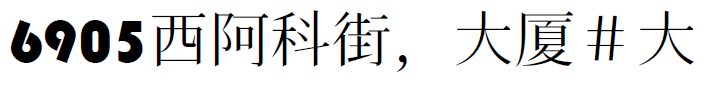TL;DR: Is there some way of telling ReportLab to use a specific font, and fallback to another if glyphs for some characters are missing? Alternatively, Do you know of a condensed TrueType font which contains the glyphs for all European languages, Hebrew, Russian, Chinese, Japanese and Arabic?
I've been creating reports with ReportLab, and have encountered problems with rendering strings containing Chinese characters. The font I've been using is DejaVu Sans Condensed, which does not contain the glyphs for Chinese (however, it does contain Cyrillic, Hebrew, Arabic and all sorts of Umlauts for European language support - which makes it pretty versatile, and I need them all from time to time)
Chinese, however, is not supported with the font, and I've not been able to find a TrueType font which supports ALL languages, and meets our graphic design requirements. As a temporary workaround, I made it so that reports for Chinese customers use an entirely different font, containing only English and Chinese glyphs, hoping that characters in other languages won't be present in the strings. However this is, for obvious reasons, clunky and breaks the graphic design, since it's not DejaVu Sans, around which the whole look&feel has been designed.
So the question is, how would you deal with the need to support multiple languages in one document, and maintain usage of a specified font for each language. This is made more complicated due to the fact that sometimes strings contain a mix of languages, so determining which ONE font should be used for each string is not an option.
Is there some way of telling ReportLab to use a specific font, and fallback to another if glyphs for some characters are missing? I found vague hints in the docs that it should be possible, although I might understand it incorrectly.
Alternatively, Do you know of a condensed TrueType font which contains the glyphs for all European languages, Hebrew, Russian, Chinese, Japanese and Arabic?
Thanks.