Given that this was answered almost four years ago, I thought I'd add an alternative and faster method which may not have been possible at the time. @TimSalabim's st_snap_points() function is great, but if you've got an sf collection with a few points, it can be done a bit faster using st_nearest_points() directly on the sf collection.
As mentioned by Tim and others in the discussion, st_nearest_points() returns a LINESTRING object - which is kinda confusing at first but can be easily turned into a POINT. It sounds like the order of the points in the LINESTRING always goes from the first to the second geometry, so you can pick out either the start or endpoint of the LINESTRING, depending which order you put the geometries into st_nearest_points().
See ?st_nearest_points:
Value
an sfc object with all two-point LINESTRING geometries of point pairs from the first to the second geometry, of length x * y, with y cycling fastest. See examples for ideas how to convert these to POINT geometries.
Using your example, we can find the closest point on the road by making the road the second object, and retrieving the endpoint (second point) of the LINESTRING as follows:
# find the LINESTRING object which is the shortest line between the two geometries
st_nearest_points(point1, roads) %>%
{. ->> my_linestring}
my_linestring
# Geometry set for 1 feature
# Geometry type: LINESTRING
# Dimension: XY
# Bounding box: xmin: 665491.2 ymin: 6525003 xmax: 665607 ymax: 6525003
# Projected CRS: WGS 84 / UTM zone 33N
# LINESTRING (665607 6525003, 665491.2 6525003)
# then, convert the LINESTRING to POINTs
# and, pull out the second point, because we want the point on the 'roads' object,
# which was supplied second to st_nearest_points()
my_linestring %>%
st_cast('POINT') %>%
.[2] %>%
{. ->> closest_point}
closest_point
# Geometry set for 1 feature
# Geometry type: POINT
# Dimension: XY
# Bounding box: xmin: 665491.2 ymin: 6525003 xmax: 665491.2 ymax: 6525003
# Projected CRS: WGS 84 / UTM zone 33N
# POINT (665491.2 6525003)
And we can look at it on a map to confirm:
library(tidyverse)
ggplot()+
geom_sf(data = roads, col = 'red')+
geom_sf(data = point1, col = 'black')+
geom_sf(data = closest_point, col = 'blue')
![enter image description here]()
To find the distance between the points we use st_distance():
# work out the distance
st_distance(point1, closest_point)[1]
# 115.7514 [m]
To incorporate a distance threshold into the "snapping", we can make a function which includes an if statement:
# we can combine the code and snap the point conditionally
f1 <- function(x, y, max_dist){
st_nearest_points(x, y) %>%
{. ->> my_linestring} %>%
st_cast('POINT') %>%
.[2] %>%
{. ->> closest_point} %>%
st_distance(., x) %>%
as.numeric %>%
{. ->> my_distance}
if(my_distance <= max_dist){
return(closest_point)
} else {
return(st_geometry(point1))
}
}
# run the function with threshold of 400 m (it should snap)
f1(point1, roads, max_dist = 400) %>%
{. ->> p1_400}
# run the function with a threshold of 50 m (it should NOT snap)
f1(point1, roads, max_dist = 50) %>%
{. ->> p1_50}
# plot it to see the results
ggplot()+
geom_sf(data = roads, col = 'red')+
geom_sf(data = p1_400, col = 'blue')+
geom_sf(data = p1_50)
# the blue point is on the road because it was within the threshold
# the black point is in the original spot because it was outside the threshold
![enter image description here]()
Working on an sf collection rather than a single point
Now, I'll assume that many instances will require this to be done on multiple points rather than a single point, and we can modify it slightly to use this approach on an sf collection with multiple points. To demonstrate this, first make up 100 random points within the bbox of roads:
set.seed(69)
# let's make some random points around the road
tibble(
x = runif(n = 100, min = st_bbox(roads)$xmin, max = st_bbox(roads)$xmax),
y = runif(n = 100, min = st_bbox(roads)$ymin, max = st_bbox(roads)$ymax),
id = 1:100
) %>%
st_as_sf(
x = .,
coords = c('x', 'y'),
crs = st_crs(roads)
) %>%
{. ->> my_points}
my_points
# Simple feature collection with 100 features and 1 field
# Geometry type: POINT
# Dimension: XY
# Bounding box: xmin: 664090.7 ymin: 6524310 xmax: 665500.6 ymax: 6526107
# Projected CRS: WGS 84 / UTM zone 33N
# # A tibble: 100 x 2
# id geometry
# * <int> <POINT [m]>
# 1 1 (664834.1 6525742)
# 2 2 (665176.8 6524370)
# 3 3 (664999.9 6525528)
# 4 4 (665315.7 6525242)
# 5 5 (664601 6525464)
# 6 6 (665320.7 6525600)
# 7 7 (664316.2 6525065)
# 8 8 (665204 6526025)
# 9 9 (664319.8 6524335)
# 10 10 (664101.7 6525830)
# # ... with 90 more rows
# now show the points on a figure
ggplot()+
geom_sf(data = roads, col = 'red')+
geom_sf(data = my_points, shape = 1)
![enter image description here]()
To find the closest point on roads to each of the random points, we use the same functions as the single point example above, but we save the LINESTRING as a column for each point. Then, instead of retrieving just the second point of the LINESTRING, we pull out every second point of the collection (column) of LINETRINGs. You have the option of pulling out the second point of every LINESTRING on a row-by-row basis, by including rowwise() before mutate(), but this makes for much slower computation. Instead, by working on the sf collection as a whole and pulling out every second point (the second point from each row), you get the result much much faster. This is how they demonstrate it in the example of ?st_nearest_points.
