution.
My two cents: Discriminative approaches highlight differences Generative approaches do not focus on differences; they try to build a model that is representative of the class. There is an overlap between the two. Ideally both approaches should be used: one will be useful to find similarities and the other will be useful to find dis-similarities.
This article helped me a lot in understanding the concept.
In summary,
- Both are probabilistic models, meaning they both use probability (conditional probability , to be precise) to calculate classes for the unknown data.
- The Generative Classifiers apply Joint PDF & Bayes Theorem on the data set and calculate conditional probability using values from those.
- The Discriminative Classifiers directly find Conditional probablity on the data set
Some good reading material: conditional probability , Joint PDF
© 2022 - 2024 — McMap. All rights reserved.