The recommended solution is to use an unmanaged compute environment. Unfortunately this ended up being poor advice because not only is creating your own unmanaged compute environment difficult and esoteric, and not only does it kind-of defeat the entire purpose of AWS batch, but there is a much better (and much simpler) solution.
The solution to this problem is to create an Amazon Machine Image that is dervied from the default AMI that AWS Batch uses. An AMI allows you to configure an operating system exactly how you want it by installing libraries, modifying startup scripts, customizing configuration files, and most importantly for our purposes: define the logical partitioning and mount points of data volumes.
1. Choose a base AMI to start from, configure your instance
The AMIs we want to base ourselves off of are the official ECS-optimized AMIs. Take a gander at this page to find which AMI you need according to the AWS region you are running on.
After identifying your AMI, click the “Launch instance” link in the righthand column. You’ll be taken to this page:
![enter image description here]()
Choose the t2.micro instance type.
Choose Next: Configuration Details.
Give your instance an appropriate IAM role if desired. What constitutes “appropriate” is at your discretion. Leave the rest of the default options.
Click Next: Add Storage.
Now is where you can configure what your data volumes will look like on your AMI. This step also does not define the final volume configuration for your AMI, but I find it to be useful to configure this how you want. You will have the opportunity to change this later before you create your AMI. Once you’re done, click Next: Add Tags.
Add any tags that you want (optional). Click Next: Configure Security Group.
Select SSH for Type, and set the Source to be Anywhere, or if you are more responsible than me, set a specific set of IP ranges that you know you will be using to connect to your instance. Click Review and Launch.
This page will allow you to review the options you have set. If everything looks good, then Launch. When it asks for a keypair, either select and existing keypair you’ve created, or create a new one. Failing to do this step will leave you unable to connect to your instance.
2. Configure your software environment
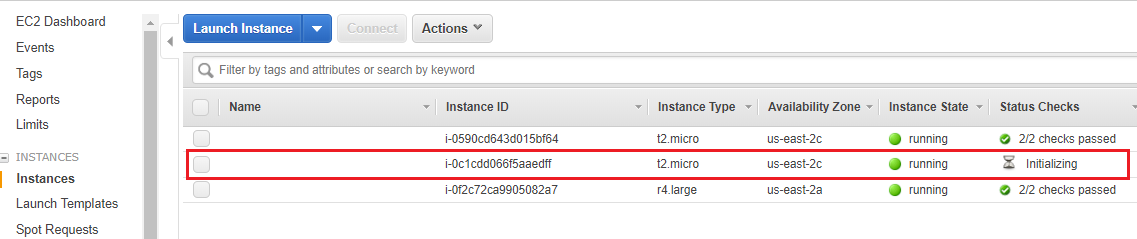
After you have clicked launch, go to your EC2 dashboard to see your running instances:
![enter image description here]()
Wait for your instance to start, then right click it. Click Connect, then copy-paste the Example ssh command into an ssh-capable terminal. The -i "keyname.pem" is actually a path to your .pem file, so make sure you either cd to your ~/.ssh directory, or change the flag’s value to be the path to where you stored your private SSH key. You also may need to change “root” to “ec2-user”.
![enter image description here]()
After you have logged in, you can configure your VM however you want by installing any packages, libraries, and configurations you need your VM to have. If you used the AWS-provided ECS-optimized AMI, your AMI will already meet the base requirements for an ECS AMI. If you for some (strange) reason choose not to use the ECS-optimized AMI, you will have install and configure the following packages:
- The latest version of the Amazon ECS container agent
- The latest version of the ecs-init agent
- The recommended version of Docker for your version of the ECS container agent.
Also note that if you want to attach another volume separate from your root volume, you will want to modify the /etc/fstab file so that your new volume is mounted on instance startup. I refer you to Google on how to do this.
3. Save your AMI
After all of your software configuration and installation is done, go back to your EC2 dashboard and view your running instances.
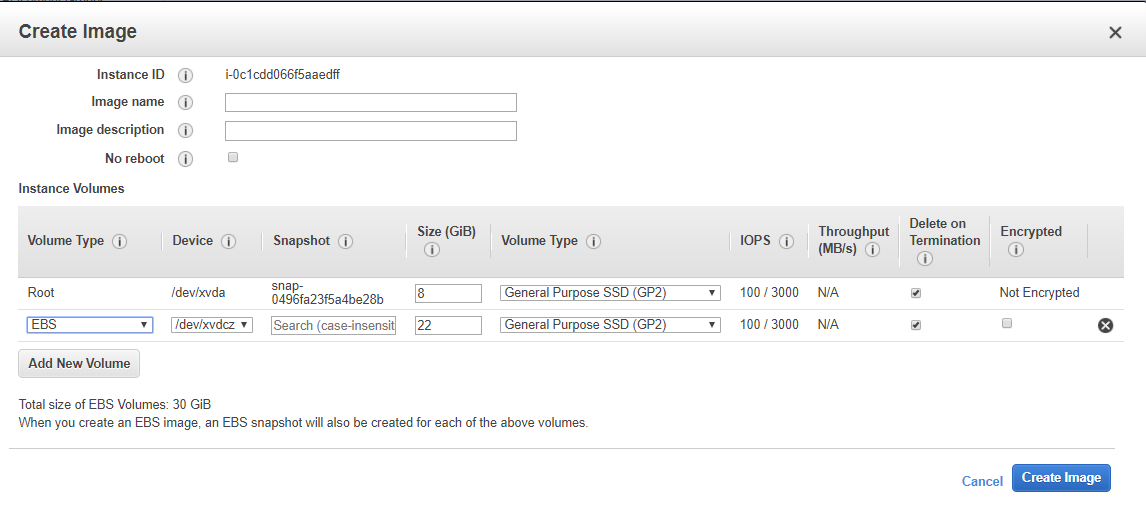
Right click on the instance you just made. Hover over Image, then select Create Image.
