- Goal: Read from Kinesis and store data in to S3 in Parquet format via spark streaming.
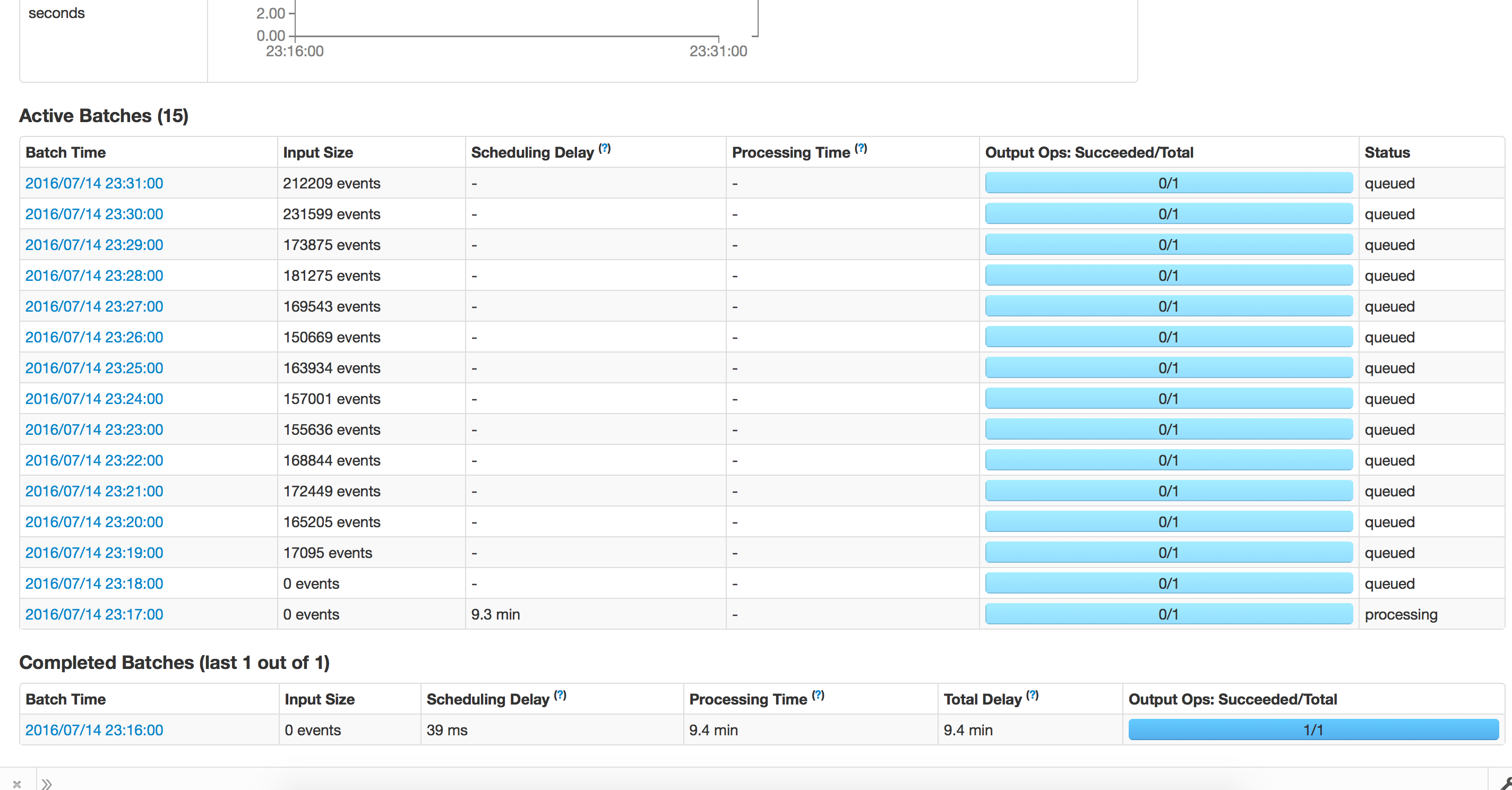
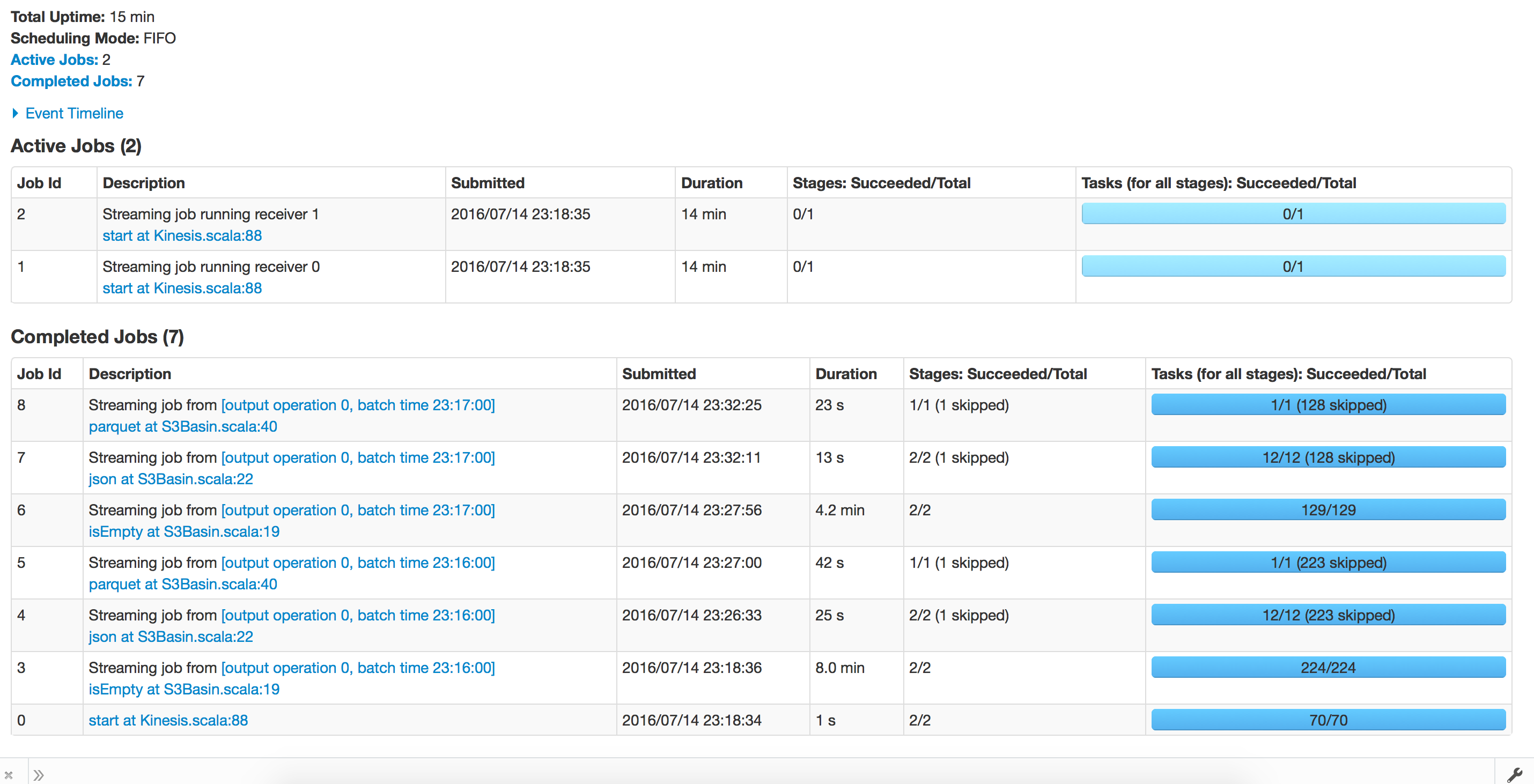
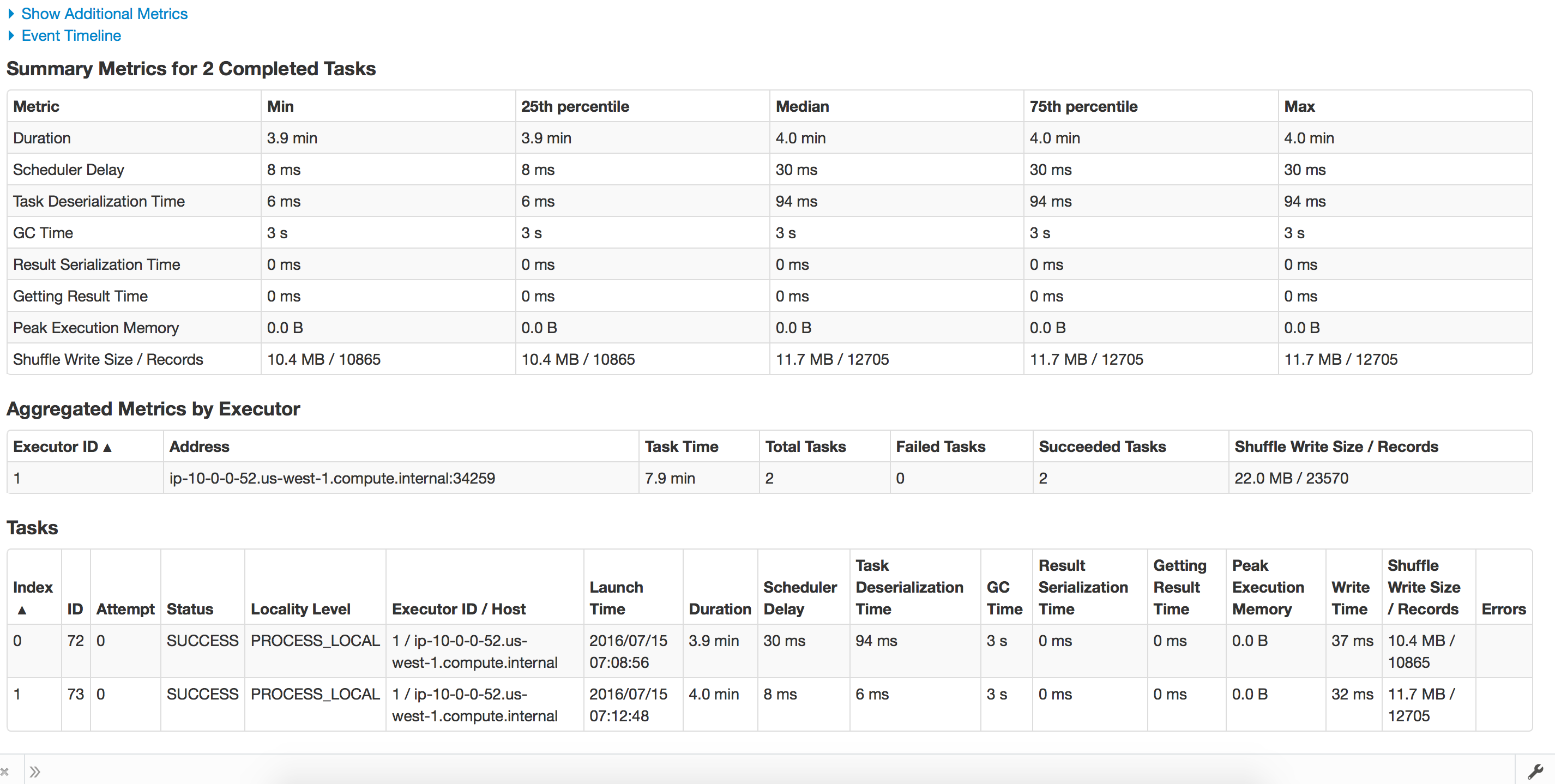
- Situation: Application runs fine initially, running batches of 1hour and the processing time is less than 30 minutes on average. For some reason lets say the application crashes, and we try to restart from checkpoint. The processing now takes forever and does not move forward. We tried to test out the same thing at batch interval of 1 minute, the processing runs fine and takes 1.2 minutes for batch to finish. When we recover from checkpoint it takes about 15 minutes for each batch.
