I have a Firehose stream that is intended to ingest millions of events from different sources and of different event-types. The stream should deliver all data to one S3 bucket as a store of raw\unaltered data.
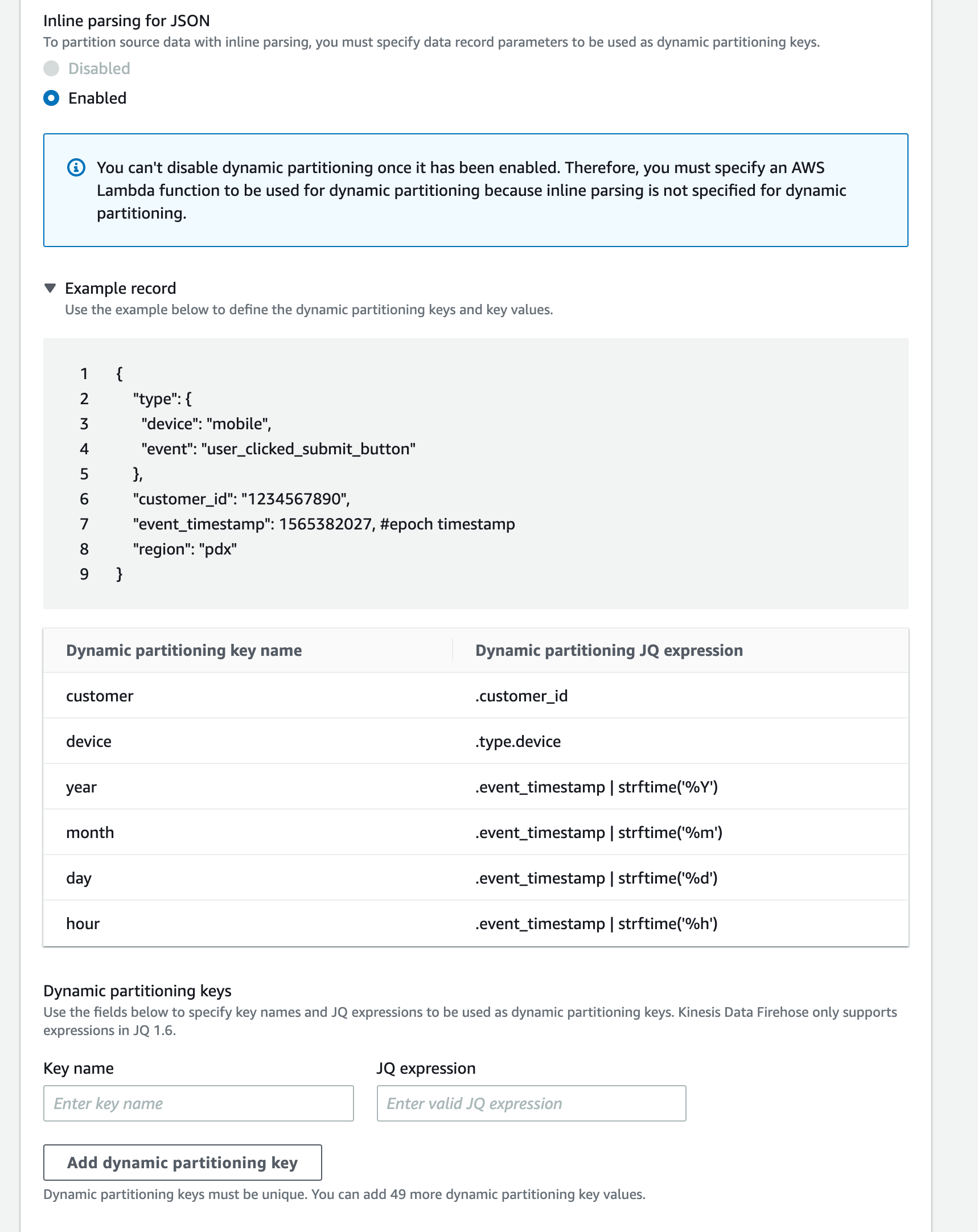
I was thinking of partitioning this data in S3 based on metadata embedded within the event message like event-souce, event-type and event-date.
However, Firehose follows its default partitioning based on record arrival time. Is it possible to customize this partitioning behavior to fit my needs?
Update: Accepted answer updated as a new answer suggests the feature is available as of Sep 2021