![enter image description here]()
You’ll see that this has the volume configuration you chose in Step 1. I did not change my volumes from their default settings, so you can see in the screenshot above that the default volumes for the ECS-optimized AMI are in fact 8GB for /dev/xvda/ (root), and 22GB for /dev/xvdc/ (docker images, etc). Ensure that the Delete on Termination options are selected so that your Batch compute environment removes the volumes after the instances are terminated, or else you’ll risk creating an unbounded number of EBS volumes (very expensive, so I’m told). I will configure my AMI to have only 111GB of root storage, and nothing else. You do not necessarily need a separate volume for Docker.
Give your image a name and description, then select Create Image.
Your instance will be rebooted. Once the instance is turned off, AWS will create an image of it, then turn the instance back on.
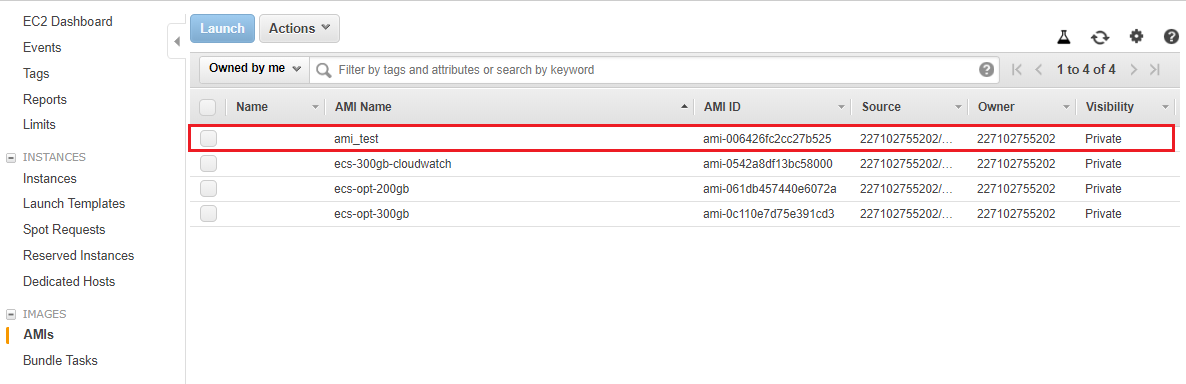
In your EC2 console, go to Images, AMIs on the left hand side. After a few minutes, you should see your newly created AMI in the list.
![enter image description here]()
4. Configure AWS Batch to use your new AMI
Go back to your AWS dashboard and navigate to the AWS Batch page. Select Compute environments on the left hand side. Select Create environment.
![enter image description here]()
Configure your environment by selecting the appropriate IAM roles for both your container (Service Role) and EC2 instance (Instance role), provisioning model, networking, and tags.
Option Value
Compute environment type Managed
Compute environment name ami_test
Service role AWSBatchServiceRole
Instance role ecsInstanceRole
EC2 key pair landonkey.pem (use name of your private key)
Provisioning model On-Demand (choose spot for significantly cheaper provisioning)
Allowed instance types Optimal
Minimum vCPUs 0
Desired vCPUs 0
Maximum vCPUs 256
Enable user-specified Ami ID True
AMI ID [ID of AMI you generated]
VPC id [default value]
Subnets [select all options]
Security groups default
The critical step for this is selecting Enable user-specified Ami ID and specifying the AMI ID you generated in previous steps.
Once all of your options are configured, select Create.
5. Create job queues and job definitions
In order to test that our compute environment actually works, let’s go ahead and create some simple queues and job definitions.
Select Job queues on the left hand side and enter the following options:
Option Value
Queue name ami_test_queue
Priority 1
Enable Job queue True
Select a compute environment ami_test
Select Create. Wait for the Status on your new queue to be VALID.
Go to Job definitions and select Create. Enter the following values:
Option Value
Job definition name ami_test_job_def
Job role ECS_Administrator
Container image amazonlinux
Command df -h
vCPUs 1
Memory (MiB) 1000
Job attempts 1
Execution timeout 100
Parameters [leave blank]
Environment variables [leave blank]
Volumes [leave blank]
Mount points [leave blank]
Select Create job definition.
Finally, go to Jobs on the left hand side and select Submit job. Give your job a name and select the ami_test_job_def:1 for the Job definition. Leave the rest of the default values and select Submit job.
If all goes well, you should now see that your job has entered either the Pending or Runnable states. Note that it may take upwards of 10 minutes before your job actually runs. The EC2 instance typically takes 5-10 minutes to be instantiated, and a few more minutes to pass status checks. If your job continues to be in the Runnable state after the instance has been created and has passed all status checks. Something has gone wrong.
![enter image description here]()