- Notes: we are using s3 for checkpoints using 1 executor, with 19g mem & 3 cores per executor
Attaching the screenshots:
First Run - Before checkpoint Recovery
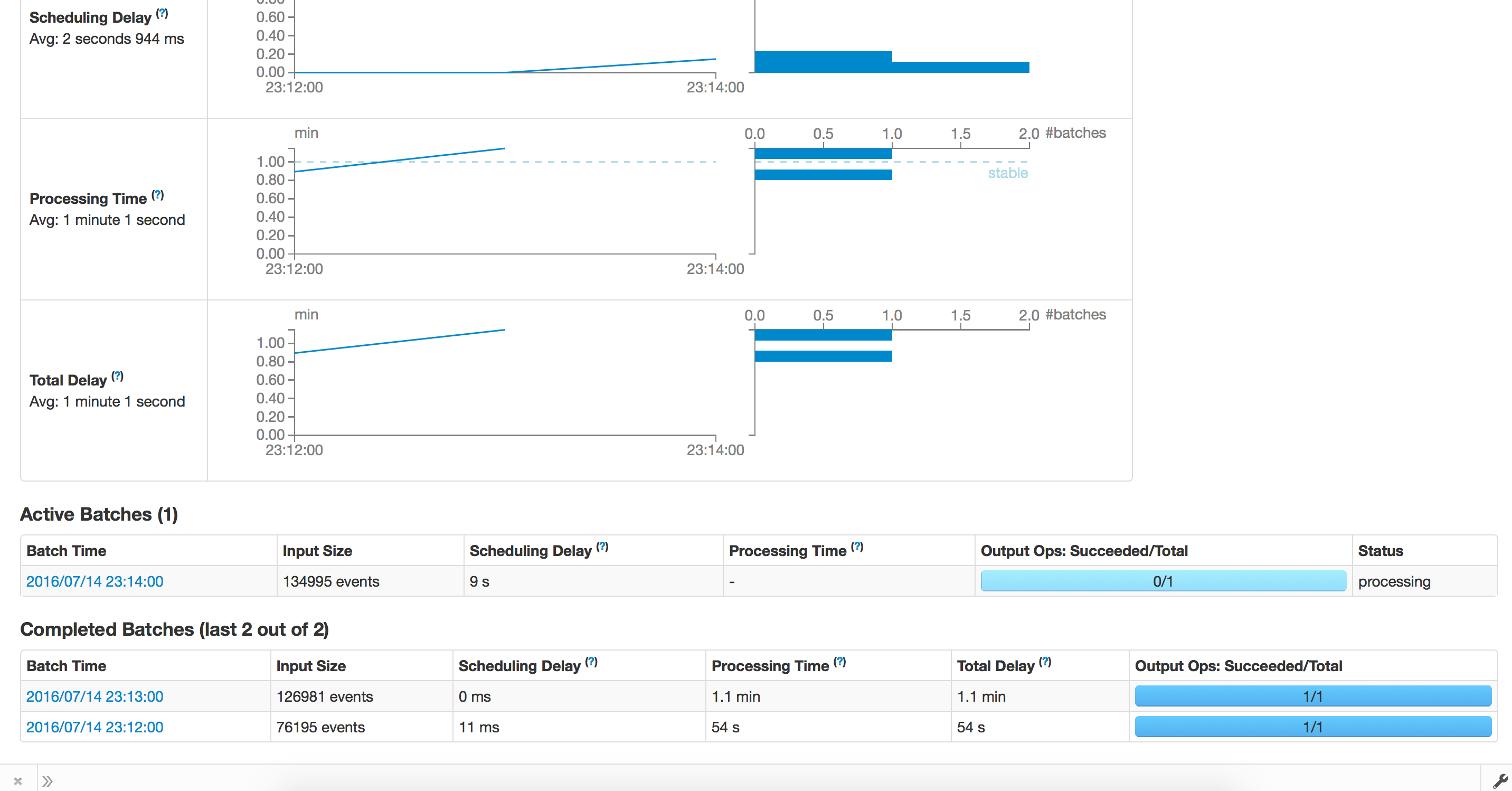
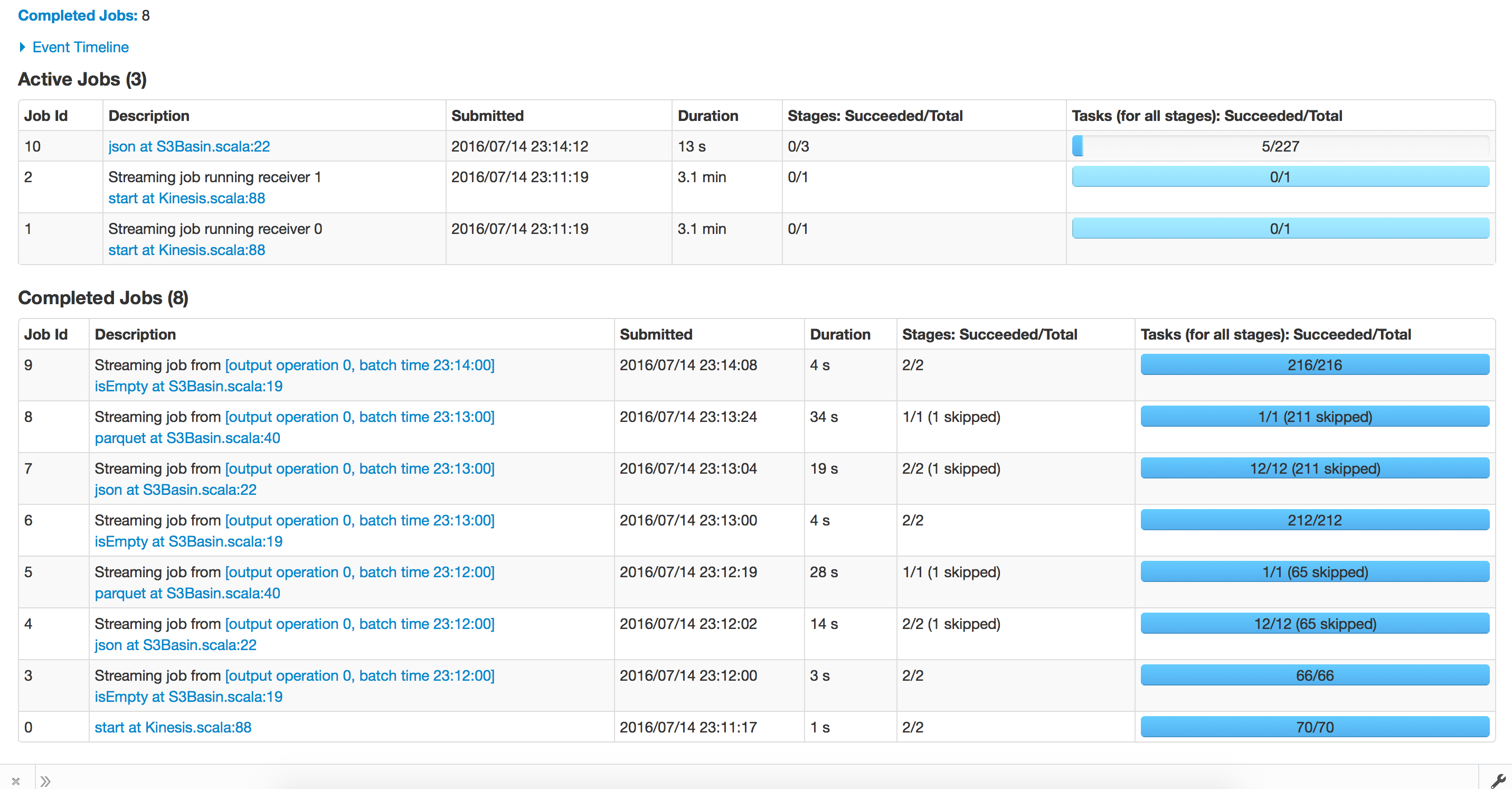
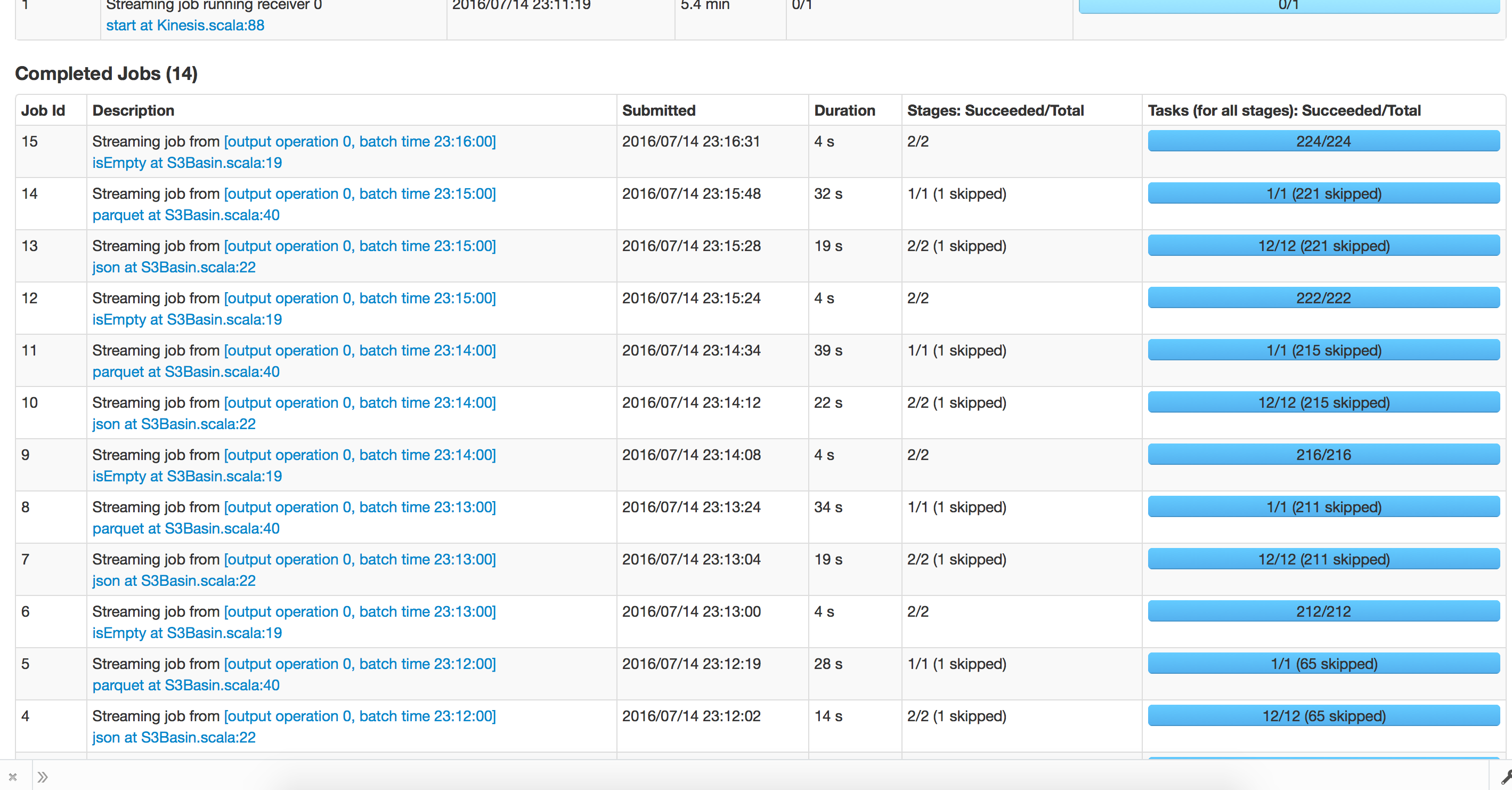
Trying to Recover from checkpoint:
Config.scala
object Config {
val sparkConf = new SparkConf
val sc = new SparkContext(sparkConf)
val sqlContext = new HiveContext(sc)
val eventsS3Path = sc.hadoopConfiguration.get("eventsS3Path")
val useIAMInstanceRole = sc.hadoopConfiguration.getBoolean("useIAMInstanceRole",true)
val checkpointDirectory = sc.hadoopConfiguration.get("checkpointDirectory")
// sc.hadoopConfiguration.set("spark.sql.parquet.output.committer.class","org.apache.spark.sql.parquet.DirectParquetOutputCommitter")
DateTimeZone.setDefault(DateTimeZone.forID("America/Los_Angeles"))
val numStreams = 2
def getSparkContext(): SparkContext = {
this.sc
}
def getSqlContext(): HiveContext = {
this.sqlContext
}
}
