R provides two different methods for accessing the elements of a list or data.frame: [] and [[]].
What is the difference between the two, and when should I use one over the other?
R provides two different methods for accessing the elements of a list or data.frame: [] and [[]].
What is the difference between the two, and when should I use one over the other?
The R Language Definition is handy for answering these types of questions:
R has three basic indexing operators, with syntax displayed by the following examples
x[i] x[i, j] x[[i]] x[[i, j]] x$a x$"a"For vectors and matrices the
[[forms are rarely used, although they have some slight semantic differences from the[form (e.g. it drops any names or dimnames attribute, and that partial matching is used for character indices). When indexing multi-dimensional structures with a single index,x[[i]]orx[i]will return theith sequential element ofx.For lists, one generally uses
[[to select any single element, whereas[returns a list of the selected elements.The
[[form allows only a single element to be selected using integer or character indices, whereas[allows indexing by vectors. Note though that for a list, the index can be a vector and each element of the vector is applied in turn to the list, the selected component, the selected component of that component, and so on. The result is still a single element.
[ always return a list means that you get the same output class for x[v] regardless of the length of v. For example, one might want to lapply over a subset of a list: lapply(x[v], fun). If [ would drop the list for vectors of length one, this would return an error whenever v has length one. –
Vish The significant differences between the two methods are the class of the objects they return when used for extraction and whether they may accept a range of values, or just a single value during assignment.
Consider the case of data extraction on the following list:
foo <- list( str='R', vec=c(1,2,3), bool=TRUE )
Say we would like to extract the value stored by bool from foo and use it inside an if() statement. This will illustrate the differences between the return values of [] and [[]] when they are used for data extraction. The [] method returns objects of class list (or data.frame if foo was a data.frame) while the [[]] method returns objects whose class is determined by the type of their values.
So, using the [] method results in the following:
if( foo[ 'bool' ] ){ print("Hi!") }
Error in if (foo["bool"]) { : argument is not interpretable as logical
class( foo[ 'bool' ] )
[1] "list"
This is because the [] method returned a list and a list is not valid object to pass directly into an if() statement. In this case we need to use [[]] because it will return the "bare" object stored in 'bool' which will have the appropriate class:
if( foo[[ 'bool' ]] ){ print("Hi!") }
[1] "Hi!"
class( foo[[ 'bool' ]] )
[1] "logical"
The second difference is that the [] operator may be used to access a range of slots in a list or columns in a data frame while the [[]] operator is limited to accessing a single slot or column. Consider the case of value assignment using a second list, bar():
bar <- list( mat=matrix(0,nrow=2,ncol=2), rand=rnorm(1) )
Say we want to overwrite the last two slots of foo with the data contained in bar. If we try to use the [[]] operator, this is what happens:
foo[[ 2:3 ]] <- bar
Error in foo[[2:3]] <- bar :
more elements supplied than there are to replace
This is because [[]] is limited to accessing a single element. We need to use []:
foo[ 2:3 ] <- bar
print( foo )
$str
[1] "R"
$vec
[,1] [,2]
[1,] 0 0
[2,] 0 0
$bool
[1] -0.6291121
Note that while the assignment was successful, the slots in foo kept their original names.
Double brackets accesses a list element, while a single bracket gives you back a list with a single element.
lst <- list('one','two','three')
a <- lst[1]
class(a)
## returns "list"
a <- lst[[1]]
class(a)
## returns "character"
From Hadley Wickham:
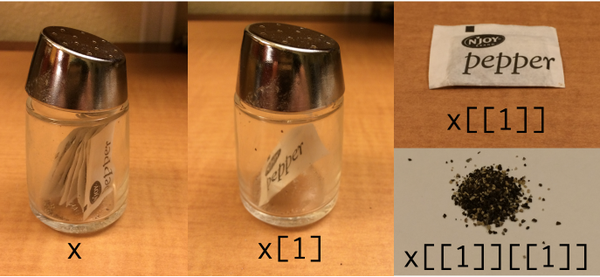
My (crappy looking) modification to show using tidyverse / purrr:

[] extracts a list, [[]] extracts elements within the list
alist <- list(c("a", "b", "c"), c(1,2,3,4), c(8e6, 5.2e9, -9.3e7))
str(alist[[1]])
chr [1:3] "a" "b" "c"
str(alist[1])
List of 1
$ : chr [1:3] "a" "b" "c"
str(alist[[1]][1])
chr "a"
Just adding here that [[ also is equipped for recursive indexing.