So basically, we make new columns in the sf collection using mutate() which includes the LINESTRING and the closest POINT.
# now, let's find the closest points
my_points %>%
mutate(
my_linestring = st_nearest_points(geometry, roads),
closest_point = st_cast(my_linestring, 'POINT')[seq(2, nrow(.)*2, 2)],
) %>%
{. ->> closest_points}
closest_points
# Simple feature collection with 100 features and 1 field
# Active geometry column: geometry
# Geometry type: POINT
# Dimension: XY
# Bounding box: xmin: 664090.7 ymin: 6524310 xmax: 665500.6 ymax: 6526107
# Projected CRS: WGS 84 / UTM zone 33N
# # A tibble: 100 x 4
# id geometry my_linestring closest_point
# * <int> <POINT [m]> <LINESTRING [m]> <POINT [m]>
# 1 1 (664834.1 6525742) (664834.1 6525742, 665309 6525745) (665309 6525745)
# 2 2 (665176.8 6524370) (665176.8 6524370, 665142.8 6524486) (665142.8 6524486)
# 3 3 (664999.9 6525528) (664999.9 6525528, 665337.9 6525639) (665337.9 6525639)
# 4 4 (665315.7 6525242) (665315.7 6525242, 665454.2 6525178) (665454.2 6525178)
# 5 5 (664601 6525464) (664601 6525464, 665317.8 6525700) (665317.8 6525700)
# 6 6 (665320.7 6525600) (665320.7 6525600, 665348.4 6525615) (665348.4 6525615)
# 7 7 (664316.2 6525065) (664316.2 6525065, 664069.9 6524591) (664069.9 6524591)
# 8 8 (665204 6526025) (665204 6526025, 665367.7 6526036) (665367.7 6526036)
# 9 9 (664319.8 6524335) (664319.8 6524335, 664354.4 6524390) (664354.4 6524390)
# 10 10 (664101.7 6525830) (664101.7 6525830, 665309 6525745) (665309 6525745)
# # ... with 90 more rows
# and have a look at a figure
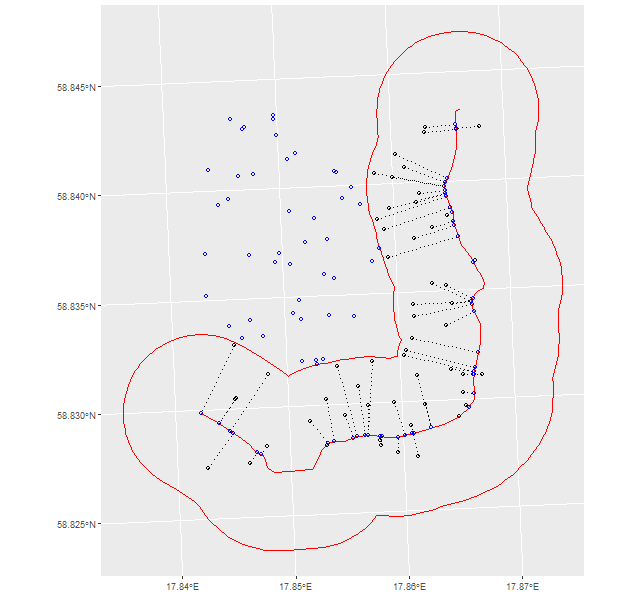
ggplot()+
geom_sf(data = roads, col = 'red')+
geom_sf(data = my_points, shape = 1)+
geom_sf(data = closest_points$my_linestring, linetype = 'dotted')+
geom_sf(data = closest_points$closest_point, shape = 1, col = 'blue')
![enter image description here]()
If you want to include a distance threshold in the analysis, we calculate the distance between the points (or length of my_linestring), and create a new geometry column, conditionally containing either the original geometry or the new snapped point, depending on distance (see here). We use ifelse() and a threshold of 400 m.