S3Basin.scala
object S3Basin {
def main(args: Array[String]): Unit = {
Kinesis.startStreaming(s3basinFunction _)
}
def s3basinFunction(streams : DStream[Array[Byte]]): Unit ={
streams.foreachRDD(jsonRDDRaw =>{
println(s"Old partitions ${jsonRDDRaw.partitions.length}")
val jsonRDD = jsonRDDRaw.coalesce(10,true)
println(s"New partitions ${jsonRDD.partitions.length}")
if(!jsonRDD.isEmpty()){
val sqlContext = SQLContext.getOrCreate(jsonRDD.context)
sqlContext.read.json(jsonRDD.map(f=>{
val str = new String(f)
if(str.startsWith("{\"message\"")){
str.substring(11,str.indexOf("@version")-2)
}
else{
str
}
})).registerTempTable("events")
sqlContext.sql(
"""
|select
|to_date(from_utc_timestamp(from_unixtime(at), 'US/Pacific')) as event_date,
|hour(from_utc_timestamp(from_unixtime(at), 'US/Pacific')) as event_hour,
|*
|from events
""".stripMargin).coalesce(1).write.mode(SaveMode.Append).partitionBy("event_date", "event_hour","verb").parquet(Config.eventsS3Path)
sqlContext.dropTempTable("events")
}
})
}
}