This was hinted at in the answer by @JijoMatthew but not explored.
As noted in ?"[[", syntax like x[[y]], where length(y) > 1, is interpreted as:
x[[ y[1] ]][[ y[2] ]][[ y[3] ]] ... [[ y[length(y)] ]]
Note that this doesn't change what should be your main takeaway on the difference between [ and [[ -- namely, that the former is used for subsetting, and the latter is used for extracting single list elements.
For example,
x <- list(list(list(1), 2), list(list(list(3), 4), 5), 6)
x
# [[1]]
# [[1]][[1]]
# [[1]][[1]][[1]]
# [1] 1
#
# [[1]][[2]]
# [1] 2
#
# [[2]]
# [[2]][[1]]
# [[2]][[1]][[1]]
# [[2]][[1]][[1]][[1]]
# [1] 3
#
# [[2]][[1]][[2]]
# [1] 4
#
# [[2]][[2]]
# [1] 5
#
# [[3]]
# [1] 6
To get the value 3, we can do:
x[[c(2, 1, 1, 1)]]
# [1] 3
Getting back to @JijoMatthew's answer above, recall r:
r <- list(1:10, foo=1, far=2)
In particular, this explains the errors we tend to get when mis-using [[, namely:
r[[1:3]]
Error in
r[[1:3]]: recursive indexing failed at level 2
Since this code actually tried to evaluate r[[1]][[2]][[3]], and the nesting of r stops at level one, the attempt to extract through recursive indexing failed at [[2]], i.e., at level 2.
Error in
r[[c("foo", "far")]]: subscript out of bounds
Here, R was looking for r[["foo"]][["far"]], which doesn't exist, so we get the subscript out of bounds error.
It probably would be a bit more helpful/consistent if both of these errors gave the same message.
Being terminological, [[ operator extracts the element from a list whereas [ operator takes subset of a list.
Both of them are ways of subsetting. The single bracket will return a subset of the list, which in itself will be a list. i.e., It may or may not contain more than one elements. On the other hand, a double bracket will return just a single element from the list.
-Single bracket will give us a list. We can also use single bracket if we wish to return multiple elements from the list. Consider the following list:
>r<-list(c(1:10),foo=1,far=2);
Now, please note the way the list is returned when I try to display it. I type r and press enter.
>r
#the result is:-
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
$foo
[1] 1
$far
[1] 2
Now we will see the magic of single bracket:
>r[c(1,2,3)]
#the above command will return a list with all three elements of the actual list r as below
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
$foo
[1] 1
$far
[1] 2
which is exactly the same as when we tried to display value of r on screen, which means the usage of single bracket has returned a list, where at index 1 we have a vector of 10 elements, then we have two more elements with names foo and far. We may also choose to give a single index or element name as input to the single bracket. e.g.,:
> r[1]
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
In this example, we gave one index "1" and in return got a list with one element(which is an array of 10 numbers)
> r[2]
$foo
[1] 1
In the above example, we gave one index "2" and in return got a list with one element:
> r["foo"];
$foo
[1] 1
In this example, we passed the name of one element and in return a list was returned with one element.
You may also pass a vector of element names like:
> x<-c("foo","far")
> r[x];
$foo
[1] 1
$far
[1] 2
In this example, we passed an vector with two element names "foo" and "far".
In return we got a list with two elements.
In short, a single bracket will always return you another list with number of elements equal to the number of elements or number of indices you pass into the single bracket.
In contrast, a double bracket will always return only one element.
Before moving to double bracket a note to be kept in mind.