# now, use the closest_point if the distance is within a threshold, otherwise keep the original point
closest_points %>%
mutate(
distance = st_distance(geometry, roads)[,1],
distance2 = st_length(my_linestring), # not used, demo purposes only
snapped_point_cond = st_sfc(ifelse(as.numeric(distance) <= 400, st_geometry(closest_point), geometry), crs = st_crs(roads))
) %>%
{. ->> closest_points_threshold}
closest_points_threshold
# Simple feature collection with 100 features and 3 fields
# Active geometry column: geometry
# Geometry type: POINT
# Dimension: XY
# Bounding box: xmin: 664090.7 ymin: 6524310 xmax: 665500.6 ymax: 6526107
# Projected CRS: WGS 84 / UTM zone 33N
# # A tibble: 100 x 7
# id geometry my_linestring closest_point distance distance2 snapped_point_cond
# * <int> <POINT [m]> <LINESTRING [m]> <POINT [m]> [m] [m] <POINT [m]>
# 1 1 (664834.1 6525742) (664834.1 6525742, 665309 6525745) (665309 6525745) 475. 475. (664834.1 6525742)
# 2 2 (665176.8 6524370) (665176.8 6524370, 665142.8 6524486) (665142.8 6524486) 121. 121. (665142.8 6524486)
# 3 3 (664999.9 6525528) (664999.9 6525528, 665337.9 6525639) (665337.9 6525639) 356. 356. (665337.9 6525639)
# 4 4 (665315.7 6525242) (665315.7 6525242, 665454.2 6525178) (665454.2 6525178) 153. 153. (665454.2 6525178)
# 5 5 (664601 6525464) (664601 6525464, 665317.8 6525700) (665317.8 6525700) 755. 755. (664601 6525464)
# 6 6 (665320.7 6525600) (665320.7 6525600, 665348.4 6525615) (665348.4 6525615) 31.2 31.2 (665348.4 6525615)
# 7 7 (664316.2 6525065) (664316.2 6525065, 664069.9 6524591) (664069.9 6524591) 534. 534. (664316.2 6525065)
# 8 8 (665204 6526025) (665204 6526025, 665367.7 6526036) (665367.7 6526036) 164. 