Kinesis.scala
object Kinesis{
def functionToCreateContext(streamFunc: (DStream[Array[Byte]]) => Unit): StreamingContext = {
val streamingContext = new StreamingContext(Config.sc, Minutes(Config.sc.hadoopConfiguration.getInt("kinesis.StreamingBatchDuration",1))) // new context
streamingContext.checkpoint(Config.checkpointDirectory) // set checkpoint directory
val sc = Config.getSparkContext
var awsCredentails : BasicAWSCredentials = null
val kinesisClient = if(Config.useIAMInstanceRole){
new AmazonKinesisClient()
}
else{
awsCredentails = new BasicAWSCredentials(sc.hadoopConfiguration.get("kinesis.awsAccessKeyId"),sc.hadoopConfiguration.get("kinesis.awsSecretAccessKey"))
new AmazonKinesisClient(awsCredentails)
}
val endpointUrl = sc.hadoopConfiguration.get("kinesis.endpointUrl")
val appName = sc.hadoopConfiguration.get("kinesis.appName")
val streamName = sc.hadoopConfiguration.get("kinesis.streamName")
kinesisClient.setEndpoint(endpointUrl)
val numShards = kinesisClient.describeStream(streamName).getStreamDescription().getShards().size
val batchInterval = Minutes(sc.hadoopConfiguration.getInt("kinesis.StreamingBatchDuration",1))
// Kinesis checkpoint interval is the interval at which the DynamoDB is updated with information
// on sequence number of records that have been received. Same as batchInterval for this
// example.
val kinesisCheckpointInterval = batchInterval
// Get the region name from the endpoint URL to save Kinesis Client Library metadata in
// DynamoDB of the same region as the Kinesis stream
val regionName = sc.hadoopConfiguration.get("kinesis.regionName")
val kinesisStreams = (0 until Config.numStreams).map { i =>
println(s"creating stream for $i")
if(Config.useIAMInstanceRole){
KinesisUtils.createStream(streamingContext, appName, streamName, endpointUrl, regionName,
InitialPositionInStream.TRIM_HORIZON, kinesisCheckpointInterval, StorageLevel.MEMORY_AND_DISK_2)
}else{
KinesisUtils.createStream(streamingContext, appName, streamName, endpointUrl, regionName,
