Short answer - We need MapReduce when we need very deep level and fine grained control on the way we want to process our data. Sometimes, it is not very convenient to express what we need exactly in terms of Pig and Hive queries.
It should not be totally impossible to do, what you can using MapReduce, through Pig or Hive. With the level of flexibility provided by Pig and Hive you can somehow manage to achieve your goal, but it might be not that smooth. You could write UDFs or do something and achieve that.
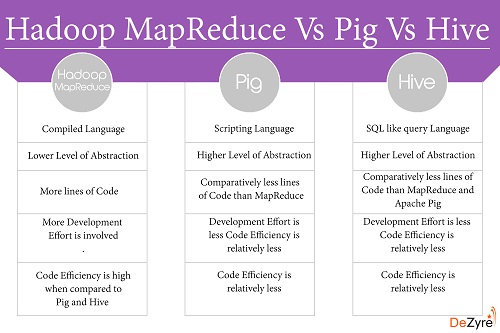
There is no clear distinction as such among the usage of these tools. It totally depends on your particular use-case. Based on your data and the kind of processing you need to decide which tool fits into your requirements better.
Edit :
Sometime ago I had a use case wherein I had to collect seismic data and run some analytics on it. The format of the files holding this data was somewhat weird. Some part of the data was EBCDIC encoded, while rest of the data was in binary format. It was basically a flat binary file with no delimiters like\n or something. I had a tough time finding some way to process these files using Pig or Hive. As a result I had to settle down with MR. Initially it took time, but gradually it became smoother as MR is really swift once you have the basic template ready with you.
So, like I said earlier it basically depends on your use case. For example, iterating over each record of your dataset is really easy in Pig(just a foreach), but what if you need foreach n?? So, when you need "that" level of control over the way you need to process your data, MR is more suitable.
Another situation might be when you data is hierarchical rather than row-based or if your data is highly unstructured.
Metapatterns problem involving job chaining and job merging are easier to solve using MR directly rather than using Pig/Hive.
And sometimes it is very very convenient to accomplish a particular task using some xyz tool as compared to do it using Pig/hive. IMHO, MR turns out to be better in such situations as well. For example if you need to do some statistical analyses on your BigData, R used with Hadoop streaming is probably the best option to go with.
HTH