NOTE:THE MAJOR DIFFERENCE BETWEEN THE TWO IS THAT SINGLE BRACKET RETURNS YOU A LIST WITH AS MANY ELEMENTS AS YOU WISH WHILE A DOUBLE BRACKET WILL NEVER RETURN A LIST. RATHER A DOUBLE BRACKET WILL RETURN ONLY A SINGLE ELEMENT FROM THE LIST.
I will site a few examples. Please keep a note of the words in bold and come back to it after you are done with the examples below:
Double bracket will return you the actual value at the index.(It will NOT return a list)
> r[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
>r[["foo"]]
[1] 1
for double brackets if we try to view more than one elements by passing a vector it will result in an error just because it was not built to cater to that need, but just to return a single element.
Consider the following
> r[[c(1:3)]]
Error in r[[c(1:3)]] : recursive indexing failed at level 2
> r[[c(1,2,3)]]
Error in r[[c(1, 2, 3)]] : recursive indexing failed at level 2
> r[[c("foo","far")]]
Error in r[[c("foo", "far")]] : subscript out of bounds
[] returns a list class even if it is a single digit is very unintuitive. They should've created another syntax like ([]) for the list and the [[]] to access the actual element is fine. I prefer to think of [[]] as the raw value like in other languages. –
Halfcocked [[ will happily return you a list if that is the selected element. The correct answer is that [ returns the selected item as a subset of its parent, while [[ returns the raw selected item in and of itself free of its parent object. –
Danonorwegian To help newbies navigate through the manual fog, it might be helpful to see the [[ ... ]] notation as a collapsing function - in other words, it is when you just want to 'get the data' from a named vector, list or data frame. It is good to do this if you want to use data from these objects for calculations. These simple examples will illustrate.
(x <- c(x=1, y=2)); x[1]; x[[1]]
(x <- list(x=1, y=2, z=3)); x[1]; x[[1]]
(x <- data.frame(x=1, y=2, z=3)); x[1]; x[[1]]
So from the third example:
> 2 * x[1]
x
1 2
> 2 * x[[1]]
[1] 2
iris[[1]] returns a vector, whereas iris[1] returns a data.frame –
Kop For yet another concrete use case, use double brackets when you want to select a data frame created by the split() function. If you don't know, split() groups a list/data frame into subsets based on a key field. It's useful if when you want to operate on multiple groups, plot them, etc.
> class(data)
[1] "data.frame"
> dsplit<-split(data, data$id)
> class(dsplit)
[1] "list"
> class(dsplit['ID-1'])
[1] "list"
> class(dsplit[['ID-1']])
[1] "data.frame"
Please refer the below-detailed explanation.
I have used Built-in data frame in R, called mtcars.
> mtcars
mpg cyl disp hp drat wt ...
Mazda RX4 21.0 6 160 110 3.90 2.62 ...
Mazda RX4 Wag 21.0 6 160 110 3.90 2.88 ...
Datsun 710 22.8 4 108 93 3.85 2.32 ...
............
The top line of the table is called the header which contains the column names. Each horizontal line afterward denotes a data row, which begins with the name of the row, and then followed by the actual data. Each data member of a row is called a cell.
To retrieve data in a cell, we would enter its row and column coordinates in the single square bracket "[]" operator. The two coordinates are separated by a comma. In other words, the coordinates begin with row position, then followed by a comma, and ends with the column position. The order is important.
Eg 1:- Here is the cell value from the first row, second column of mtcars.
> mtcars[1, 2]
[1] 6
Eg 2:- Furthermore, we can use the row and column names instead of the numeric coordinates.
> mtcars["Mazda RX4", "cyl"]
[1] 6
We reference a data frame column with the double square bracket "[[]]" operator.
Eg 1:- To retrieve the ninth column vector of the built-in data set mtcars, we write mtcars[[9]].
mtcars[[9]] [1] 1 1 1 0 0 0 0 0 0 0 0 ...
Eg 2:- We can retrieve the same column vector by its name.
mtcars[["am"]] [1] 1 1 1 0 0 0 0 0 0 0 0 ...
© 2022 - 2024 — McMap. All rights reserved.