I'm new to Spark on YARN and don't understand the relation between the YARN Containers and the Spark Executors. I tried out the following configuration, based on the results of the yarn-utils.py script, that can be used to find optimal cluster configuration.
The Hadoop cluster (HDP 2.4) I'm working on:
- 1 Master Node:
- CPU: 2 CPUs with 6 cores each = 12 cores
- RAM: 64 GB
- SSD: 2 x 512 GB
- 5 Slave Nodes:
- CPU: 2 CPUs with 6 cores each = 12 cores
- RAM: 64 GB
- HDD: 4 x 3 TB = 12 TB
- HBase is installed (this is one of the parameters for the script below)
So I ran python yarn-utils.py -c 12 -m 64 -d 4 -k True (c=cores, m=memory, d=hdds, k=hbase-installed) and got the following result:
Using cores=12 memory=64GB disks=4 hbase=True
Profile: cores=12 memory=49152MB reserved=16GB usableMem=48GB disks=4
Num Container=8
Container Ram=6144MB
Used Ram=48GB
Unused Ram=16GB
yarn.scheduler.minimum-allocation-mb=6144
yarn.scheduler.maximum-allocation-mb=49152
yarn.nodemanager.resource.memory-mb=49152
mapreduce.map.memory.mb=6144
mapreduce.map.java.opts=-Xmx4915m
mapreduce.reduce.memory.mb=6144
mapreduce.reduce.java.opts=-Xmx4915m
yarn.app.mapreduce.am.resource.mb=6144
yarn.app.mapreduce.am.command-opts=-Xmx4915m
mapreduce.task.io.sort.mb=2457
These settings I made via the Ambari interface and restarted the cluster. The values also match roughly what I calculated manually before.
I have now problems
- to find the optimal settings for my
spark-submitscript- parameters
--num-executors,--executor-cores&--executor-memory.
- parameters
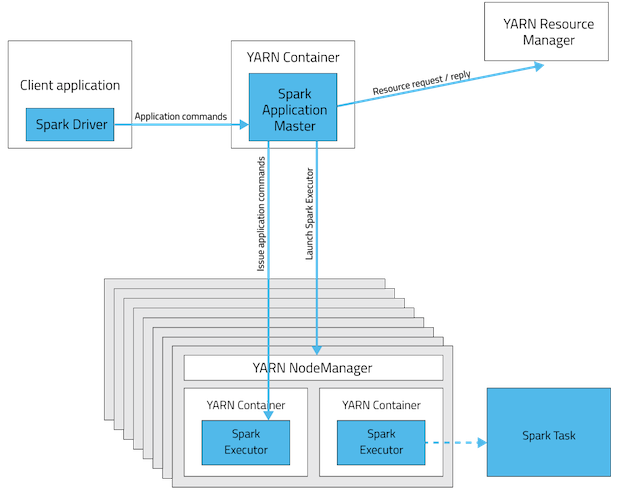
- to get the relation between the YARN container and the Spark executors
- to understand the hardware information in my Spark History UI (less memory shown as I set (when calculated to overall memory by multiplying with worker node amount))
- to understand the concept of the
vcoresin YARN, here I couldn't find any useful examples yet
However, I found this post What is a container in YARN? , but this didn't really help as it doesn't describe the relation to the executors.
Can someone help to solve one or more of the questions?
{kind=link}
yarn.nodemanager.resource.memory-mbon each cluster node? – Bushhammer