164. (665367.7 6526036)
# 9 9 (664319.8 6524335) (664319.8 6524335, 664354.4 6524390) (664354.4 6524390) 64.5 64.5 (664354.4 6524390)
# 10 10 (664101.7 6525830) (664101.7 6525830, 665309 6525745) (665309 6525745) 1210. 1210. (664101.7 6525830)
# # ... with 90 more rows
# and plot it
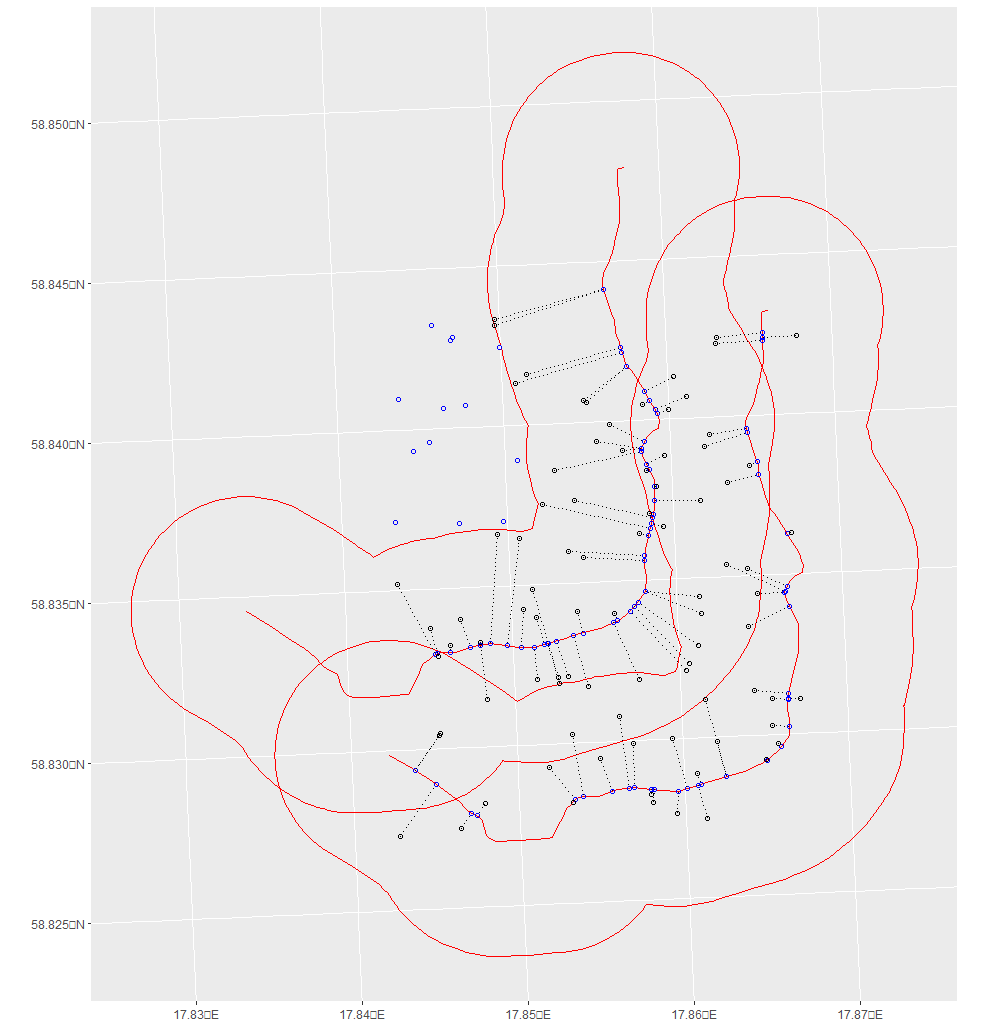
ggplot()+
geom_sf(data = roads %>% st_buffer(400), col = 'red', fill = NA)+
geom_sf(data = roads, col = 'red')+
geom_sf(data = closest_points_threshold$snapped_point_cond, shape = 1, col = 'blue')+
geom_sf(data = closest_points_threshold %>% filter(as.numeric(distance) <= 400) %>% .$my_linestring, linetype = 'dotted')+
geom_sf(data = closest_points_threshold %>% filter(as.numeric(distance) <= 400), shape = 1)
![enter image description here]()
So, blue points are the final threshold-snapped points. As we can see, points outside the 400 m buffer (red polygon) remain in their original position and anything inside (black points and dotted lines) is snapped to the road.
Comparing st_nearest_points() to @TimSalabim's st_snap_points()
Time-wise, the st_nearest_points() method seems to be faster than st_snap_points(). As far as I can gather (and this is not my strong suit), this is because st_snap_points() works on a point-by-point basis, or row-by-row basis when used on an sf collection, whereas we are able to work on the entire collection of LINESTRINGs at once using st_nearest_points().
For the example of 100 points, we are talking <0.2 secs vs ~11 secs.
Additionally, if we try a point-by-point (rowwise()) approach to st_nearest_points(), it is the slowest of all three approaches, coming it at ~15 secs.