InitialPositionInStream.TRIM_HORIZON, kinesisCheckpointInterval, StorageLevel.MEMORY_AND_DISK_2,awsCredentails.getAWSAccessKeyId,awsCredentails.getAWSSecretKey)
}
}
val unionStreams = streamingContext.union(kinesisStreams)
streamFunc(unionStreams)
streamingContext
}
def startStreaming(streamFunc: (DStream[Array[Byte]]) => Unit) = {
val sc = Config.getSparkContext
if(sc.defaultParallelism < Config.numStreams+1){
throw new Exception(s"Number of shards = ${Config.numStreams} , number of processor = ${sc.defaultParallelism}")
}
val streamingContext = StreamingContext.getOrCreate(Config.checkpointDirectory, () => functionToCreateContext(streamFunc))
// sys.ShutdownHookThread {
// println("Gracefully stopping Spark Streaming Application")
// streamingContext.stop(true, true)
// println("Application stopped greacefully")
// }
//
streamingContext.start()
streamingContext.awaitTermination()
}
}
DAG
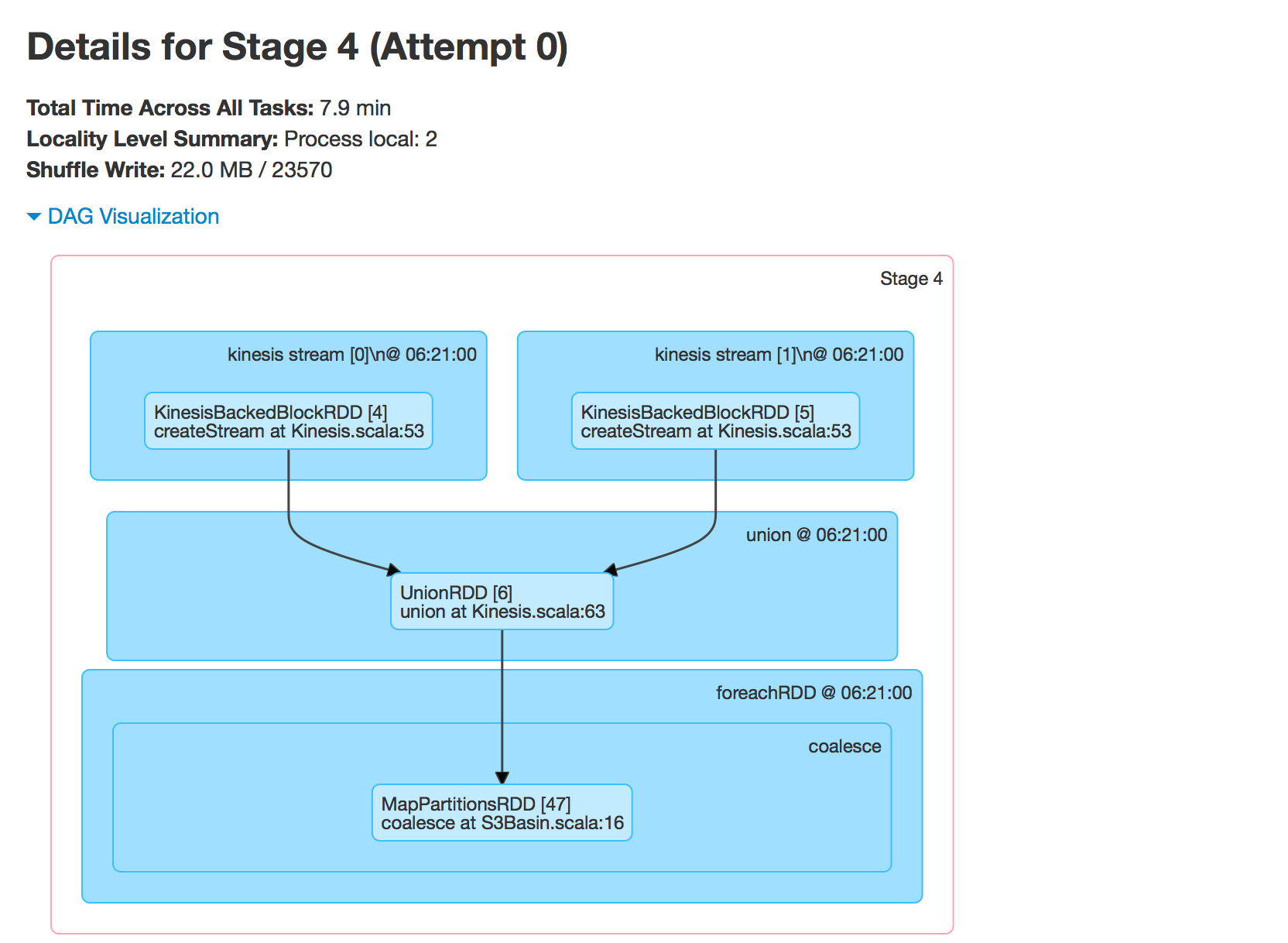
isEmpty? its there as part ofS3Basin.scalaif(!jsonRDD.isEmpty()){...– Petroleum