Right now, your second model always answers "Class 0" as it can choose between only one class (number of outputs of your last layer).
As you have two classes, you need to compute the softmax + categorical_crossentropy on two outputs to pick the most probable one.
Hence, your last layer should be:
model.add(Dense(2, activation='softmax')
model.compile(...)
Your sigmoid + binary_crossentropy model, which computes the probability of "Class 0" being True by analyzing just a single output number, is already correct.
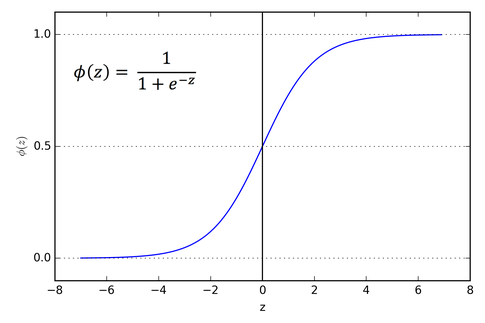
EDIT: Here is a small explanation about the Sigmoid function
Sigmoid can be viewed as a mapping between the real numbers space and a probability space.
![Sigmoid Function]()
Notice that:
Sigmoid(-infinity) = 0
Sigmoid(0) = 0.5
Sigmoid(+infinity) = 1
So if the real number, output of your network, is very low, the sigmoid will decide the probability of "Class 0" is close to 0, and decide "Class 1"
On the contrary, if the output of your network is very high, the sigmoid will decide the probability of "Class 0" is close to 1, and decide "Class 0"
Its decision is similar to deciding the Class only by looking at the sign of your output. However, this would not allow your model to learn! Indeed, the gradient of this binary loss is null nearly everywhere, making impossible for your model to learn from error, as it is not quantified properly.
That's why sigmoid and "binary_crossentropy" are used:
They are a surrogate to the binary loss, which has nice smooth properties, and enables learning.
Also, please find more info about Softmax Function and Cross Entropy