#~~~~~ st_nearest_points() ~~~~~
system.time(
my_points %>%
mutate(
my_linestring = st_nearest_points(geometry, roads),
closest_point = st_cast(my_linestring, 'POINT')[seq(2, nrow(.)*2, 2)],
distance = st_distance(geometry, roads)[,1],
snapped_point_cond = st_sfc(ifelse(as.numeric(distance) <= 400, st_geometry(closest_point), geometry), crs = st_crs(roads))
) %>%
{. ->> closest_points_f1}
)
# <0.2 secs
#~~~~~ st_snap_points() ~~~~~
st_snap_points = function(x, y, max_dist = 1000) {
if (inherits(x, "sf")) n = nrow(x)
if (inherits(x, "sfc")) n = length(x)
out = do.call(c,
lapply(seq(n), function(i) {
nrst = st_nearest_points(st_geometry(x)[i], y)
nrst_len = st_length(nrst)
nrst_mn = which.min(nrst_len)
if (as.vector(nrst_len[nrst_mn]) > max_dist) return(st_geometry(x)[i])
return(st_cast(nrst[nrst_mn], "POINT")[2])
})
)
return(out)
}
system.time(
st_snap_points(my_points, roads, max_dist = 400) %>%
{. ->> closest_points_f2}
)
# 11 secs
#~~~~~ st_nearest_points() rowwise ~~~~~
system.time(
my_points %>%
rowwise %>%
mutate(
my_linestring = st_nearest_points(geometry, roads),
closest_point = st_cast(my_linestring, 'POINT')[2], # pull out the second point of each row
distance = st_distance(geometry, roads)[,1],
snapped_point_cond = st_sfc(ifelse(as.numeric(distance) <= 400, st_geometry(closest_point), geometry), crs = st_crs(roads))
) %>%
{. ->> closest_points_f1_rowwise}
)
# 15 secs
All three methods produce the same final figure:
ggplot()+
geom_sf(data = roads, col = 'red')+
geom_sf(data = closest_points_f1$snapped_point_cond, shape = 1, col = 'blue')
![enter image description here]()
However, the st_nearest_points() method(s) returns an sf collection with all the working out columns, whereas st_snap_points() only produces the final snapped points. I reckon having all the original and working columns is pretty useful, especially for troubleshooting. Plus, this method is significantly faster.
closest_points_f1
# Simple feature collection with 100 features and 2 fields
# Active geometry column: geometry
# Geometry type: POINT
# Dimension: XY
# Bounding box: xmin: 664090.7 ymin: 6524310 xmax: 665500.6 ymax: 6526107
# Projected CRS: WGS 84 / UTM zone 33N
# # A tibble: 100 x 6
# id geometry my_linestring closest_point distance snapped_point_cond
# * <int> <POINT [m]> <LINESTRING [m]> <POINT [m]> [m] <POINT [m]>
# 1 1 (664834.1 6525742) (664834.1 6525742, 665309 6525745) (665309 6525745) 475. (664834.1 6525742)
# 2 2 (665176.8 6524370) (665176.8 6524370, 665142.8 6524486) (665142.8 6524486) 121. (665142.8 6524486)
# 3 3 (664999.9 6525528) (664999.9 6525528, 665337.9 6525639) (665337.9 6525639) 356. (665337.9 6525639)
# 4 4 (665315.7 6525242) (665315.7 6525242, 665454.2 6525178) (665454.2 6525178) 153. (665454.2 6525178)
# 5 5 (664601 6525464) (664601 6525464, 665317.8 6525700) (665317.8 6525700) 755. (664601 6525464)
# 6 6 (665320.7 6525600) (665320.7 6525600, 665348.4 6525615) (665348.4 6525615) 31.2 (665348.4 6525615)
# 7 7 (664316.2 6525065) (664316.2 6525065, 664069.9 6524591) (664069.9 6524591) 534. (664316.2 6525065)
# 8 8 (665204 6526025) (665204 6526025, 665367.7 6526036) (665367.7 6526036) 164. (665367.7 6526036)
# 9 9 (664319.8 6524335) (664319.8 6524335, 664354.4 6524390) (664354.4 6524390) 64.5 (664354.4 6524390)
# 10 10 (664101.7 6525830) (664101.7 6525830, 665309 6525745) (665309 6525745) 1210. (664101.7 6525830)
# # ... with 90 more rows
closest_points_f2
# Geometry set for 100 features
# Geometry type: POINT
# Dimension: XY
# Bounding box: xmin: 664069.9 ymin: 6524380 xmax: 665480.3 ymax: 6526107
# Projected CRS: WGS 84 / UTM zone 33N
# First 5 geometries:
# POINT (664834.1 6525742)
# POINT (665142.8 6524486)
# POINT (665337.9 6525639)
# POINT (665454.2 6525178)
# POINT (664601 6525464)
I ran the example again with 1000 points, and st_neareast_points() took ~0.31 secs (1.5x longer), and st_snap_points() took 120 secs (~10x longer). I also ran st_nearest_points() on 10,000 points and it took ~2.5 secs (12x longer than 100 points; 8x longer than 1000 points). I did not run st_snap_points() on 10,000 rows.






{kind=link}
{kind=link}
{kind=link}
toleranceattribute to set a maximum distance. – Roulers